Manchmal möchte man aus einem Tomcat heraus Processe und Programme aufrufen. Wie bei SQL-Injections muss man das natürlich stark absichern, aber das Konvertieren von Bildern und Video geschieht meistens auf diese Art und Weise.
Was aber wenn der Tomcat per ProcessBuilder nichts mehr aufrufen kann außerhalb seines Verzeichnisses, obwohl er alle Recht haben sollte? Wenn es ein System mit systemd ist (z.B. ein Ubuntu) ist, kann es einfach eine Security-Einstellung sein, die den Aufruf verhindert.
Hier muss man die Start-Config für den Service anpassen. "ProtectSystem=false" ist zum Prüfen der Lösung ganz gut, sollte aber später durch eine genauere Anpassung der ReadWritePaths geöst werden.
An sich ist es garnicht sooo schwer Nuxeo mit einem Keycloak zu verbinden und dann die Benutzerverwaltung allein über das Keycloak abzuwinkeln. Leider ist die Dokumentation dazu sehr dürftig und zu großen Teilen einfach veraltet und lückenhaft. Hier wird einmal in kurzer Form erklärt wie man das mit einer aktuellen Version von Nuxeo 10.10 bewerkstelligen kann. Man sollte das 10.10 Repository von Github einmal per Maven komplett selbst gebaut haben. Wir hatten die HF53-Version und ein Grundsetup als Docker-Image ist unter annonyme/nuxeo:HF53 zu finden. Besser ist aber wenn man sich das vollständig selbst baut. Das Docker-Repository hilft beim Bauen.
Die Erweiterung für Nuxeo
Das Repository für die Nuxeo Platform Login Keycloak Erweiterung ist Teil des Nuxeo Mono-Repository und kann direkt mitgebaut werden. Die Anleitung dazu ist vollkommen veraltet, aber ich nehme sie hier als Basis. Man braucht um dieses benutzen zu können:
Die Dateien aus der Zip der Adapter-Dist, die JAR vom Nuxeo Platform Login Keycloak sowie die JAR des UserMapper Services müssen alle in das selbe plugin/ Verzeichnis kopiert werden wie in der Anleitung erklärt wird. Das config/ Verzeichnis wie im Repository einfach auch rüber kopieren. Der Inhalt der JSON-Datei kann direkt aus dem Nuxeo kopiert werden und
ist die Config-Datei für den Keycloak Tomcat-Adapter und hat also an sich nichts mit Nuxeo zu tun. Dem entsprechend ist die Dokumentation zu der Datei auch um Welten besser als bei den Nuxeo Komponenten.
In der Anleitung wird alles in ein Template-Verzeichnis kopiert. Ein Template ist ein Profile für verschiedene Nuxeo-Konfigurationen und es können mehrere davon gleichzeitig verwendet werden. Den Docker-Container muss man dann also mit NUXEO_TEMPLATES: docker,keycloak starten.
Das war es dan nauch. Beim Login in Nuxeo einfach einen Account aus dem Keycloak verwenden und der Benutzer sie wie die im Keycloak zugeordneten Rollen/Gruppen werden ins Nuxeo übernommen.
Wenn man nochmal mit dem Administrator-Konto ins Nuxeo will und dieser noch nicht im Keycloak angelegt ist, muss man nur direkt /nuxeo/login.jsp aufrufen und bekommt die Nuxeo-Anmeldung ohne auf die Realm-Anmeldeseite des Keycloak weiter geleitet zu werden.
Es sind keine weiteren Konfigurationen an Nuxeo nötig. Wenn man sich ein Docker-Image baut muss also nur die keycloak.json aus dem config-Verzeichnis des Templates ersetzt werden können.
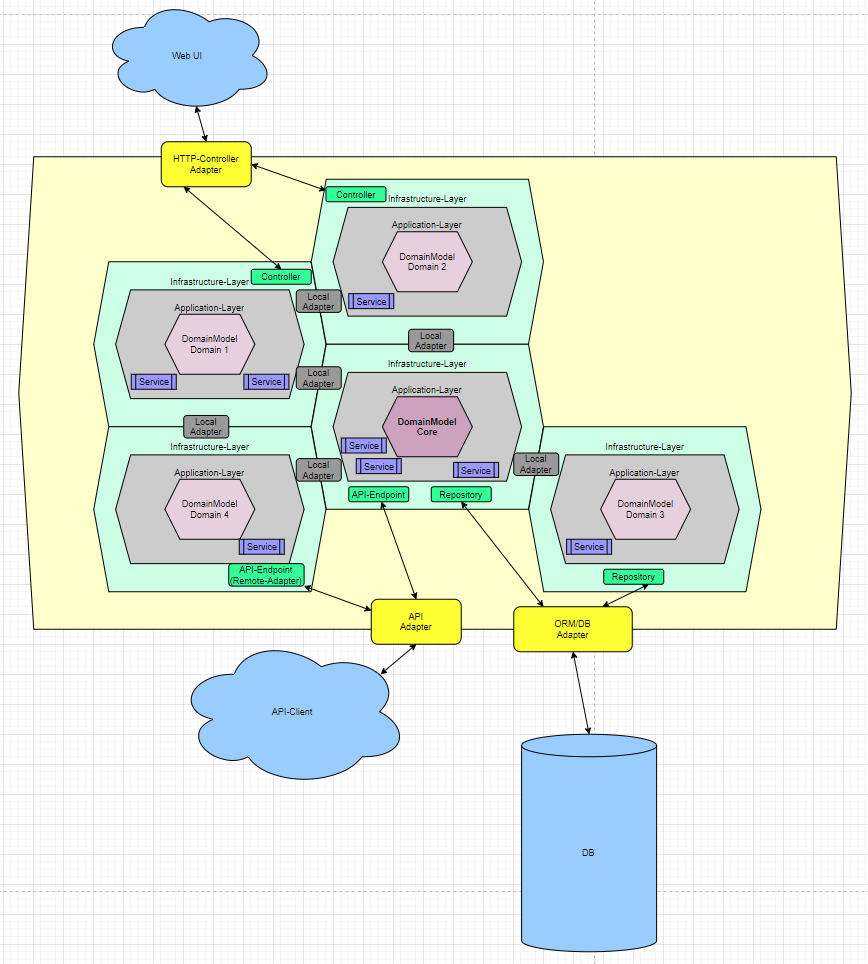
Ich hatte eine sehr genaue und von Java geprägte Vorstellung von Ports und Adaptern. Im Tomcat z.B. der HTTP-Port und dann als Adapter HTTP-NIO als Implementierung des Ports. Dann wurde diskutiert und irgendwie hatten alle andere Ansichten was ein Port und ein Adapter sind. Nachdem dann Ports da waren, aber keine Adapter mehr und Ports irgendwie nur noch deren wegen da waren, haben ich mich diesen Sonntag mal hingesetzt und angefangen im Netz zu lesen.
Erst landete ich bei eine Artikel über Ports und Adapter mit Symfony und ich fühlte mich verstanden. Dann kam der die Interpretation nutze und sogar das Repository als Adapter und sein Interface als Port sieht (was an sich ja genau richtig ist). Also mein Verständnis entspricht dem auf Baeldung.com beschriebenen Grundgedanken einer Logic die zwischen nicht kompatiblen Interfaces vermitteln. Zumeist ist eines der Interfaces, das der eigenen Anwendung und das andere das einer 3rd Party Lib.
Also wäre an sich auch JPA ein Port. Es beschreibt ein allgemein gültiges Interface zur Persitierung und die verschiedenen Frameworks wie Hibernate oder EclipseLink liefern Adapter die JPA auf die nativen Interfaces adaptiert.
Dadurch definieren sich schon mal ein paar Dinge: - es kann keinen Port ohne Adapter geben
- Ein Adapter ist nötig, wenn das Interface nicht mit der eigenen Anwendung kompatible ist
Im Grunde sind wir hier wieder beim klassischen Factory-Patten. Ein allgemeines Interface, viele Implementierung und eine Instanz die entscheidet welche Implementierung gerade die passende ist. Nebenbei in Unit-Tests sehr praktisch.
Wann brauche ich keinen Port: - Wenn eine Lib schon ein allgemeines Interface bereit stellt
- z.B. was bei den meisten Email-Libs so ist... weil die Änderung der Implementierung oft nur Konfiguration ist
- etwas allgemeines noch mal zu Kapsel macht wenig Sinn
- Ein Adapter für nur eine mögliche Implementierung macht genau so wenig Sinn
Ein sehr fachliches Beispiel wäre das Pushen einer Bestellung an verschiedene Drop-Shipper. Jeder hat ein anderes WWS, ERP oder Shop-System. Man definiert für die Clients ein einheitliches Interfac, was mit den eigenen Klassen (bzw. deren Interfaces) arbeitet. Für jedes System wird ein eigener Client geschrieben und Abhängig vom Drop-Shipper und seinen Systemdaten wird eine Factory die passende Implementierung wählen und konfigurieren.
Also... Ports und Adapter ist kein Konzept, dass man groß erzwingen muss, es ergibt sich zwangsmäßig und von alleine (wenn man nur minimal strukturiert entwickelt).
PS:
Wenn man mehr als eine Domain hat, definiert natürlich nur eine Domain das Interface und stellt die Verwendung den anderen Domainen per UseCase zur Verfügung.
Ich nenne diese Struktur DDD-Cluster, da es ein Cluster aus mehreren Domains ist, die auch unter einander kommunizieren können und auch die Hexagonale-Architektur abbilden.
Jeder der schon mal in Java eine EJB3-Anwendung mit mehreren Modules gebaut hat, sollte das darin wieder erkennen können und weiß sicher das so ein Diagramm zwar schön sauber aussieht, aber die Realität schnell ganz anders ist. Abhängigkeiten wachsen schnell und schnell gibt es Module die fast alle anderen Module benötigen und schnell zyklische Abhängigkeiten entstehen. So eine Architektur entsteht, wenn man sauber und bewusst arbeitet. Die Anwendung wird nicht sauber und strukturiert, weil es die Theorie so einer Architektur gibt.
Also nichts neues aber mal nett anzugucken. Dann denkt man an die Realität und weiß wieder warum es Microservices gibt.
Gerade wenn man Apps (PWAs) entwickelt, die zwingend HTTPS brauchen, weil man auf Dinge wie die interne Kamera des Geräts zugreifen möchte, kommt man zu dem Problem auch die Middleware mit HTTPS betreiben zu müssen. Kein Browser mag Mixed-Content. Wenn die Middleware mit Spring Boot geschrieben ist, kommt man aber auch da ziemlich schnell und einfach zu einer Lösung.
Das funktioniert sogar ohne komplexe Keystore Aktionen und irgendwelchen Signieren von gebauten Artefakten.
Die einfachste Lösung ist sich ein PKCS#12-Certificate (als das als Datei, PKCS#11 ist das von den Smartcards) zu erzeugen und direkt als Keystore zu nutzen.
Neben dem Alias sollte man auch den Dateinamen der p12-Datei anpassen. Danach muss man viele Daten angeben (die man sonst in openssl in der Conf-Datei ablegen würde). Die p12-Datei kann man nun einfach im resources-Bereich im Default-Package ablegen (bzw. auch in jedem anderen Package, wo es per getResource erreichbar ist).
Danach muss man die Daten nur noch in der application.properties eintragen.
Danach sollte Spring Boot wie vorher auf dem konfigurierten Port starten, aber ab jetzt nur noch per HTTPS erreichbar sein.
Das Certificate ist natürlich nur self-signed und eignet sich nur für Dev-Umgebungen. Bevor die PWA auf die Middleware zu greifen kann, muss man mit dem Browser die Middleware einmal aufrufen und den Zugriff für den Browser erlauben. Danach sollte es dann gehen.
Ich habe mir diesen Artikel durch gelesen, warum man bis 2020 Python lernen sollte. Aber irgendwie überzeugen mich diese Gründe so gar nicht. Ich hab schon mal ein paar Dinge mit Python gemacht und am Ende, war es eine Sprache wie jede andere. Viel weniger Boilerplate-Code als Java, aber dass ist keine Kunst und mit Lombok und ähnlichen hat sich auch bei Java viel getan. Aber mal der Reihe nach:
1. Automatisiert triviale Aufgaben Das kann ich mit PHP (mit Symfony-CLI) auch ganz gut. Kleine Tools schreiben ohne viel Framework wie JRE + Spring + JPA + etc haben zu müssen. Aber sobald der Code Compiler wird, kommt auch da alles hinzu. Ich sehe da eher den Vorteil dass Python auf IoT-Geräten gut läuft und man sehr viel Overhead einsparen kann.
2. Schneller Einstieg und einfache Syntax Stimmt. Das Beispiel ist zwar nicht aussagekräftig da der Boilerplate-Code mit zunehmenden Code immer geringere Anteile einnimmt und man sich viel Code heute ja auch automatisch generieren lassen kann. IDEs sei dank bringt einen diesen Code zu schreiben kaum einen zeitlichen Nachteil. Also... ja.. Python ist nicht schwer, aber auch nicht leichter als PHP oder JavaScript. Java ist an sich auch nicht schwer, man muss nur eben Classes und Packages richtig nutzen und schon ist alles sehr übersichtlich. Je weniger Struktur man braucht desto schwieriger wird es auch für die IDE bei der Codevervollständigung zu helfen. Java ist da einfach immer noch weit vorne.
3. Data Science Geil... wenn ich Python kann, kann ich Data Science? Nein. Irgendwer hat man angefangen Python in dem Bereich zu nutzen und hat gute Libs geschrieben. Oft sind die Libs Ausschlag gebender als die Sprache an sich. Also war es wohl eher Zufall dass in dem Bereich Python hauptsächlich eingesetzt wird und nicht der Sprache an sich geschuldet. Bloss weil ich das Hauptwerkzeug für einen Berufszweig benutzen kann, kann ich auch den Beruf ausüben... ich kann mit einem Skalpell scheiden!!!!
4. Machine Learning Ja.. auch cool. Tolles und komplexes Thema. Werkzeuge dafür zu erlernen ist hier sicher nicht die größte Herausforderung in dem Bereich.
5. Ressourcen Wie oben schon beschrieben. Wenn die Lib mein Problem löst, nehme ich die Sprache für die es die Lib gibt. Da ist es egal ob es Python, Java oder C++ ist. Ich nehme einfach das, was mein Problem schnell und einfach löst. Also bringt es mir nichts Python zu lernen, weil es tolle Libs gibt. Wenn ich eine Lib benutzen will, dann habe ich ein Grund mir die Sprache anzueignen.. vorher nicht (außer aus Spass oder Lerndrang).
6. Community Das gilt an sich für jede größere Programmiersprache. Stackoverflow hilft, deutsche Foren liefern nie eine Lösung. Alles wie immer.
Zusammenfassend kann ich für mich nur sagen. Es lohnt sich für mich nicht eine neue Sprache zu lernen, weil man theoretisch super tolle Dinge damit machen könnte, die ich entweder nicht beherrsche oder nicht benötige. Die Standardaufgaben können alle Sprachen fast gleich gut und da zwischen den Sprachen zu wechseln fällt auch entsprechend leicht. Mal mit einer Sprache rumspielen ist immer lustig und macht Spass, aber eine Sprache wirklich lernen ist nru nötig wenn man es benötigt. IoT-Geräte sehe ich da noch als den wahrscheinlichsten Grund, warum ich mal wieder was mit Python machen sollte.
Jeder Java-Entwickler kennt es. Properties definieren und dann Setter und Getter erzeugen lassen. Wenn man was ändert, wird es nervig und wenn man was hinzufügt, muss man die fehlenden Methoden neu generieren lassen. Das geht an sich immer schnell, ist aber doch immer nervig.
Lombok übernimmt die Erzeugung dieser Methoden zur Compiling-Zeit. Die IDE benötigt ein Plugin und der Rest wird dann über Maven erledigt.
Manchmal ist es echt unpraktisch viele kleine JAR-Dateien zu haben und man hätte gerne alles in einer großen. Keine Class-Path Probleme mehr, einfaches Deployen und ein Single-Point-Of-Failure.
Mit Maven geht das zum Glück sehr einfach. Spring Boot und Meecrowave haben eigene Plugins mit denen man auch sehr gut arbeiten kann und die dem Beispiel hier vorzuziehen sind.
Manchmal soll Logik auf Daten einer Map zugreifen können aber nicht ändern können. Ich habe für meine State-Implementierung Action-Dispatcher eingeführt, die Daten der Action anpassen dürfen und dafür auch Daten aus dem State zum Abgleich nutzen sollen, aber an der Stelle sollen sie nicht die Möglichkeit haben den State selbst zu ändern, weil ich an der Stelle keine Änderungen tracke. Action-Dispatcher sollen schnell und leichtgewichtig sein.
Zum Glück kann man mit Collections sich schnell eine unmodifiable Map erstellen. Was das für die Performance bedeutet habe ich noch nicht getestet, aber ich gehe davon aus, dass das Tracken und Behandeln von Änderungen am State am Ende auf wendiger wäre.
Wer kennt das Problem nicht? Der Java-Appserver ist schon beim hochfahren, während der DB-Server noch Daten importiert und Hibernate fängt an wild Exceptions zu werfen.
Die Lösung ist das Script wait-for-it, das einfach wartet, bis ein Server auf einem bestimmten Port erreichbar ist.
FROM openjdk:12-alpine
RUN apk add --no-cache bash
ADD utils/wait-for-it.sh /wait-for-it.sh
RUN chmod +x /wait-for-it.sh
An sich ist das hier vollkommen logisch und man wundert sich warum man diesen Fehler überhaupt gemacht hat.. weil man den vorher nicht gemacht hat. Deswegen sollte man im Kopf behalten, dass wenn man optionale Parameter im Methodenaufruf im REST-Controller in Spring hat, diese null als Wert haben können müssen.
Einfach gesagt Integer verwenden und nicht int, weil das natürlich Probleme geben würde, wenn Spring null in einen int füllen möchte.
Wer sich sonst immer für Wildfly/Tomcat und JAX-RS für seine REST-API Lösungen entschieden hat wird sich mit Apache Meecrowave sehr schnell zu Hause fühlen. Im Grunde ist es auch nichts anderes als ein Tomcat mit JAX-RS nur dass die Setup-Phase fast komplett entfällt. Für Microservices und schnelle Lösungen hat man in wenigen Minuten eine funktionsfähige REST-API.
Für eine einfache REST-API braucht man die pom.xml, eine Klasse mit einer Main-Methode und einen REST-Endpoint.
@Path("test")
@ApplicationScoped
public class TestController {
@GET
@Produces(MediaType.APPLICATION_JSON)
public TestModel action(){
TestModel model = new TestModel();
model.setId(23);
model.setName("Test");
return model;
}
}
Der Endpoint ist jetzt erreichbar:
http://localhost:8080/test
Der Vorteil bei dieser Lösung ist, dass man sehr einfach ein Docker-Image mit dieser Anwendung erstellen kann, das man dann direkt deployen kann.
Durch das Meecrowave-Maven-Plugin wird eine meecrowave-meecrowave-distribution.zip im Target-Verzeichnis erstellt.
RUN apk --no-cache add bash
EXPOSE 8080
ENTRYPOINT["sh /app/meecrowave.sh start"]
Auch für Test gibt fertige Meecrowave-Packages, die man nutzen kann. Sonst geht natürlich auch einfach JUnit.
Wer sich jetzt fragt ob Spring Boot besser oder schlechter ist.. ich hatte jetzt mit beiden zu tun und am Ende ist beides an sich das Selbe mit ein jeweils anderen Libs. Beides ist für Microservices sehr gut geeignet.
Wenn man mit JavaScript zu tun bekommt, führt leider kein Weg an Selenium vorbei. Das erst einmal zum laufen zu bekommen ist dabei auch nicht immer einfach. Ich habe dabei gelernt, dass Firefox nicht wirklich funktioniert und Chrome dagegen ohne Probleme funktioniert. Um Selenium zum Laufen zu bekommen brauchen wir einiges:
- eine aktuelle Version des Selenium Standalone Servers als JAR
- den Chrome-Driver für Selenium
- Java
dann kann man Selenium mit java -Dwebdriver.chrome.driver=/opt/selenium/chromedriver -jar selenium-server-standalone-X.X.X.jar starten. Den Driver kann man natürlich auch in anderen Verzeichnissen ablegen.
https://selenium-release.storage.googleapis.com/index.html
Um nun auch eigene Methoden wie Warten hinzuzufügen brauchen wir einen eigenen Context. Den legen wir unter features/bootstrap ab.
<?php
class TestContext extends \Behat\MinkExtension\Context\MinkContext {
/**
* @When I wait :arg1 seconds
*/
public function iWaitSeconds($seconds)
{
$this->getSession()->wait($seconds * 1000);
}
/**
* @When I click the :arg1 element accepting the alert
*/
public function iClickTheElementAcceptingTheAlert($selector)
{
$page = $this->getSession()->getPage();
$element = $page->find('css', $selector);
if (empty($element)) {
throw new Exception("No html element found for the selector ('$selector')");
}
Nun können wir Warten und sogar Javascript Dialoge bestätigen.
Wenn wir nun mit "bin/behat features/XXX.feature" unser Test Scenario XXX starten öffnet sich der Chrome-Browser und wir können alle Tests visuell mit verfolgen.
Das Mocking von Services war lange eine sehr komplizierte Sache. Mit Javassist oder speziellen Implementierungen konnte man es lösen, aber es war oft einfach nicht schnell und einfach zu benutzen. Mit Mockito kann man pro Test die Method-Calls einer Klasse überschreiben und so relativ einfach auch Test für Klassen mit Dependency Injection schreiben. Wenn man eine Service-Klasse testen möchte, die auf ein DAO zurückgreift um Daten aus der Datenbank zu laden, kann man nun einfach die DAO-Klasse mit Mockito so manipulieren, dass sie bestimmte Daten liefert ohne auf die Datenbank zu gehen und so hat man die volle Kontrolle über die Input- als auch die Output-Daten.
import static org.mockito.Mockito.*; //to use when() without static class
public class ModelTest {
//will always return a model with id = 0 (not existing), simulating an empty/not existing database
@Mock
private TestModelDAO dao;
@Rule
public MockitoRule mockitoRule = MockitoJUnit.rule();
@Before
public void setup(){
//creating an existing dummy for id 23, so 23 will always return a valid model
TestModel dummy = new TestModel();
dummy.setId(23);
dummy.setName("blubb-23");
when(this.dao.getModel(23)).thenReturn(dummy);
}
@Test
public void getModelSimple(){
TestModel model = (new TestModelDAO()).getModel(42);
Assert.assertEquals(0, model.getId());
}
@Test
public void getModelComplexId(){
TestModel model = this.dao.getModel(23);
Assert.assertEquals(23, model.getId());
}
@Test
public void getModelComplexName(){
TestModel model = this.dao.getModel(23);
Assert.assertEquals("blubb-23", model.getName());
}
@Test
public void getModelDIExample(){
//Testing a service with constructor dependency injection
TestService service = new TestService(this.dao);
String upperName = service.getUpperCaseName(23); //name for id 23
Assert.assertEquals("BLUBB-23", upperName);
}
}
An sich sollte man solche Methoden wie getUpperCaseName nie so schreiben und immer die fertig geladene Entität rein reichen. Aber gerade bei älteren Legacy-Code findet man solche Dinge oft. Auch Tests mit fehlenden Request oder ähnlichen kann man so durchführen, ohne direkt eine gesamte HTTP-Umgebung nachbauen zu müssen.
Ich musste mich damit beschäftigen wie man eine kleine REST-API mit Python erstellt. Django macht dabei an sich bei jeden Pups bei mir Probleme und war doch sehr umständlich, weil man sich noch mit dem gesamten MVC-Pattern darin beschäftigen musste. Nachdem es auch mit dem ORM schwieriger wurde (im Vergleich zu Spring Boot mit JPA/Hibernate) dachte ich mir, es müsse doch auch für Python was modernes geben. So kam ich zu Turbo Gears 2 und das macht schon mal genau was ich wollte. Einfach, schnell und übersichtlich.
from tg import expose, TGController, AppConfig
import jsonpickle
# --
class TestEntity(object):
def __init__(self, id ,name, sub):
self.id = id
self.name = name
self.sub = sub
class TestSubEntity(object):
def __init__(self, value):
self.value = value
# --
class RootController(TGController):
@expose("json")
def index(self):
test = TestEntity(42, 'blubb', TestSubEntity('sub-blubb'))
return jsonpickle.encode(test, unpicklable=False)
print("Serving on port 8090...")
httpd = make_server('', 8090, application)
httpd.serve_forever()
Mit Turbo Gears 2, Spring Boot und Meecrowave kann wirklich schnell und einfach Microservices erstellen und vieles des Overheads alter Zeiten ist einfach nicht mehr da bzw wurde so gut versteckt, dass man sich rein auf den Code und die Logik konzentrieren kann. Welche Lösung man da nimmt ist Geschmackssache. Von der Codestruktur her sieht alles an sich fast 100% gleich aus.
Bei Python sehen Flask, Bottle und Hug auch interessant aus
Ich mag PHP. Ich mochte PHP schon zu PHP4- und PHP5-Zeiten, obwohl da Performance und Typisierung wirklich nicht immer so toll waren. Aber es gab einen großen Vorteil, im Vergleich zu Java (Tomcat + JSP/JSF/Servlets), den man konnte einfach eine Datei ändern und F5 drücken. Dann war die Änderung direkt zu sehen. Das Betraf auch nciht nur einfache Controller und Views sondern auch DB-Connections, Caches und andere Dinge bei denen man normaler Weise den Java Servlet-Controller hätte neustarten müssen. Dieser Luxus wurde sich eben dadurch erkauft, das es keinen Application-Scope oder komplexes Connection-Pooling in PHP gab. Aber dafür ersparte man sich nicht-funktionierende Hot-Deploys und Restart-Zeiten der Serverumgebung.
Nun soll es einen PHP Preload-Cache geben, wobei die Kompilierung des PHP-Codes nur noch beim Serverstart erfolgen soll: A server restart will be required to apply the changes. Damit werden dann einige (die ersten) Seitenaufrufe schneller, weil dann dort das Kompilieren entfällt. Bei Blogs oder one-page Lösungen sehe ich da keinen wirklichen Vorteil. Die Kompilierungszeiten mit PHP 7 sind wirklich schnell geworden, so das auch der erste Aufruf der 90% der Anwendung kompilieren würde bei dem normalen OpCache, gefühlt nur minimal langsamer wäre als die weiteren Aufrufe. Der absolute Nachteil wäre, das man den Server wegen jeder Änderung neustarten müsste. Also würde man sich Scripte schreiben, die das Starten und Kompilieren für einen übernehmen. Dann noch WebPack und man hat einen Workflow, der genau so komplex ist wie bei Java-Projekten (nur dass dort mit Maven alles zentraler geregelt wird).
Was habe ich also am Ende. Komplexität, Deployment-Zeiten, eine immer noch nicht ganz so überzeugende Performance, kein Multithreading, keinen Application-Scope und kein Connection-Pooling für Datenbankverbindungen. Also alles was an Java nicht so toll ist und keinen der Vorteile von Java.
Besonders, wenn man immer mehr in die Richtung geht einen HTML5+JS Client mit einer REST-API/Middleware anstelle klassischer MVC-Modelle zu nutzen, wären die F5-Vorteile von PHP wirklich toll gewesen.
Wer also sehr komplexe Seiten mit vielen vielen verschiedenen Views hat, der kann Vorteile durch einen Preload-Cache haben. Bei allem anderen sollte der OpCache allein noch die Performance bestimmen.
B2B ist anders. B2C ist einfach. Bei B2C macht man Werbung, zeigt Preise und versucht einen möglichst offenen (Paypal-Express) und einfachen Checkout den Kunden zu präsentieren. Bei B2B kommt der Kunde teilweise nicht einfach in den Shop. Da ist der Shop eine Dienstleistung, die den Kunden bereit gestellt wird. Also wird man teilweise erst Kunde und kommt dann in den Shop. Preise sind oft auch so eine Verhandlungssache und nicht jedem Kunden werden sofort Preise präsentiert, weil diese ihn verschrecken könnten, da man mit Abnahmen in kleinen Mengen kalkuliert und Staffelpreise zu ungenau wären, weil hier keine Abnahmen pro Jahr oder so dargestellt werden können. Bloß weil ich 1000 Stück bestelle heißt es nicht, dass ich als B2B-Kunde nicht schon genau weiß, dass ich noch weitere 11000 im restlichen Jahr bestellen werde (aber ich will natürlich Lagerplatz sparen oder nicht Dinge aufwendig gekühlt lagern).
Mein erster Versuch etwas für den B2B-Bereich in Shopware zu entwickeln war mein Plugin zum Verhindern von Kundenregistrierungen. Das klingt nach weniger als es kann, weil es doch sehr fein granulär regelt was bei der Registrierung möglich sein soll:
- Keine Registrierung und nur ein Text mit Infos
- Keine Registrierung aber ein Formular für Anfragen
- Blockieren von bestimmten Email-Adressen
- nur bestimmte Email-Adressen erlauben (Mitarbeiter-Shops und so)
- Nur Firmen als Kunden
- Keine Firmen als Kunden
Damit lässt sich schon mal sehr klar definieren, wer und wie in meinen B2B-Shop darf. Muss ich den Account selbst anlegen für meinen Kunden (dann kann ich direkt festlegen was er sehen darf und was nicht) oder darf es selbst muss aber meine Einstellungen abwarten und darf erst dann kaufen? Das alles kann ich damit steuern.
Ich würde gerne stärker in die Richtung gehen und habe anfangen mir eine recht eigene aber doch nicht so einzigartige, wie Firmen oft glauben, Fantasy-Firma aus zu denken und damit einmal exemplarisch einen Weg zu einem fertigen B2B-Shop zu skizzieren. Die Firma vertreibt noch nicht über einen Shop, hat aber eine entsprechende IT mit ERP und WWS. Die Firma produziert selbst, oft auch nach Bedarf, bietet aber auch einige kleine OEM-Produkte zusätzlich zu ihren Produkten an. Diese OEM-Produkte sind meist kleines Zubehör und Verbrauchsmaterialien.
Als Shopware Edition kommt die CE zum Einsatz, weil die an sich ja alles kann und wenn mehr Support gewünscht ist, kann man ja immer noch nachrüsten. Die B2B-Suite lasse ich aus und gucke, ob man nicht die nötigsten Dinge auch einfacher und günstiger selber schreiben kann und wo hier die Grenzen sind (Workflows mit Freigaben und Hierarchien, wäre hier ein Punkt, wo man echt überlegen sollte, ob man da selbst was schreibt).
Die wichtigsten Punkte sind:
1) Produkt-Daten in den Shop bekommen
2) Bestellungen exportieren
3) Lagerbestände abgleichen
4) Kunden Registrierung
5) Preise und Rechnungen
6) Abrufbestellungen
7) Sets aus Produkten (in Hinsicht auf OEM-Zubehör, das ausgehen könnten)
Also fangen wir mal an die Punkte zu analysieren und einfache + schnelle Lösungen zu finden. Denn eine Time-To-Market sollte auch hier nicht länger als 4-6 Monate benötigen. Was das kostet... darüber kann man vielleicht ganz am Ende noch mal nachdenken. Aber so viel würde ich schon mal sagen: Das Team sollte aus einem Shopware-Entwickler, einen Entwickler aus dem ERP-/WWS-Bereich, jemanden für das Theme + allgemeines Design (Umsetzung kann ja über den Shopware-Entwickler laufen) und jemanden der Kunden-/Preis-/Produktdaten betreut.
1) Produkt-Daten in den Shop bekommen Das ERP sollte an sich schon eine Schnittstelle mitbringen um Produkte zu exportieren, wenn nicht kann man die in 2-3 Tagen realisieren. Ob SAP oder was eigenes, es funktioniert alles ganz einfach und linear. Wird ein Produkt angelegt oder geändert und ist von den Daten her vollständig wird es als Datei oder per JMS ausgegeben (per Änderung-Flag oder direkt Live ist dabei sogar egal).
Wenn noch keine Schnittstelle existiert, wäre es gut, wenn diese direkt auf das Event reagiert und den Content per Push an den nächsten Service weiterreicht oder auch auch direkt im richtigen JON-Format an Shopware sendet.
Am einfachsten lässt sich so etwas über eine Template-Engine realisieren, wie sie für fast jede Umgebung existiert.
Ansonsten kann man sich eine eigene kleine Middlware bauen, die Daten per File-Watcher oder MDB empfang, die Daten auf Objekte mappt, die vom Interface her den Models von Shopware gleichen und dann per JSON-Serialisierung ausgeben und direkt an die Shopware-API sendet.
Nur eine Sache würde ich wirklich an der Shopware-API über ein Plugin ändern: Es sollte egal sein, ob man POST oder PUT verwendet, wenn eine Produktnummer dabei steht und useNumberAsId=true gesetzt ist, sollte die API selbst heraus bekommen.
Also das Plugin nimmt die Nummer und lädt die Id dazu nach. Existiert eine wird diese im Model, das gerade rein kommt, ergänzt und die Anfrage an die PUT-Action weitergeleitet. Existiert keine Id wird zur POST-Action weitergeleitet. Das ist dann genau so wie ein Merge bei einem ORM (Doctrine, JPA). Ich hab so ein Plugin schon mal geschrieben und es ist echt praktisch und beschleunigt die Datenübermittlung sehr, weil nicht erst durch ein GET bestimmt werden muss, ob die Software die Daten
als POST oder PUT senden muss.
Sollte als Schnittstelle OCI oder BMEcat zur Verfügung stehen, sollte man diese nutzen. Einen eigenen API-Controller für diese Formate zu schreiben, geht relativ schnell und unkompliziert. Teilweise kann soet was sogar besser sein, als die vorhandene Shopware-API. Wenn man Standard-Formate nutzen kann, sollte man es tun, dann wäre selbst ein Wechsel es ERP (z.B. von was eigenen auf SAP) mit übersichtlich viel Arbeit möglich und was am Shop ändern zu müssen.
2) Bestellungen exportieren
Genau so wichtig wie der Import und Abgleich der Artikeldaten ist der Rückweg, nämlich der Export von Bestellungen. Eine einfache API-Schnittstelle mit Filter auf den Bestell-Status zu schreiben geht schnell und einfach. Somit kann ein anderes System sich alle Bestellungen mit einem oder mehreren Status/Status aus dem Shop einfach abholen. Die simpelste Variante ist es per Scheduler-EJB oder Cron-Job laufen zu lassen.
Wenn man mehr in Richtung Echtzeit gehen möchte, kann man eine neue Bestellung natürlich auch vom Shop aus mit einem Push-Client an eine REST-API einer Middleware oder eines ERP senden.
Die primitivste Variante ist natürlich, die Bestellung als Datei abzulegen und per FileWatcher dann dort abholen zu lassen.
Wichtig bei dem Vorgang ist der Faktor Zeit. Denn ja schneller alles geht, desto weniger Gefahr besteht, das Bestellungen aus dem Shop und dem ERP einen Konflikt um Lagerbestände auslösen könnten.
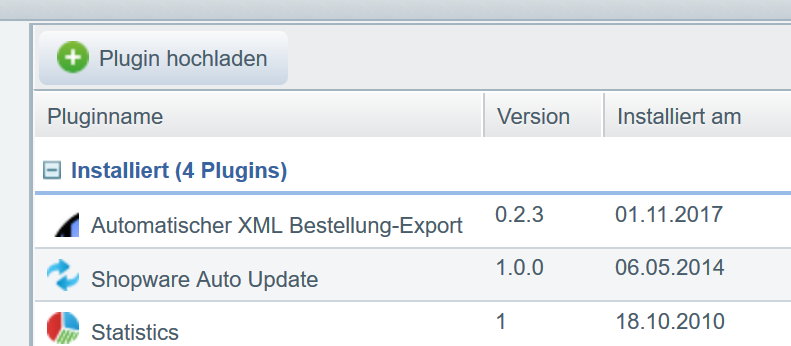
Es fing alles mit einem kleinen Plugin zum dumpen von Bestellungen an, dass ich zum Debugen auf dem produktiven Server entworfen habe. Es entwickelte sich weiter zu einem vollwertigen order-Export Plugin und kann nun:
- Export als Shopware-XML, openTRANS 1.0, openTRANS 2.1
- per XSLT kann man auch jedes weiter XML-format erzeugen (OCI sollte so auch gehen.. sollte.. habe leider kein System zum Testen)
- Export als Datei direkt nach der Bestellung
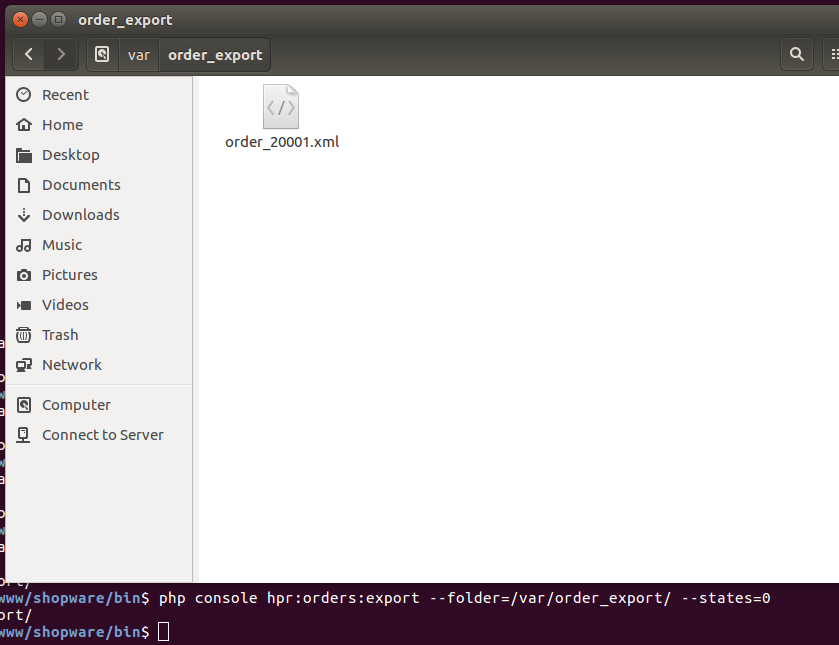
- Export über CLI-Command und Cron-Job (in das Dateisystem)
- Automatisches Status-Update nach dem Export
- Export oder einen REST-API Controller (mit manuellen Status-Update)
- Automatischer Push an eine REST-API (RESTEasy im Wildfly wurde getestet)
Mit den ganzen verschiedenen Wegen und Formaten, ist eine Integration in vielen Fällen möglich. Man benötigt weiterhin einen Entwickler, da mit die Gegenseite korrekt eingebunden werden kann, aber wenn man die Kommunikation erst einmal laufen hat, läuft alles sehr stabil und zuverlässig (eine Version läuft seit Nov. 2017 und hat bis jetzt nie Probleme verursacht).
Bestellungen sind zum Glück immer sehr einfach strukturiert und sind seit Jahrzehnten auch fast unverändert geblieben.
Was das Plugin nicht zur Verfügung stellt sind allgemeine Updates beider Status und die Übermittlung von Trackingcodes. Hier ist aber die REST-API die Lösung des Problems. Da die Nummer der Bestellung beim Export mit übermittelt wurde, kann man anhand dieser die Bestellung über die REST-API laden und modifizieren.
Wenn man das fertige Plugin verwendet, ist der Aufwand eher gering und man kann sich eher um die Update-Aktionen, die vom ERP aus getriggert werden kümmern.
Momentan entwickelt es sich auch zu einem Dropshipping-fähigen Plugin, mit dem man Bestellungen, für sich oder für seinen Kunden, direkt an externe Lieferanten und Großhändler weiterreichen kann.
3) Lagerbestände abgleichen Lagerbestände abzugleichen ist mit das komplexeste Thema bei der ganzen Anglegenheit. Während bei den Artikeln sich nur ein System in eine Richtung synchronisieren muss, geht es hier in beide Richtungen. Denn Bestellungen können sowohl über den Shop als auch das ERP ausgelöst werden und manchmal fällt im Lager auch einfach was runter.
Das schlimmste was passieren kann ist, dass man mehr verkauft als man hat. Im einfachsten Fall muss der Kunde länger warten bis man selbst nachbestellt oder nach produziert hat. Im schlimmsten Fall muss man dem Kunden sagen, dass er die bestellte Ware nicht bekommen kann.
Das eigentliche Problem bei den Lagerbeständen ist, dass alles asynchron und nebenläufig ist. Während im ERP eine Order gespeichert wird, wird auch der aktuelle Lagerbestand bestimmt und 2 Bestellungen aus dem Shop liegen in der Import-Queue (alles mit dem selben Artikel). Wenn der Shop jetzt einfach den da bestimmten Lagerbestand anzeigen würde, wäre bis zum nächsten Abgleich der Lagerbestand wieder um 2 höher, weil der schon durch die Bestellungen abgezogene Bestand bei der Neuberechnung nicht verbucht war, der Shop diese 2 Bestellungen aber ab sich schon kennt.
Hier muss mit Differenz-Buchungen und Timestamp gearbeitet werden. Eine sehr gute Lösung ist das führen einer Lagerbewegung-Chain, die durch Absolute-Lagerbestände in Blöcke auf geteilt wird. Man rechnet immer ab dem neusten Absolute-Eintrag aufwerts.
Beispiel:
-1 order 136 2018-01-01 12:15:00 (exportiert)
-1 order 135 2018-01-01 12:14:59 (exportiert)
-1 order 134 2018-01-01 12:02:00 (exportiert und importiert im ERP)
+8 absolute 2018-01-01 12:00:00
Bestand: 5 im Shop
Es ist gerade 12:15:10 und der Lagerbestand im ERP bestimmt und in den Shop importiert, die beiden Orders brauchen noch 15s bis deren Import beginnt (weil der Austausch über Dateien und Cronjobs läuft). Die letzte Bestandsänderung für den Artikel verzeichnet das ERP für 12:03:10, weil dort die Order von 12:02:00 im ERP verarbeitet wurde.
-1 order 136 2018-01-01 12:15:00 (exportiert)
-1 order 135 2018-01-01 12:14:59 (exportiert)
7 absolute 2018-01-01 12:03:10
-1 order 134 2018-01-01 12:02:00 (exportiert und importiert im ERP)
8 absolute 2018-01-01 12:00:00
Bestand: 5 im Shop
Das ist super! Der Bestand aus Shop-Sicht ist gleich geblieben, weil er in beiden Fällen alle Daten kannte. Es wird nie zuviel verkauft werden, obwohl das ERP noch gerade glaubt 7 auf Lager zu haben, weil es die beiden neusten Bestellungen noch nicht kennt.
Am Ende kann man so schnell wie möglich sein und es wird immer diesen kleinen Bereich geben, wo eie BEstellung gerade unterwegs ist, während der Bestand im ERP berechnet wird.
Wo man diese Differenzverrechnung macht ist nicht ganz so wichtig. Ob in einer Middleware oder im Shop direkt, macht kaum einen Unerschied. Es muss immer der verkaufte Bestand aus den Orders als Differenz verbucht werden und Bestandsmeldungen vom ERP entgegen genommen und gespeichert werden.
Das schöne an dem Prinzip ist auch, dass es sich super erweitern lässt, um zukünftige Bestande über Liefer-Avis und ähnliches. Darüber lassen sich dann wieder Lieferzeiten sehr viel genauer bestimmen, wenn man schon weiß, wann wieder etwas auf Lager sein wird und dann auch wie viel. Wenn ich 10 Stück bestelle und im Avis nur 5 Stück angekündigt sind,muss ich ein Lieferdatum nach der kommenden Lieferung verwenden. Normal bei Shopware hätte man nur die typische Lieferzeit des Suppliers, weiß aber nie ob dann wirklich was da ist und wenn doch wie viel Stück.
Die Implementierung so einer Tabelle und den passenden Queries ist relativ einfach. Events für Orders, um die Verkäufe zu vermerken, sind leicht gefunden. Ein API-Controller, um die Bestandmeldungen vom ERP/der Middleware zu empfangen ist auch nicht viel Arbeit.
Ich habe mal so ein Plugin angefangen und einen schon wirklich sehr vollständigen Prototypen hatt ich nach 3 Abenden.. also wohl so 4-5 Stunden. 1-2 Tage voll daran arbeiten und man bekommt so etwas ohne Probleme hin. Die Zeit zum Testen natürlich nicht mit gerechnet.
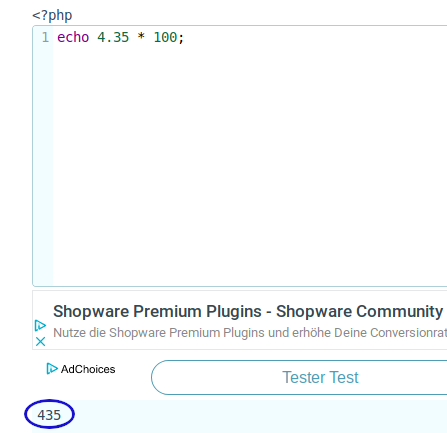
Am 30.6. war wieder Oldtimer Really in Bremen. Diesmal hatte ich frühzeitig zwei Thinkpad T500 organisiert, falls es Probleme bei der Bereitstellung anderer Notebooks geben sollte. Die Software hatte ich seit dem letzten Jahr nicht mehr groß angefasst. Nur die aktuelle Version der Client-JAR zu finden brauchte etwas. Aber nachdem ich die ganz unverhofft im Projekt-Verzeichnis fand, lief dann alles ohne wieder ohne Probleme.
Wieder 5:00 los und.. KEIN REGEN!!!!!! Auch eine weitere Besonderheit kam hinzu. Das 2. Zeitfahren wurde mit einem anderen System gemessen und später sollten die Ergebnisse beider Systeme für das Gesamtergebnis kombiniert werden. Ein kleines PHP-Script lass alle Renn-Ergebnisse als CSV ein und wertete diese aus. Alle Fahrer die nicht alle 3. Zeitfahrten absolviert hatten.
Nach dem Tag hab ich mir vorgenommen, die Integration mit anderen Systemen zu verbessern. Auch die Clients könnten dann ihre Auswertungen nicht nur per REST-API übermitteln, sondern auch eine CSV generieren, die dann ausgelesen werden kann. Der Import wäre dann so flexibel, dass er auch CSV-Dateien anderer Systeme importieren könnte.
Ein anstrengender Tag, aber die Messungen liefen wirklich gut und es gab kaum Fehlmessungen, durch Fahrtzeuge die zu dicht am Messbereich parkten.
Wer also bei Rennen oder ähnlichen jemanden braucht, der die Zeitmessungen und Auswertungen übernimmt, kann sich vertrauensvoll an die Switch GmbH wenden... auch was Temperaturüberwachung angeht.
Aufbauen
Surface als Messstation, der Client läuft noch in Eclipse
Eine kleine Klasse, die ich mal für ein kleines Projekt geschrieben hatte, das mein Bruder brauchte (Verarbeitung und Katalogisierung von mehren 10.000en RTF-Dokumenten). Die Klasse liest alle Dateien eines Verzeichnisses und die alle seiner Unterverzeichnisse ein.
private HashMap<String, String> arguments = new HashMap<>();
public ArgumentResolver() {
}
public ArgumentResolver(String[] args) {
this.readArray(args);
}
/**
* converts an argument array with '-' as argument seperator in a easy
* readable structure
*
* @param args the argument array from e.g. the main-method
*/
public void addArray(String[] args){
this.readArray(args, false);
}
/**
* converts an argument array with '-' as argument seperator in a easy
* readable structure
*
* @param args the argument array from e.g. the main-method
*/
public void readArray(String[] args) {
this.readArray(args, true);
}
/**
* converts an argument array with '-' as argument seperator in a easy
* readable structure
*
* @param args the argument array from e.g. the main-method
* @param clearBefore clear the existing map
*/
public void readArray(String[] args, boolean clearBefore) {
if(clearBefore){
this.arguments.clear();
}
/**
*
* @param name argument name
* @return gives back the existence of the argument with the given name
*/
public boolean existsIn(String name) {
return this.arguments.containsKey(name);
}
/**
*
* @param name argument name
* @param defaultValue argument value if not found
* @return value of the argument with the given name
*/
public String getArgumentValue(String name, String defaultValue) {
return this.existsIn(name) ? this.arguments.get(name).trim() : defaultValue;
}
/**
*
* @param name argument name
* @return value of the argument with the given name
*/
public String getArgumentValue(String name) {
return this.getArgumentValue(name, "");
}
/**
*
* @return count of arguments
*/
public int size() {
return this.arguments.size();
}
}
Syntax ist weiterhin so:
java -jar example.jar -name blubb blubb -value 1
name ist dann "blubb blubb" und value ist "1". Diese Klasse kommt an sich bei jeden meiner Java-Projekte zum Einsatz, wenn das Programm über die CLI bedient werden kann.
Da alles andere irgendwie zu groß oder zu teuer ist, habe ich mir mal was einfaches kleines gebaut. Es braucht zwar einen Client als Service auf dem PC (oder starten mit Admin-Rechten), aber dafür läuft alles über HTTP und der Client-PC muss nicht eingeschaltet sein, sondern prüft wenn er angeht oder jede Stunde einmal.
Momentan gibt es noch keine Unterscheidung der Betriebssysteme und eine gute Server-Umgebung fehlt auch. Aber man kann auch alles ganz plain und primitiv auf dem Server ablegen ohne eine extra Software.
Mal gucken was daraus wird. Aber gerade weil es alles so einfach und klein ist, sehe ich da doch etwas Potential, wenn dann eine Server-Software dafür existiert wird.
Die Differenz zwischen zwei Datumswerten in Tagen:
Java (LocalDateTime)
if(ldt1.isAfter(ldt2)){
days = Duration.between(ldt1.toLocalDate().atStartOfDay(), ldt2.toLocalDate().atStartOfDay()).toDays();
days = Math.abs(days);
}
Java (Date)
long days = TimeUnit.DAYS.convert(date.getTime() - date2.getTime(), TimeUnit.MILLISECONDS);
Wenn man mit dem XML-Parser von jcabi-xml arbeitet und der direkt am Anfang der Datei behauptet, es würde nicht nach einer XML aussehen, kann es am UTF8-BOM liegen.
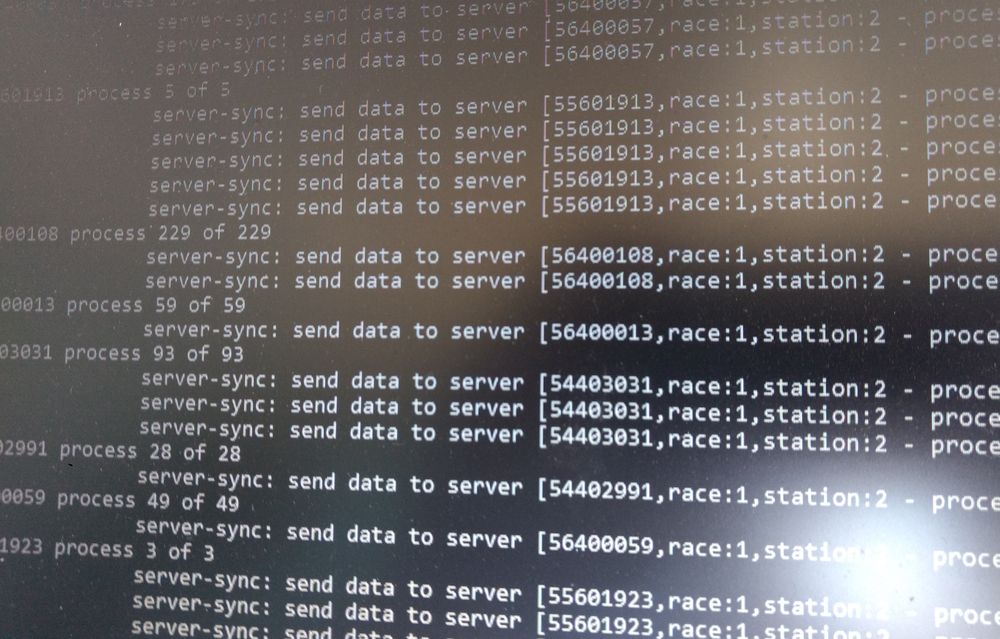
Mein 2. Shopware Plugin (also.. das 2. das in den Community-Store soll..) ist jetzt so gut wie fertig. Es fehlen nur noch ein paar Test und Dokumentation.
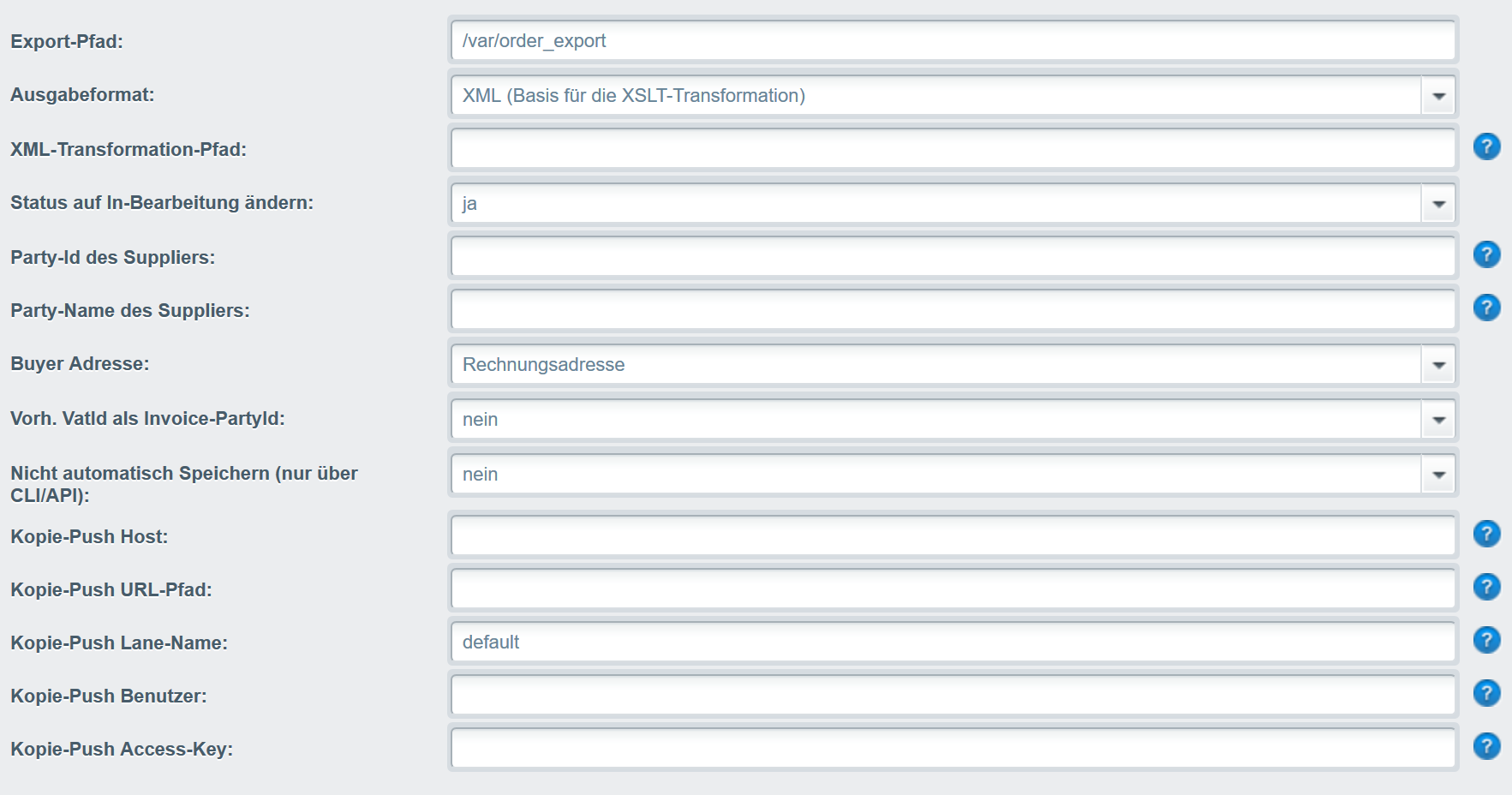
Das Plugin stellt einen Export der Orders bereit. Im Gegensatz zu den eingebauten Export hat man hier ein paar mehr Möglichkeiten das Aufgabeformat (so lange es XML ist) anzupassen und alles zu automatisieren.
Features:
- XML Formate: nativ, openTRANS 1.0 (eher experimentell), openTRANS 2.1
- automatischer Export direkt nach der Bestellung als Datei in ein lokales Verzeichnis
- automatischer Export als XML in einem JSON Container per Push (getestet mit einem Wildfly 11 und einem RestEasy Endpoint)
- Export bestimmter Orders in ein Verzeichnis per CLI
- Abfrage über die REST-API
- REST-API: Als XML in einem JSON-Container (Liste und einzelnd)
- REST-API: Als XML (einzelnd)
- XSLT-TRansformation, damit ist man im Ausgabeformat nicht eingeschränkt (egal ob mit Automatisch, CLI oder REST-API)
- Für die openTRANS-Formate gibt es verschiedene Einstellung für Buyer-Definition und die Party-Ids
Es ist also ein Plugin was rein auf die Integration von Shopware in vorhandene Bestell-Prozesse mit ERP-Systemen wie SAP ausgelegt ist. Arbeit wirklich gut mit Java Application Servern wie Wirldfly zusammen und auch zum Debuggen ist es sehr praktisch die Bestellungen als XML zu dumpen.
Ein relativ alter Fork des Plugin wird bei https://www.notebookswieneu.de genutzt, um die Bestellungen als openTRANS 1.0 an das SAP-System
zu übermitteln.
Diese Woche werden die letzten Dinge erledigt und dann wird es hoffentlich Anfang nächster Woche für den Store eingereicht.
if(dateFuture.isAfter(now)){
days = Duration.between(now.toLocalDate().atStartOfDay(), dateFuture.toLocalDate().atStartOfDay()).toDays();
}
An sich ganz einfach und hat alles was man sich sonst selbst gebaut hat. Gerade in PHP erinnere ich mich noch sehr daran startOfDay implementiert zu haben.
Das Arbeiten mit der Time-API von Java ist teilweise echt nicht einfach. Auch gibt es vielmehr zu schreiben und ohne Hilfe aus dem Internet geht es einfach nicht. Wobei ich die ".from()"-Methoden schon wirklich nett finde.
Wenn man die letzten 2-3 Jahre fast nur PHP gemacht hat, erschlägt einen es fast schon, von der Fülle an Kombinationen und Klassen die man hier benötigt. Jeden Falls auf den ersten Blick. Auf den zweiten sieht es besser aus und auf den dritten gefällt es einen dann auch schon wirklich.
Und im Gegensatz zum guten alten Date mit SimpleDateFormat funktioniert es auch ohne Probleme.
Java tut auch hier was es am Besten kann: Es zwingt einen es richtig zu machen.. mit ZoneId und allem was man sonst der Bequemlichkeit halber oft lieber weg lässt.
Am 24.6. war es wieder so weit und das Bremer Oldtimer-Rennen stand wieder für mich vor der Tür. Wie im Jahr davor sollte meine Aufgabe sein, die Zeitmessungen (jeden Falls einen Teil davon) durch zu führen und am Ende die Gewinner benennen zu können. Klingt erst einmal ganz einfach aber für diese Sache, die an sich voll automatisch laufen sollte, ist immer viel mehr zu tun als man so denken würde.
Dafür muss man das Grund-Setup kennen und verstehen. Bei dem Rennen nehmen 170 Autos teil. Jedes dieser Autos wird mit einem aktiven RFID-Tag ausgestattet der den Tag über die Kennung des Autos aussendet. Die Veranstaltung besteht genau genommen aus 3 Rennen. Da es natürlich unfair wäre, bei Autos von 1920 bis 1970 auf Minimalzeit pro Strecke zu fahren, wird immer auf eine Richtzeit gefahren. Der Fahrer, der am dichtesten an der Zeit dran ist gewinnt. Also kann der zweit etwas langsamer als die Zeit sein und der 3. etwas schneller. Es nur um die absolute Differenz.
Am Anfang und am Ende jeder Strecke steht dabei ein RFID-Reader, der alle Autos erfasst, die vorbei fahren.
RFID sendet aber bei einem aktiven Tag mehr als die Sekunde sein Signal und die Reader decken mit ihren Antennen einen größeren Bereich ab. Es funktioniert also grundlegend anders z.B. eine Lichtschranke. Man bekommt also eine Menge an Messwerten, die vom Auto gesendet werden, während es vorbei fährt. Daraus wird nach dem relativ einfachen Prinzip von Zuerst-Gesehen und Zuletzt-Gesehen der Mittelwert berechnet.
Dabei kann an sich schon genug schief laufen. Gerade wenn man kleine und kurze Strecken hat. Wenn das Auto schon soweit beim Start an den Reader heran fährt und schon Messwerte erfasst werden, aber das Auto noch nicht losfährt. Dann wird die Zeit in der das Auto steht, mit Pech mit in die Zeitberechnung mit hinein gerechnet.
Aber auch die Chips und Sender der Tags sind nicht immer zuverlässig. Auch wenn sie 100 mal die Sekunde senden sollen, kann man nicht immer sicher sein, dass es keine Einbrüche in dieser Frequenz gibt. Autos aus Metall können außerdem sehr gut Abschirmen und so die Sendeleistung stark beeinflussen. Bautechnische Probleme wie schlechte oder defekte Schalter zum Ein- und Ausschalten kommen noch dazu.
Diesmal hatten wir im Vorwege das Problem, dass allein durch die Bewegungen der Tags in der Kiste sich einige einschalteten und anfingen zu senden und so Tags empfangen wurden, die gar nicht zum Rennen gehörten.
Durch einen guten Aufbau und ein wenig mehr Programm-Logik kann man fast alle Probleme unter Kontrolle bringen. Aus der Menge der Messpunkte werden konkrete Werte errechnet. Mehrfachmessungen eines Autos werden entfernt und fehlende Messungen werden herausgesucht. Das benötigt etwas mehr Rechenleistung, weswegen die Messstationen mit etwas Leistungsfähigeren Notebooks ausgestatteten sein müssen.
Damit kommen wir erst einmal wieder zurück an den Anfang. Die Vorbereitung und was diesmal alles zu tun war.
Vorbereitung:
Nachdem im letzten Jahr mehr oder weniger spontan Notebooks mit dem Mess-Client ausgestattet wurden und es zu vielen Problemen kam:
- Fehlende Runtime-Umgebungen
- andere Server-Anwendungen die Ports blockierten
- Notebooks auf denen schon so viel installiert war, dass sie langsam waren
- Akkus die nicht mehr lange durch hielten und deswegen immer Strom nötig war (den es nicht immer gibt)
Ich fing also schon 2 Monate vorher an, das Problem in Angriff zu nehmen. Ich entschied mich die Hardware diesmal komplett selbst zu stellen und somit etwas mehr Sicherheit zu haben. Das Alienware sollte diesmal nicht benutzt werden, da es schwer ist und man es nicht mal schnell zur Seite nehmen kann, wenn es regnet. Außerdem ist es einfach nicht dafür gedacht, über den Akku zu laufen.. jedenfalls nicht langer als 15min.
Da ich für Notfälle aber eine Entwicklungsumgebung haben wollte, damit ein Fehler nicht ein Rennen versauen kann oder die Auswertung unmöglich macht, entschied ich mich mein Surface mit zunehmen. Es ist relativ Wetter-beständig und der Akku hält sehr lange. Die Rechenleistung ist nicht wirklich groß, aber ausreichend.
Damit waren meine eigenen Notebook Vorräte aber erschöpft und extra welche Kaufen würde sich nicht lohnen. Also kam ich auf die Idee meine Kontakte als Mitarbeiter bei Notebooks Wie Neu zu nutzen. Ich konnte mir 2 Lenovo Thinkpad T410 leihen. Mit i5, 4GB RAM waren die mehr als schnell genug und Thinkpads sind auch stabil genug, so das ich mir wegen Regen nicht zu viel Sorgen machen musste. LAN und USB Anschlüsse waren auch vorhanden. Der Akku hielt mehr als genug und am Ende waren die Akkus nicht mal halbleer, obwohl die Thinkpads ca. 2h damit beschäftigt werden durchgehend Daten abzurufen und in eine MySQL-Datebank zu schreiben.
Nur eine Sache störte mich etwas.. das war Windows 7. Egal was viele im Internet so schreiben.. bei der Bedienung ist Windows 10 sehr viel schneller und intuitiver als Windows 7. Aber da alles wie Java 1.8 und MySQL laufen, ist es nicht so schlimm, weil die Client-Software sowie so rein über die CLI bedient wird. Eine GUI Version existiert, ist aber noch auf eine Verbindung zum Server angewiesen, was da nicht gegeben war. Ein portabler UMTS-WLN-Router wäre eine gute Lösung gewesen, aber die Idee kam mir zu spät und ich wollte ja gerne den Server bei Problemen schnell ändern und fixen können. Was mit einer lokalen Instanz, die man direkt in der IDE hat, natürlich sehr viel schneller und einfacher geht als mit einem System das auf einem Server im Internet läuft.
Vielleicht bin ich nächstes Jahr mal mutiger. Es hätte auch noch andere Vorteile für die Veranstalter.. aber dazu später mehr.
Die Liste der Teilnehmer konnte ich am Abend vorher importieren und dabei noch 2 kleine Fixes einbauen. Deswegen wollte ich die Liste gerne schon vorher haben.
170 Autos. 170 importierte Rennteilnehmer am Ende. Alles perfekt.
Ich hatte also 4 Notebooks (das Alienware war als Fallback dann doch dabei), Reader, Netzwerk-Kabel und einen Switch. Was man aber immer dabei haben sollte, ist auch Essen und Trinken. Wasser und Energiedrink. Eines für den Durst und das andere für Energie. IBUs für Notfälle und natürlich das Smartphone für Navigation und Informationsbeschaffung. Beim Essen kann man sich ruhig abends vorher was kochen, denn gutes Essen macht es einen sehr viel einfacher, wenn man morgen um 4:15 aufstehen muss und dann noch kein Frühstück hatte.
Immerhin war das Wetter gut und nicht so verregnet wie im letzten Jahr... jeden Falls am Anfang
Der Tag:
Um 4:45 war ich in Stockeldorf bei "die Halle" wo die Switch GmbH ihren Sitz hat. Die Mitarbeiter wuselten durch die Gegend und packen alles in den VW Bus was man so brauchte. Dann wurde ein Karton mit Tags hochgehalten und gefragt, ob die auch mit sollen. "Nein, das sind die, die nicht funktionierten und ausgewechselt wurden".
Klingt erst einmal nicht so schlimm, aber wenn man bei 170 Teilnehmern 30 Tags für jeweils drei Rennen austauschen muss.. also 90 Einträge per Hand bearbeiten, dann klingt es nicht mehr gut. Am Ende wurden also diese Ausgetauschten alle geöffnet und Batterien getauscht. Am Ende waren es pro Rennen nur jeweils ca. 6 Tags, die per Hand übergetragen werden mussten.
Hier fiel mir auch auf, dass die Tags dieses Jahr gefühlt sehr viel Fehleranfälliger waren. Beim Testen wurden noch 4 ausgetauscht, weil sie nicht vom Reader erkannt wurden. Die Schalter schalteten in den Karton bei jeder kleinen Bewegung wie sie wollten.
Und dann kam der Regen. Viel Regen. Alles wurde unter die offene Heckklappe des VW-Bus gestellt und das Surface wechselte erst einmal in eine Plastiktüte.
Es war zum Glück nicht wirklich kalt. Nur sehr sehr nass. Wer glaubt das Regen und die Nässe nur immer von oben kommt, irrt sich. Tropfen fallen auf Tische und spritzen dann in alle Richtungen. Am Ende ist doch alles nass.
Aber es gab auch positives zu berichten. Weniger Tags streuten in den Messbereich und die Erkennung war dieses mal sehr viel besser. Das andere Team meldete sich schon kurze Zeit später und meldete, dass alles laufen würde. Ich bin immer sehr unruhig wenn ich bei so etwas nicht in der Nähe sein kann, um möglicherweise auftretende Fehler zu beheben. Ich kenne das System zu 100% und einfach unerfahrene Benutzer damit los zu schicken.. dazu gehört sehr viel Vertrauen in die eigene Software dazu.
Am Ende war alles super. Alles hatte beim ersten Rennen funktioniert und das Thinkpad konnte zeigen was es konnte. Beim Surface braucht ich so 15min mit Client in der IDE um die Daten zu übertragen. Dabei liest der Client und schreibt der Server auch in die selbe Datenbank, was auch nochmal bremst. Das Thinkpad brauchte gerade mal 4-5 Minuten. Schnelle CPU, schnelles Lesen von der Festlatte. Das Schreiben in die DB auf dem Surface war dann auch sehr entspannt, weil nebenbei nicht so viel gelesen oder gerechnet werden musste. Also Server und Entwickler-Rechner hat sich das Surface mehr als bewährt. Das selbe gilt auch für die Thinkpads als Messstationen-Clients.
Das 2. Rennen war dann die kritische Phase, die dann aber auf Grund der stabilen Bauweise der Reader und viel Nachrechnen und eliminieren von Fehlmessungen, am Ende doch gut ging. Wir hatten kaum Zeit zum Aufbauen, ein Reader lief an einem Diesel-Generator und 50m Lan-Kabel. Die ersten Autos wurden manuell gemessen mit der eingebauten App vom Time-System, während wir nebenbei den zweiten Reader aufbauten, der dann am Alienware lief. Sturm, Regen und noch mehr Regen. Wir saßen im Bus und nur die Kabel zu den Readern im Regen gingen nach draußen. Ich wüsste zwischendurch nicht ob der Reader am Start noch lebte und Daten sendete. 1,5h später war der Regen vorbei und man ordnete sich und guckte mal wieder auf die Terminal-Ausgaben auf dem Surface. Alles lief super. Es fuhr gerade das letzte Auto vor und der Reader meldete den Tag also ob vorher nicht gewesen wäre. Sein Netzteil hing so im Regen und ein Teil des Kabel lag vorher schon blank. Aber kein Aussetzer bei der Datenerfassung. Ich war wirklich stolz auf den kleinen tapferen Reader.
Das Netzwerk-Kabel wurde auch nebenbei als Streckenbegrenzung verwendet. Von der Planung her eine Katastrophe, aber mit den Fallback-Lösungen konnte man alles retten.
Danach ging es zur Test-Strecke von Mercedes und das 2. Thinkpad übernahm das Rennen dort. 1. Rennen war in 20min fertig. Ich hab bevor Korrektur-Funktionen über die Daten liefen immer lieber noch einmal die Daten gesichert. Berechnen lief schnell.
Das 2. Rennen brauchte mehr Zeit. über eine Stunde, da ich viel bei den Korrektur-Funktionen nacharbeiten musste, die Fehlmessungen eliminierten und ich lieber 3 mal die Liste der gefahrenen Autos durch ging, um sicher zu sein, dass wirklich kein Auto übersehen oder nicht gemessen wurde.
Das 3. Rennen ging dann wieder sehr schnell und es gab keine Überraschungen.
Bestes Frauen-Team musste dann per Hand berechnet werden. Waren aber nur sehr wenige Teams, deswegen ging es. Der Gesamtsieger war aufwendiger, weil man über die gesamten drei rennen Rechnen musste, zum Glück sind es doch immer die selben Fehler die vorne liegen. Damit war es ausreichend die 9 Sieger der 3 Rennen zu nehmen und für diese die Werte der 3 Rennen auszuwerten. Kontrolle bei den 4. und 5. Plätzen zeigten gleich, dass von dort keine Konkurrenz mehr kam.
Auch fiel dabei auf, dass man kein großes Kopf-an-Kopf-Rennen hier hatte. Die ersten Plätze waren immer sehr eindeutig, eher am Ende des ersten Drittels konzentrierten sich die Zeiten auf eine geringe Zeitspanne.
Das Fazit:
Das Event lief sehr viel besser als das letzte Jahr und die Zeiten für die Auswertungen war sehr viel geringer. Die automatischen Analysen und Korrekturen von Fehlmessungen hat viel gebraucht und sehr viel besser und zuverlässiger funktioniert, als es per Hand war.
Trotzdem hätte ich gerne eine andere Lösung für das nächste mal. Die Tag an sich sind eine Fehlerquelle für sich und diese würde ich gerne eliminieren. Eine Lösung wäre eine Kamera gestützte Erfassungsmethode mit QR-Codes. Wie Lichtschranken, gibt es da aber Probleme bei parallel fahrenden Autos. Deswegen müsste man ein Gestell haben, um die Kameras von oben auf die Start- und Ziellinie gucken zu lassen. Dann muss man die Autos erkennen, da man so wirklich von vorderen Punkt des Autos messen kann und nicht nur die Position des RFID-Tags (was viele Teilnehmern nicht klar war, sich aber natürlich auf die Messungen auswirkt).
So ein System ist sicher zu bauen, aber braucht seine Zeit. Am Ende hätte man aber sicher gute Ergebnisse mit Beweisfoto.
Auch sollte alles so aufbaubar sein, dass die Technik die Autos nie verlassen muss. Mehr Schutz vor Regen und man kann schneller aufbauen, wenn nur noch Kabel verlegt werden müssen.
Ein großer Traum wäre es, es wirklich als Cloud-Anwendung laufen zu lassen, so dass die Clients direkt vor Ort über einen WLAN-UMTS-Router ihre Daten direkt an den Server schicken können. Vielleicht sogar kurz nach dem sie gemessen wurden. Damit hätte man auch die Möglichkeit eine Echtzeit Anzeige zu realisieren.
Wie man überall lesen kann will Oracle nun auch JEE gerne abgeben. Aber sie sichern zu weiterhin an Java festzuhalten.
In den meistens News klingt es so als wäre das ein Widerspruch in sich. Ich kann Oracle aber vollkommen verstehen. Der Java-Core ist so oder so OpenSource und JEE ist optional und kann durch andere Lösungen wie Spring ersetzt werden. Wie Standards wie JMS, EJB3 und so sind wirklich toll und funktionieren super. Sie werden auch viel genutzt, also kann man die auch nicht wirklich sterben lassen, gerade wenn man selbst damit viele Anwendungen gebaut hat.
Oracle auch wirklich viel mit Java gemacht und auch sehr gute Anwendungen damit entwickelt. Nur warum sollte man dafür im Besitz eine Standards sein? Als das alles noch bei Sun lag lief auch alles super und (jetzt folgt der wichtige Punkt) man musste sich nicht mit dem ganzen Drumherum rumärgern.
Als PHP Entwickler hat man ja auch nicht gleich Lust sich den PHP-Standard noch mit auf zu halsen.
Bei der Eclipse Foundation wäre JEE gut aufgehoben und Oracle kann weiterhin mit Java entwickeln und sich sogar einbringen ohne gleich für alles verantwortlich gemacht zu werden.
Ich bin jeden Fall gespannt wie es weiter geht und sehe da mehr Zuspruch in die Zukunft Javas von Oracles Seite als mögliches Abwenden von JEE oder gar Java an sich.
Nachdem ich mich jetzt einige Tage lang mit Kotlin beschäftigt habe, bin ich noch etwas zwiegespalten, ob Kotlin mit seinen Ansätzen, es wirklich besser oder einfach nur anders macht.
Einiges was da an Java kritisiert werde, halte ich in Java sogar für besser gelöst, wobei ich aber durch aus die Kritik verstehe. Zum Beispiel haben== und equals() schon genug Leute/Einsteiger verwirrt.
Kotlin macht es anders. == und === sind wirklich logisch und nachvollziehbar. Es folgt der Umsetzung in PHP oder JavaScript. == vergleicht den Wert und === vergleicht die Referenz.
Aber ist == als Ersatz für equals() wirklich besser?
Date d = new Date();
MyDateImpl md = new MyDateImpl();
Es ist durchaus möglich das eine Klasse von mir sich mit sich mit einer standard
Java-Klasse vergleichen lässt, aber die standard Java-Klasse nicht mit meiner, da deren Existenz der standard Java-Klasse natürlich vollkommen unbekannt ist.
val d = Date()
val md = MyDate()
if(d == md){
println("== 1")
}
if(md == d){
println("== 1")
}
Ist das jetzt beides das selbe? Konnte ich auf die Schnelle nicht heraus finden.. werde ich wohl mal testen müssen.
Ist es falsch das Java einen zwingt eine Exception zu fangen, wenn explizit eine geworfen werden kann.
Also das Fehler dort behandelt werden, wo sie auftreten und man sie nicht immer bis ganz nach oben reichen sollte?
public class ThrowExample {
private void method1() throws Exception {
throw new Exception("test");
}
public void call() throws Exception {
this.method3();
}
}
Bei Java kann es so nie passieren, dass am Ende eine Exception auftaucht, von der man nie wusste, dass sie geworfen wurde. Weil sie entweder schon mit einem Try-Catch-Block gefangen wurde oder aber man über die Existenz dieses Exception mit Hilfe des "throws" an der Methode direkt informiert wird.
PHP hat mit Exception ab PHP 7.0 viel verbessert, aber um die Wahrheit zu sagen, ist das was ich noch gerne hätte ein "throws" damit ich weiß, dass in der Methode, die ich gerade verwende, das Werfen einer Exception implementiert wurde.
Fehler Behandlung ist schwer und Exceptions als brauchbare Fehlermeldungen an den Benutzer hoch zu reichen ist nicht einfach... aber einfach dann die Exceptions bis zum Benutzer durch laufen zu lassen ist doch eher der falsche Weg und ein gutes Exception-Handling Framework wäre die bessere Lösung gewesen.
Deswegen sehen ist den Verzicht auf den Zwang Exceptions fangen zu müssen in Kotlin eher negativ und nicht als Vorteil.Nur als einen Punkt nun dem Entwickler aufgehalst wird (er muss sich nun darum kümmern, dass Exceptions richtig behandelt werden), wo vorher der Compiler einen dabei unterstützt hat auch alle Exceptions richtig zu behandeln.
Wenn man bei Shopware über die REST-API einen Artikel lädt und dann wieder speichern möchte, kann es dazu kommen, dass ein Fehler auftritt, dass der Preis mit der Id X unbekannt sei. Das scheint wohl so gewollt sein. Deswegen sollte man beim Mappen auf Klassen die Id des Prices aus dem mainDetail des Artikeln einfach unterlassen.
//persist failed if a id is present
@JsonIgnore
private int id = 0;
Hier findet meine Post im Shopware-Forum zu dem Thema
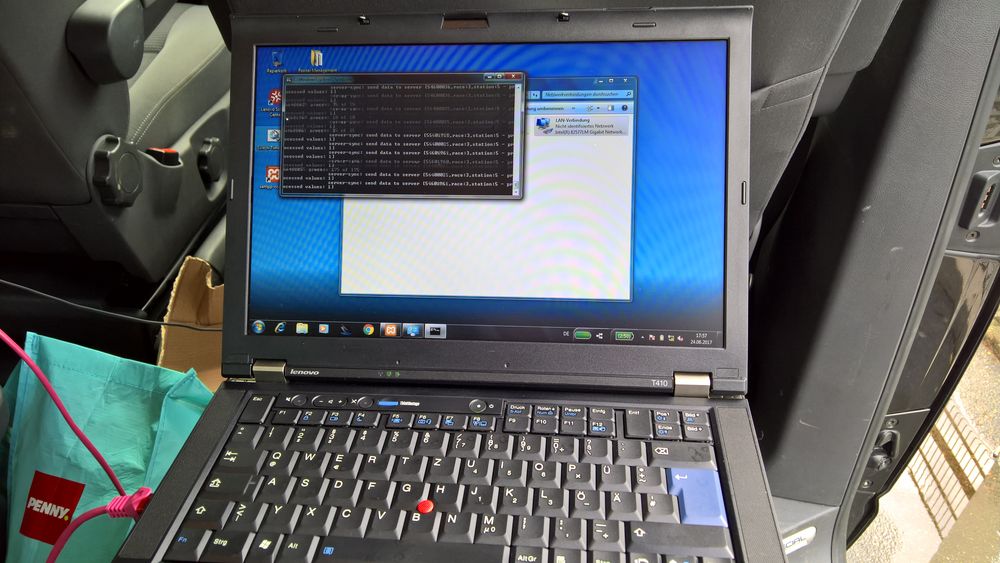
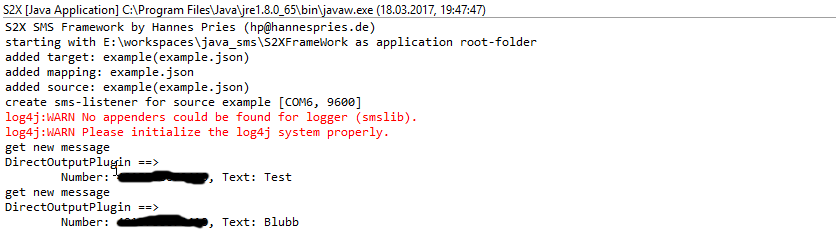
Den ersten Test hat mein Framework schon geschafft. Es hat SMS empfangen und durch die Pipeline an das Dummy-Plugin weiter gegeben. Jetzt muss nur noch mal getestet werden, dass die Patterns und Value-Checks alle richtig greifen.
Dann hoffe ich ein es einem ersten Projekt verwenden zu können.
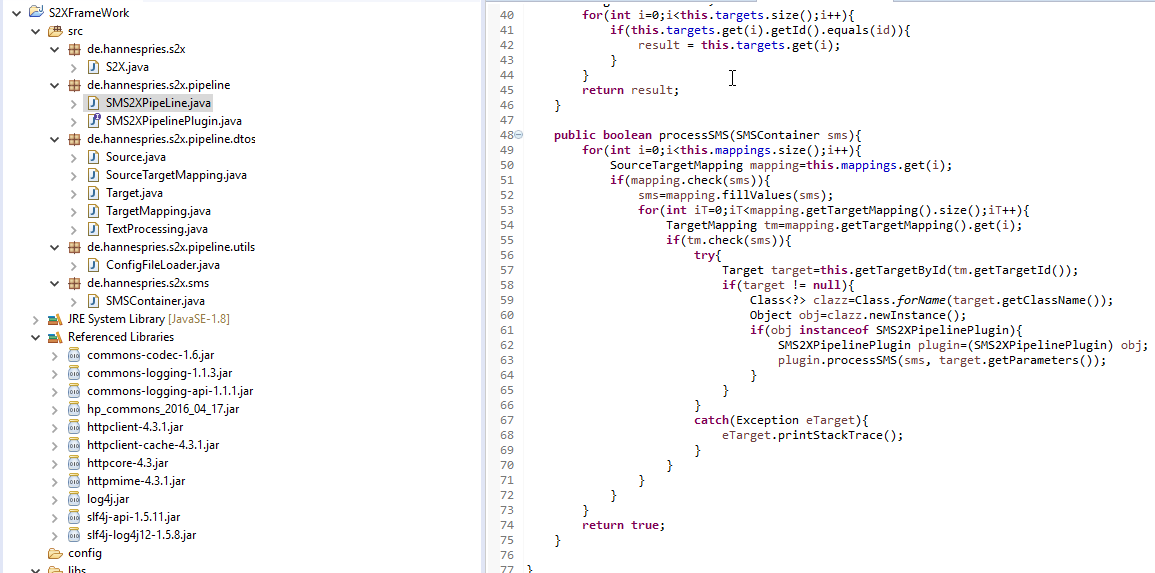
Mein neustes Projekt ist heute Abend gestartet. Es geht um ein Framework, dass SMS empfangen kann und diese dann anhand verschiedener Regeln wie Absender, Empfänger oder Inhalt an ein oder auch mehrere externe Systeme weiterleiten kann.
Diese Weiterleitung an andere System geschieht über Plugins, die auch dann die Daten aus der SMS aufbereiten sollen, so dass sie vom externen System verarbeitet werden können.
Einfache Plugins wie "in eine DB" schreiben, an einen REST-Service oder meine MessageDriven Bean schicken, werden direkt dann mitgeliefert.
Das Empfangen und Senden von einer SMS mit Java habe ich schon letzten Monat erfolgreich getestet, deswegen glaube ich, dass ich relativ schnell zu ersten Ergebnissen kommen werden. In den nächsten 2 Monaten hätte ich gerne den ersten brauchbaren Prototypen.
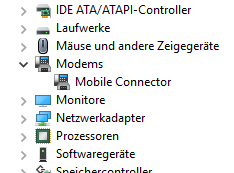
Heute ist der neue Stick angekommen und nachdem die Software von der Herstellerseite installiert wurde, wurde er auch problemlos unter Windows 10 erkannt.
Der Stick ist ein 4G Systems XS Stick P10 und bei dem Preis kann man wohl erst einmal nicht viel falsch machen.
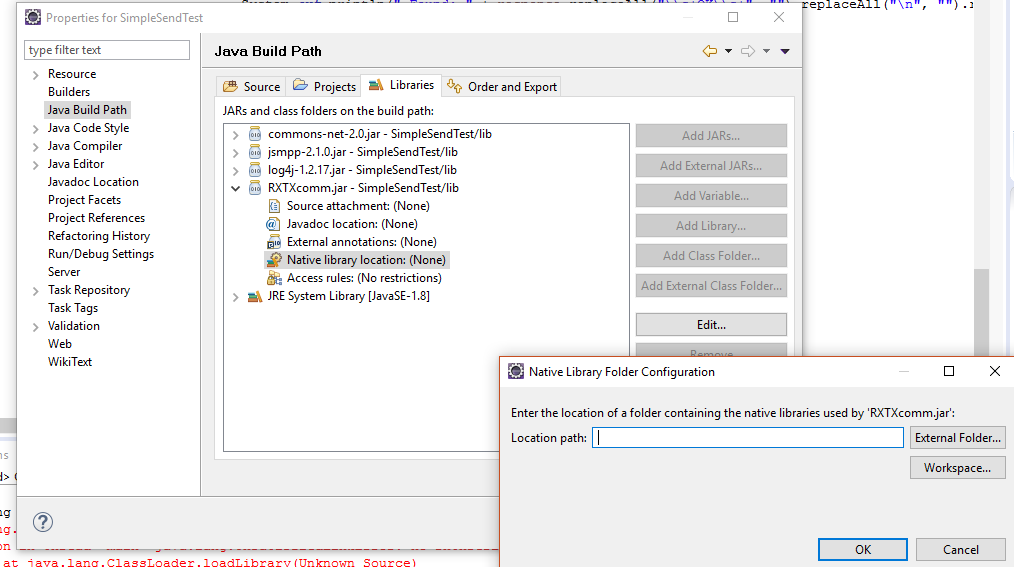
Um RXTXComm für Java in Eclipse verwenden zu können muss man auch die DLLs Eclipse bekannt machen.
Im Buildpath muss man die JAR finden und dann ausklappen. Bei der Native Library Location muss man Edit wählen.
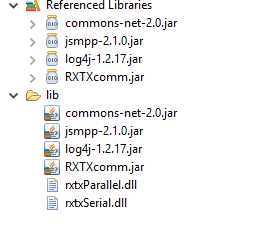
Ich hatte die DLLs einfach mit im lib-Folder abgelegt.
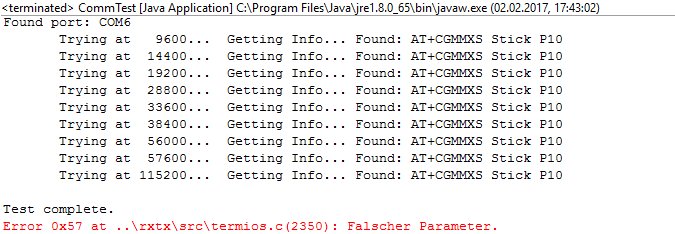
Danach lief auch die Suche von SMSlib.
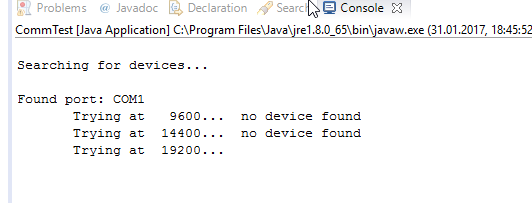
Leider funktioniert mein alter Huawei E1750 unter Windows 10 wohl nicht mehr so einfach. Ich habe mir mal den 4G Systems XS Stick P10 bestellt und hoffe, dass dieser gleich und ohne Probleme funktioniert.
Und dann mal die Beispiele zum SMS-Empfang von SMSlib testen.
Blog-entries by search-pattern/Tags:
Möchtest Du AdSense-Werbung erlauben und mir damit helfen die laufenden Kosten des Blogs tragen zu können?
 bezahlt von
bezahlt von  Blog: Blog-entries by search-pattern/Tags:
Blog: Blog-entries by search-pattern/Tags: