In den wenigsten Fällen, nutzt meine REST-API für einfache CRUD-Operationen. Oft muss man auf die Operationen auch reagieren. Z.B. will man, wenn eine neue Bestellung angelegt wird, auch eine Lager-Reservierung oder einen Export an das ERP anstoßen. Oder man hat Felder die übersetzt werden müssen. Auch will man bei bestimmten Resourcen wie Artikeln noch Metriken mitgeben, wie oft er verkauft wurde und ob er damit zu einem Top-Seller wird.
Für diese Anwendungsfälle stellt API Platform zwei verschiedene Konzepte zur Verfügung.
Data-Provider/Data-Persister Wenn man wirklich Daten an der Resource ändern möchte, ist das hier der richtige Weg. Man greift hier direkt in die Persistierung ein. Der Data-Provider ist für das Laden und der Data-Persister, wie der Name schon sagt, für das Speichern zuständig. Damit man nicht die gesamte Grundlogik jedes Mal neu schreiben muss, kann man hier die vorhandenen Services dekorieren und den Ursprünglichen Service als Parent per Injektion mit rein reichen. Also klassisches Symfony. Wenn nun also Custom-Fields oder eine Sprache in der übergebenen Resource (in transient Fields) definiert sind, kann man die im Persister sich heraus picken und selber sich um die Speicherung
kümmern. Im Provider eben das selbe nur anders herum.
Nun kann man sich denken: "Ich will den Artikel mit seinen Änderungen gerne in einem ElasticSearch-Index haben, damit die Suche auch gleich aktuell ist." Aber dafür ist das der falsche Weg.
Events Wie in Shopware sind hier Events der richtige Weg. Man greift dabei nicht in den Peristierungsvorgang ein und es kann weniger schief laufen. Jeder Subscriber arbeitet unabhängig und wenn einer fehlschlägt, sind die anderen Subscriber nicht eingeschränkt. Gerade bei den POST_WRITE-Events erhält man eine Kopie der Resource und sollte diese nicht ändern. Falls irgendwie der Entity-Manager in Zusammenhang mit der Resource verwendet wird.. sollte man zu den Persistern wechseln. Events nutzen nur die Daten und Ändern sie nicht. XML-Exports, Emails, Metriken... genau hier sind Events die ideale Lösung.
An sich ist das hier vollkommen logisch und man wundert sich warum man diesen Fehler überhaupt gemacht hat.. weil man den vorher nicht gemacht hat. Deswegen sollte man im Kopf behalten, dass wenn man optionale Parameter im Methodenaufruf im REST-Controller in Spring hat, diese null als Wert haben können müssen.
Einfach gesagt Integer verwenden und nicht int, weil das natürlich Probleme geben würde, wenn Spring null in einen int füllen möchte.
Ich komme ja aus der Hibernate/JPA Ecke was ORMs angeht und habe auch als eines der ersten Plugins, das die Shopware-API betraf, mir ein Plugin geschrieben das POST und PUT gleichsetzt. Am Ende sehe ich nicht nur bei ORMs sondern auch bei REST-APIs keinen Vorteil darin zwischen CREATE und UPDATE beim Aufruf zu unterscheiden. Intern kann immer noch geprüft werden, ob eine Id gesetzt ist oder NULL/0 ist. Ich wurde CRUD eher durch ein RSD (READ SAVE DELETE) ersetzen. Welche Art von SAVE dann API intern ausgeführt wird, muss den Benutzer der API nicht interessieren.
Wenn die verwendete ID ein Business-Key ist hat es auch den Vorteil, dass man nicht bestimmen muss, ob man beim Speichern CREATE oder UPDATE aufrufen muss. Bei einem einheitlichen SAVE funktioniert es einfach und erspart viel Kommunikation mit dem Server.
Das ganze nur mal so zwischen durch... wollte ich nur mal sagen und nicht immer nur denken.
Mein 2. Shopware Plugin (also.. das 2. das in den Community-Store soll..) ist jetzt so gut wie fertig. Es fehlen nur noch ein paar Test und Dokumentation.
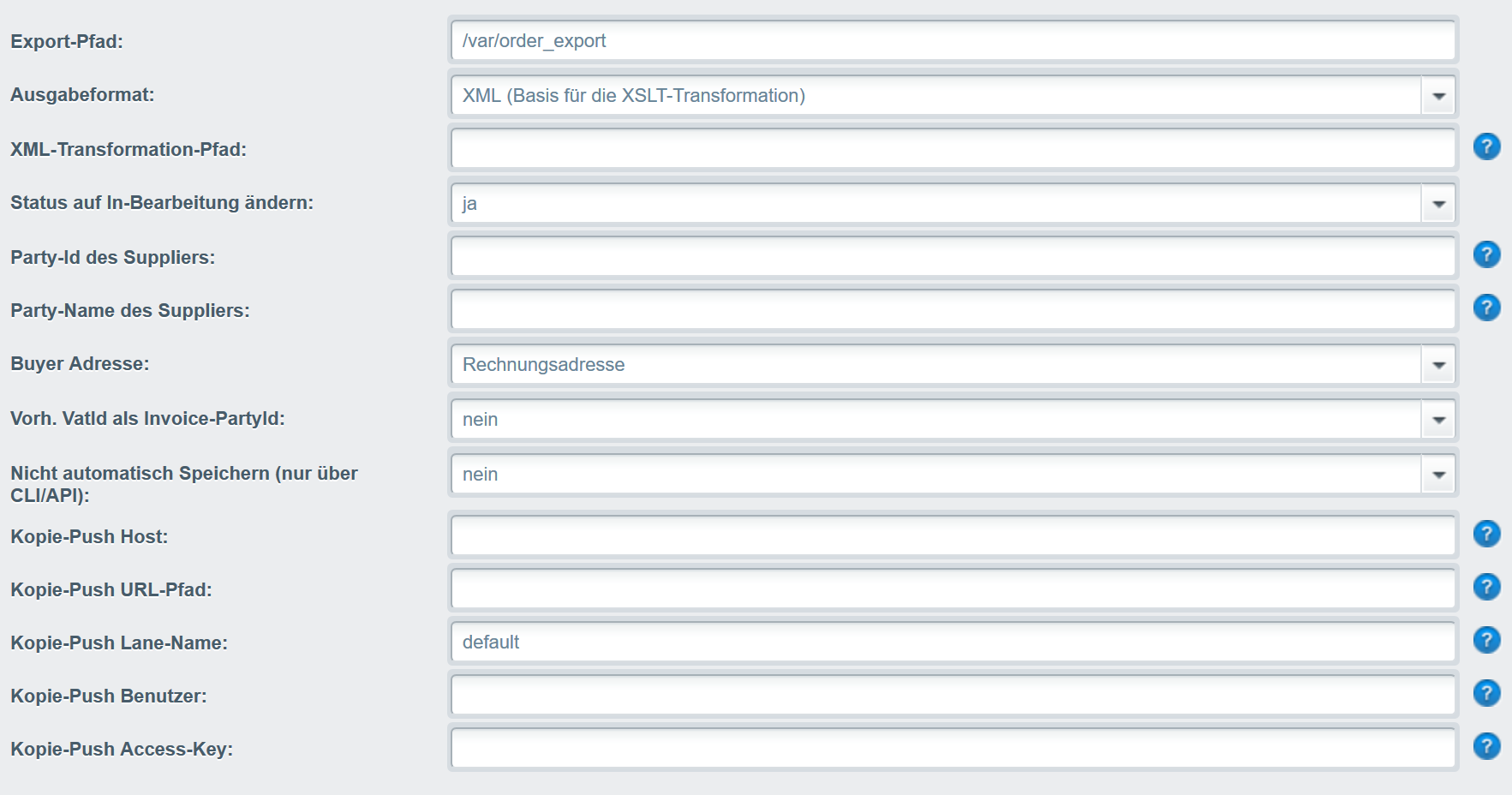
Das Plugin stellt einen Export der Orders bereit. Im Gegensatz zu den eingebauten Export hat man hier ein paar mehr Möglichkeiten das Aufgabeformat (so lange es XML ist) anzupassen und alles zu automatisieren.
Features:
- XML Formate: nativ, openTRANS 1.0 (eher experimentell), openTRANS 2.1
- automatischer Export direkt nach der Bestellung als Datei in ein lokales Verzeichnis
- automatischer Export als XML in einem JSON Container per Push (getestet mit einem Wildfly 11 und einem RestEasy Endpoint)
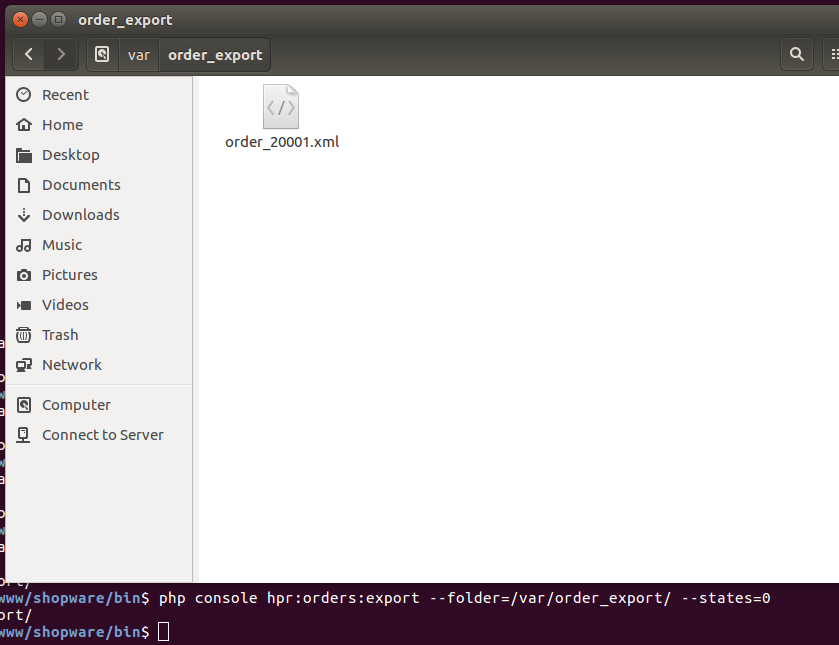
- Export bestimmter Orders in ein Verzeichnis per CLI
- Abfrage über die REST-API
- REST-API: Als XML in einem JSON-Container (Liste und einzelnd)
- REST-API: Als XML (einzelnd)
- XSLT-TRansformation, damit ist man im Ausgabeformat nicht eingeschränkt (egal ob mit Automatisch, CLI oder REST-API)
- Für die openTRANS-Formate gibt es verschiedene Einstellung für Buyer-Definition und die Party-Ids
Es ist also ein Plugin was rein auf die Integration von Shopware in vorhandene Bestell-Prozesse mit ERP-Systemen wie SAP ausgelegt ist. Arbeit wirklich gut mit Java Application Servern wie Wirldfly zusammen und auch zum Debuggen ist es sehr praktisch die Bestellungen als XML zu dumpen.
Ein relativ alter Fork des Plugin wird bei https://www.notebookswieneu.de genutzt, um die Bestellungen als openTRANS 1.0 an das SAP-System
zu übermitteln.
Diese Woche werden die letzten Dinge erledigt und dann wird es hoffentlich Anfang nächster Woche für den Store eingereicht.
Ich hatte einfach keine Lust eine neue Modul-Version in meinen lokalen 10er zu basteln. Also auch wenn man seit JBoss 7 an sich Pause hatte und erst jetzt wieder mit WildFly 10 angefangen hat... es sind immer noch genau die selbe Art von Problemen die einen Ärgern.
Wenn man mit JSON arbeitet, hat man auch manchmal das Problem, das eine JSON Nachricht nicht umgewandelt werden kann oder eine Nachricht in einem kaputten Format am Client ankommt.
Dann hilft meistens ein Validator um heraus zu bekommen was an dem Format gerade nicht stimmt. Teilweise ein Komma zu wenig oder eine Klammer zu viel. Wenn man versuchen würde das in einem Texteditor oder in der einzeiligen Darstellung im Webbrowser zu finden, kann man sehr lange suchen. Bei solchen Problemen hilft diese kleine Webapplikation sehr:
Auch wenn man JSON per PHP per Hand zusammen stückelt falls man eine automatische Umwandlung verwenden kann, ist sie sehr hilfreich für schnelle Tests zwischendurch.
Auch im ZF1 ist es sehr einfach einen REST-Service zu implementieren.
public function restAction(){
$this->getHelper('Layout')->disableLayout();
$this->getHelper('ViewRenderer')->setNoRender();
$this->getResponse()->setHeader(
'Content-Type', 'application/json; charset=UTF-8'
);
$data=............;
echo json_encode($data);
return;
}
Man muss nur das Layout und den ViewRenderer deaktivieren und schon kann man sein Response ganz nach Belieben gestalten. Das Vorgehen über das Response als return Wert im Zend Framework 2 finde ich aber insgesamt klarer und strukturierter als die Art und Weise um ZF1.
REST mit dem Zend Framework 2 soll ganz einfach gehen. Geht es auch. Bestimmt gibt es viele verschiedene Möglichkeiten, aber diese scheint erstmal ganz gut zu funktionieren. Den XWJSONConverter hatte ich shcon in einem vorherigen Blog-Post vorgestellt. Man kann natürlich auch JSON:encode aus dem ZF2 verwenden oder json_encode().
class IndexController extends AbstractRestfulController{
private function _getResponseWithHeader(){
$response = $this->getResponse();
$response->getHeaders()
//make can accessed by *
->addHeaderLine('Access-Control-Allow-Origin','*')
//set allow methods
->addHeaderLine('Access-Control-Allow-Methods','POST PUT DELETE GET')
//change content-type
->addHeaderLine('Content-Type', 'application/json; charset=utf-8');
Ich stand mal vor dem Problem, dass ich wie in AngularJS einen REST-Service mit JavaFX abfragen wollte. Es sollte asynchron laufen und dabei die Oberfläche nicht blockieren, so dass alles noch sehr "responsive" auf dem Benutzer wirkt.
REST-Services sind ja nicht mehr neu und haben gerade die klassischen WebServices (SOAP) an vielen Stellen ersetzt. Wer mal mit SOAP, auch auf einen niedrigeren Level, gearbeitet hat, wird dies nicht als Verlust sehen. Es gibt viele Frameworks für REST-Services und auch lassen sich die meisten anderen Frameworks ohne Probleme so anpassen, dass sie keine HTML-Seite zurück liefern sondern das Ergebnis als JSON. XML wäre auch möglich als Ausgabeformat, aber ist sehr sehr wenig verbreitet. XML ist meistens sehr viel größer, da "name":"value" viel kürzer ist als <name>value</name> oder <attribute name="name" value="value"/>.
Meine Erfahrungen mit dem Parsen von XML und JSON in PHP ist aber, dass beide eigentlich gleich schnell sind. Ein Wechsel bei Config-Files von XML auf JSON hat keine Verbesserung der Ladezeiten ergeben. Auch die Serialisierung von Objekten bei Java war mit JSON nur minimal schneller als mit XML, wobei es dort auch sehr vom Verwendeten Framework abhängig war. Also kann es sein, das es in neueren PHP-Versionen doch Unterschiede geben wird, wenn dort noch mehr optimiert wird.
Mit das größte Problem auf dass ich bei REST-Services in PHP gestoßen bin ist das Parsen der URLs. Hier besteht einfach das Problem, dass es immer viele Methoden pro Service gibt und das einlesen der Mapping-Patterns somit doch relativ aufwendig sein kann. Während man in einem Java-Servlet nur einmal am Anfang alles parsen muss, muss man in PHP bei jeden Request von vorne beginnen. Eine Lösung wäre das Speichern der Ergebnisse in der Session, wobei hier dann aber das Problem bleibt, dass man bei Änderungen diese erkennen und den Inhalt der Session erneuern muss. Man kann das XML als String lesen und einen MD5-Hash bilden. Damit könnte man verschiedene Versionen des Services in der Session identifizieren. Am schönsten wäre natürlich den Zugriff auf das Dateisystem komplett einsparen zu können, aber dass scheint erstmal so nicht machbar zu sein.
Das Gleiche gilt auch für das Objekt, dass die Methoden enthält auf die die URLs gemappt werden. Man muss sich auch deutlich machen, dass ein REST-Service im Grunde kein Konstrukt der objekt-orientierten Programmierung ist, sondern die Facade im Grund klassischen prozedualen Prinzipen folgt. Gerade wenn man Sicherheits-Token und so verwendet und nicht die Session für die Speicherung des eingelogten Benutzer verwendet, merkt man dass man auch ohne Klasse mit einfachen functions hier genau so gut arbeiten könnte. Aber wir verwenden eine Klasse, die den Service beschreibt, um auch keinen Stilbruch zu haben. Ein Objekt zu erzeugen ist teuer und theoretisch könnte man sich dieses hier ersparen.
Mein AFP2-Framework benutzt die selben Klassen wie mein älteres aoop-Framework. Es implementiert momentan noch kein wirkliches Routing sondern nutzt einfach Regex-Ausdrücke um die gesamte URL mit einem Match auf die richtige Methode zu mappen. Hier wird also einfach von oben nach unten die Liste durch laufen und immer ein preg_match durchgeführt. Routing mit beliebig tiefer Verschachtelung und Sub-Routen, würde hier viel Zeit ersparen, da damit die Anfangs-Liste relativ klein wäre und schnell abzuprüfen wäre und erst dann in der nächsten Liste weiter geprüft wird. Das kommt dann später nochmal um etwas schneller zu werden.
Wie man erkennt wird im service-Tag die Klasse angeben, auf die die URLs gemappt werden sollen. Das Mapping der einzelnen Methoden wird dann innerhalb genauer definiert. Jede Method einen grundlegenden Pattern, der für ein Match auf die URL verwendet wird. Wenn dieser passt wird versucht die Argument (die Reihenfolge in der XML muss der Reihenfolge in PHP entsprechen!) aus der URL oder dem Request zu rekonstruieren. Jedes Argument kann ein eigenes Pattern haben. Wenn es ein Request-Value ist, entspricht das Pattern dem Namen im Request. Sollte kein Pattern angeben sein, wird dass Pattern der Method verwendet. Das erspart viel Text, weil man so nur ein allgemein gültiges Pattern schreiben muss. Mit group wird die Gruppe beim preg_replace angeben. Also die die den benötigten Wert enthält, der als Argument übergeben werden soll. Im Pattern der Method können also schon alle Werte in Gruppen markiert werden und bei den Arguments muss immer nur noch angegeben werden, welche Gruppe verwendet werden soll.
URLs zu REST-Services folgen in aoop und APF2 folgender Regel:
http://..../rest/{modulename}/.....
Über den Modul-Namen wird gesteuert welche rest.xml geladen wird. /rest/ ist die Markierung, dass hier ein REST-Service angesprochen werden soll. Der Rest der URL kann nach Belieben definiert werden.
Für unser Beispiel wäre z.B. folgende URL lauffähig:
Das Ergebnis der Methode wird dann in JSON umgewandelt und auch der Header entsprechend auf "text/json" gesetzt.
Damit lässen sich nun pro Modul REST-Services definieren und deployen. Bei PHP hat man zum Glück nicht das Problem, dass sich ändernde Klasse von anderen REST-Services anderer Module zu Laufzeitfehlern führen können. Wenn man ein Modul ändert, wird die Klasse ja beim nächsten Request erneut geladen und nicht wie bei Java in der VM gehalten. Probleme kann es nur geben, wenn man die Session verwendet und versucht dort gespeicherte serialisierte Daten einer alten Version in ein Objekt der neuen Version der Klasse zu deserialisieren.
Das macht diese Umgebung in PHP für Microservices interessant. Da man hier wirklich einzelne Module zur Laufzeit austauschen kann, ohne dabei die anderen Module zu beeinflussen (wenn man natürlich vorher drauf geachtet hat, dass Klassen, die auch von anderen Modulen verwendet werden, nicht zu Fehlern bei diesen führen). Zu überlegen wäre auch diese Klassen zwischen den Services als JSON und nur über eine URL dem anderen Service verfügbar zu machen. Also die URL auch zu Intra-Service Kommunikation zu verwenden.
Und den JSON-String dann auf eine eigene Klasse zu mappen. So etwas werde ich für die nächste Version dann einbauen.
Das war jetzt ein grober Überblick wie meine Frameworks REST-Services implementieren und versuchen dabei möglichst flexibel zu sein, aber auch nicht dabei zu sehr auf Kosten der Performance zu arbeiten. Die Arbeiten an APF2 sind noch in Gange und deswegen kann sich da auch noch einiges Ändern und vielleicht lerne ich von anderer Seite noch einiges, wie sich auch die letzten Probleme lösen lassen, um so REST-Services noch besser implementieren zu können.
Lange Jahre war aoop mein CMS und PHP-Framework für die meisten Projekte, die etwas mehr brauchten als nur JavaScript. Es begann als CMS für meine Homepages. Deswegen unterstützte es die Verwaltung von Pages, konnte mit einer Installation mehrere Domains bedienen und verhielt sich dabei jeweils wie eine komplett eigene Installation. Benutzer-Verwaltung und Logins waren mit im Kern implementiert. Es konnten Module erstellt und für jede Instanz einzelnd deployed werden (jede Instanz konnte sogar eine eigene Version haben, da man später auch pro Instanz eine eigene Datenbank verwenden konnte). Es wurde zu einem doch sehr großem System Vergleich mit einem einfachen kleinen App-Server. Ein Server und eine Installation für alles. Module und Pages wurden immer wieder direkt eingelesen und Menüs automatisch erstellt. Also Modul rein kopieren und damit stand es gleich zur Verfügung.
In letzter Zeit ging ich aber auch dazu über für jeden Bedarf eine eigene Installation mit eigener Datenbank anzulegen, da man bei Problemen so nur eine Installation anfassen musste und bei Updates nur eine Seite für paar Minuten anfassen musste. Die letzten Projekte waren auch Web-Apps die das Framework nutzen aber die Verwaltungsfunktionen des CMS-Teils nicht benötigten. Das Framework ist gut und ich komme damit super zurecht, aber für Web-Apps war dies alles nur Ballast. Web-Apps bestehen auch bei mir momentan aus AngularJS und einem REST-Service. Der REST-Service-Teil von aoop ist relativ neu und nutzt nur wenige andere Klassen des Kern-Systems. Dann kam ich noch mit dem Zend Frameworks in Berührung, die viel hatten, was mir in aoop noch fehlte (Seiten-Aufrufe über URL-Parsing und so.. was aber für die REST-Services schon existierte).
Ich überlegte also mal den REST-Teil heraus zu lösen, um einfacher meine Apps bauen zu können. Ein Problem bei den Apps waren aber die Auslegung auch von AngularJS auf OnePage-Apps. Beruflich hatte ich mit Clients von einem ERP-System zu tun, die nicht ein paar Views und Dialoge hatten sondern pro Modul gerne mal 50 oder mehr und im Client waren auch gerne mal 20 Module installiert. So eine Anzahl an Views und Controllern ist für eine einfache AngularJS-Anwendung zu viel. Also kam ich auf die Idee jeden View/Dialog und seinen Controller als einzelne Komponente zu betrachten und weiterhin Seiten per Request aufzurufen, aber in diesen die Oberfläche aus fertigen Komponenten zusammen zu stellen. Das Laden der Daten und auch Speichern und so sollte die Komponenten dann nur über REST erledigen. Im Grund ein System für 2 Schichten einer 3 Schichten Architektur. REST und Client-View Erzeugung in einem System zusammen gefasst.
Also habe ich mir meine Ideen mal aufgeschrieben und dann angefangen es umzusetzen. Einiges wurde direkt aus aoop übernommen (was auch weiter existieren wird für normale Homepages und so etwas, wo man eben ein CMS braucht). Class-Loader ist eine 1:1 Kopie wo nur ein paar Pfade angepasst wurden.
Damit fing die Entwicklung dann auch an. Class-Loader, neue Modul-Klasse und Klasse zum einlesen aller installierten Module. Dann wurde der REST-Service-Teil kopiert wobei nur ein Klasse ersetzt werden musste, weil eben die Modul-Liste geändert hatte. Damit liefen die REST-Services auf jeden Fall schon mal wieder. PDBC für Datenbankzugriffe musste auch nur
Kopiert werden.
Dann folgte der Teil wo aus Komponenten eine Seite zusammen gebaut werden sollte. Diesmal sollte erst die Page geladen und erzeugt werden bevor angefangen wird das Template zu füllen, was den Vorteil hat, dass jede Seite ihren <title> selbst bestimmen kann und man damit sehr viel flexibler ist. Bei einer Blog-Anwendung können also auch Tags mit in den Title geschrieben werden, obwohl das Template auch für Übersichten und so verwendet werden kann. Also am Ende werden Platzhalter ersetzt.. um es mal genauer zu erklären.
Das URL-Schema ist eigentlich das des REST-Teils geworden:
Also Basis-URL, dann folgt der Type an dem entschieden wird ob eine Page oder ein Service gemeint ist, dann der Modulname und nun folgt etwas beliebiges, das durch das Routing oder Mapping der entsprechenden Teile des Frameworks interpretiert wird und am Ende auf einen Service oder eine Page zeigt.
Meine Planung für den Blog ist momentan, dass ich parallel zur Entwicklung ein paar Beiträge schreibe:
* Class-Loader
* REST-Service
* Pages und Komponten
* ein kleines Beispiel
* Zugriff auf Datenbank und automatisches Mapping von Resultsets auf Objekte
Es ist ein kleines Framework an dem man eigentlich leicht verstehen sollte wie man so etwas bauen kann und wie man bestimmte Dinge darin umsetzen kann (nicht muss.. aber meiner Erfahrung nach funktionieren die Dinge sehr gut :-) )
Nachdem ich mich in den letzten Tagen irgendwie mehr wieder Services und Service-Strukturen
gedanklich beschäftigt habe (in Staus hat man viel Zeit für so etwas), habe ich mal angefangen in paar kurzen Gedanken zusammen zu fassen, wie ich mir eine Umgebung vorstelle, mit der man sehr flexibel und fehler-tollerant arbeiten und entwickeln kann.
Es geht hier hauptsächlich um REST-Services, die man z.B. von einer AngularJS Anwendung oder einen Java-Desktop-Client Aufruft. Oder auch REST-Services die zwischen Servern zur Kommunikation verwendet werden.
Wichtig dabei ist auf jeden Fall, dass man Config-Dateien an einem separaten Ort ablegen kann. Also getrennt vom Service-Code, so dass man ohne Probleme eine neue Version deployen kann, ohne sich darum Gedanken machen zu müssen, ob man die Config überschreibt oder eine für ein falsches System darin enthalten sein kann. Die Anpassung des Services wird extern von der Umgebung gemanagt.
Sollte keine eigene Config-Datei vorhanden sein, sollte der deployte Service mit default Einstellungen laufen.
Die Umgebung sollte einen Service deployen, undeployen und pausieren können. So dass man einen Service für Wartungen deaktivieren kann und das System Anfragen entweder so lange hält (bis der Service wieder da ist oder eine Timeout kommt) oder eine allgemeine Antwort zurück liefert, die dem Anfragenden darüber informiert, dass der Service zur Zeit nicht verfügbar ist.
Es sollte auch ein Reload eines Services möglich sein, um z.B. geänderte Config-Daten zu erkennen. Da würde ja ein Call auf eine Methode des Service-Objekts reichen, dass in einem bestimmten Interface vorgegeben wird.
Wenn man eine große Anwendung hat, muss man früher oder später die Services auch untereinander kommunizieren lassen. Konzept wie @ejb halte ich für zu unflexibel, da man direkte Pfade und so berücksichtigen muss. Ein Service sollte intern einen selbst gewählten eindeutigen Namen haben. Der alleine reicht um einen Service anzufordern. Da wird dann aber auch nicht ein Interface un eine Proxy-Klasse zurück geliefert sondern ein Descriptor-Objekt, dass angibt ob der Service verfügbar ist und die Root-URL. Es müsste auch eine Version mit in der Anfrage nach dem Service sein, um zu verhindern, dass Dependencies ein nicht handhabbares Problem werden. Wenn man die Verfügbarkeit über das Objekt prüft, wird immer der aktuelle Status des Services ermittelt.
Man kann also Versionen abhängige Logiken implementieren, falls der eigene Service sich mit einer aktuelleren Version anders verhalten sein, weil die vielleicht eine bessere Methode für irgendwas hat. Sollte ein Service gar nicht vorhanden sein oder plötzlich offline gehen, muss man gucken, ob meinen Fehler zurück liefert oder eine Fallback-Lösung bemüht. Wenn man z.B. einen zentralen Logging-Service verwendet und dieser während der Laufzeit in den Wartungsmodus versetzt wird, könnte man für die Zeit auf eine eigene Datei-basierte Lösung zurück greifen, bis der Logging-Service wieder verfügbar ist.
Die Umgebung hat ein zentrales Verzeichnis mit allen deployten Services. Man könnte überlegen, dass dieses Verzeichnis die Request nicht nur auf die Objekte mapped sondern auch auf andere Server weiterleiten könnte, so dass man Services sogar über verschiedene Server verteilen kann,
aber für den Client weiterhin einen zentralen Aufrufpunkt hat.
Auch könnte man implementieren, dass ein Service eine asynchrone Nachricht an das System schickt und die Nachricht dann an jeden Service verteilt wird.
Wichtig wäre bei der Kommunikation zwischen Services auf jeden Fall, dass Requests es auch asynchron bearbeitet werden können. Also das z.B. bei unserem Logging-Service zwar die Verfügbarkeit geprüft wird dann aber nach dem Fire-And-Forget Prinzip weiter verfahren wird. Ansonsten ist es auf der Service-Seite gerade mit inter-Service Kommunikation es wohl meistens einfacher synchron zu arbeiten. Auf Client-Seite sollte man ja asynchron arbeiten, da es die UX sehr verbessert.
DataSources und Transaction-Management sollte auch von der Umgebung alles bereit gestellt und verwaltet werden. In der Config-Datei für einen Service trägt man dann ein "verwende DataSource 'CRM_ARTICLES'". Der Service alleine darf sich selbst keine Datenbankverbindungen erstellen.
Mit soetwas sollten sich auch größere Anwendungen mit getrennten Modulen/Services entwickeln lassen ohne zu schnell in Probleme zu laufen.. natürlich nur wenn man die Möglichkeiten nutzt und nicht versucht am System vorbei Dinge zu erledigen. Ob so ein System für solche Service-Module performant realisieren kann, müsste man einfach mal ausprobieren.. wenn man die Zeit dafür hätte. In Java sollte sich so etwas gut Umsetzen lassen. In PHP sehe ich viele Probleme, weil man keine zentralen Application-Scope oder so hat.
Wenn man sich etwas mit JavaScript beschäftigt und auch sich mit Java gut auskennt, lernt man schnell die Vorteile von nicht statischen Typen zu schätzen (kein aufwendiges Parsen und Casten bei REST-Operationen auf Basis von JSON, etc). Aber manchmal fehlen Typen und so doch etwas.. hier wird sehr gut erklärt wie man moderne und struktirierte JavaScript Anwendungen schreibt, die wartbar beleiben und auch in Unternehmen dann vielleicht akzeptiert werden.
AngularJS, require.js, JQuery, TypeScript, Bower.. wird alles mal kurz angesprochen und erklärt.
zum Jahres Ende kommt mal ein Update von aoop auf 0.6, was sich jetzt immer mehr zur Middleware für JS-Webapps entwickelt. Die Neuerungen sind:
* mehr Singletons für bessere Performance
* seperates Theme für das Admin-Panel einstellbar
* REST-Services Unterstützung im Kernsystem (definierbar über module/desploy/rest.xml)
* Login Sicherheit (Sperrung für 5min nach 3 gescheiterten Loginversuchen)
* Begonnen requireJS für JS-Module zu integrieren
* schon mal der Begin einer Entwickler-Dokumentation um selbst aoop als Middleware zu verwenden.
Neben bei entsteht ein eigenes kleines JS-Framework, das Controller-Objekte für Views und passendes Databindung ermöglicht. Kein Templating.. dafür aber sehr klein und Übersichtlich. Erste Test-App gibt es schon damit:
 bezahlt von
bezahlt von  Blog: Blog-entries by search-pattern/Tags:
Blog: Blog-entries by search-pattern/Tags: