Ich mag PHP. Ich mochte PHP schon zu PHP4- und PHP5-Zeiten, obwohl da Performance und Typisierung wirklich nicht immer so toll waren. Aber es gab einen großen Vorteil, im Vergleich zu Java (Tomcat + JSP/JSF/Servlets), den man konnte einfach eine Datei ändern und F5 drücken. Dann war die Änderung direkt zu sehen. Das Betraf auch nciht nur einfache Controller und Views sondern auch DB-Connections, Caches und andere Dinge bei denen man normaler Weise den Java Servlet-Controller hätte neustarten müssen. Dieser Luxus wurde sich eben dadurch erkauft, das es keinen Application-Scope oder komplexes Connection-Pooling in PHP gab. Aber dafür ersparte man sich nicht-funktionierende Hot-Deploys und Restart-Zeiten der Serverumgebung.
Nun soll es einen PHP Preload-Cache geben, wobei die Kompilierung des PHP-Codes nur noch beim Serverstart erfolgen soll: A server restart will be required to apply the changes. Damit werden dann einige (die ersten) Seitenaufrufe schneller, weil dann dort das Kompilieren entfällt. Bei Blogs oder one-page Lösungen sehe ich da keinen wirklichen Vorteil. Die Kompilierungszeiten mit PHP 7 sind wirklich schnell geworden, so das auch der erste Aufruf der 90% der Anwendung kompilieren würde bei dem normalen OpCache, gefühlt nur minimal langsamer wäre als die weiteren Aufrufe. Der absolute Nachteil wäre, das man den Server wegen jeder Änderung neustarten müsste. Also würde man sich Scripte schreiben, die das Starten und Kompilieren für einen übernehmen. Dann noch WebPack und man hat einen Workflow, der genau so komplex ist wie bei Java-Projekten (nur dass dort mit Maven alles zentraler geregelt wird).
Was habe ich also am Ende. Komplexität, Deployment-Zeiten, eine immer noch nicht ganz so überzeugende Performance, kein Multithreading, keinen Application-Scope und kein Connection-Pooling für Datenbankverbindungen. Also alles was an Java nicht so toll ist und keinen der Vorteile von Java.
Besonders, wenn man immer mehr in die Richtung geht einen HTML5+JS Client mit einer REST-API/Middleware anstelle klassischer MVC-Modelle zu nutzen, wären die F5-Vorteile von PHP wirklich toll gewesen.
Wer also sehr komplexe Seiten mit vielen vielen verschiedenen Views hat, der kann Vorteile durch einen Preload-Cache haben. Bei allem anderen sollte der OpCache allein noch die Performance bestimmen.
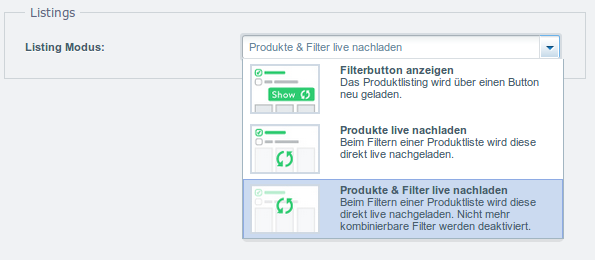
Unter den Performance-Einstellungen findet man die Einstellungen zu Filter. Leider beeinflussen diese Einstellungen nicht nur die Performance, sondern auch dass Verhalten des Filters.
Filterbutton anzeigen: Es wird erst einmal ein Button mit der Anzahl der Treffer angezeigt. Um diese zu sehen muss man auf den Button klicken. Es müssen also keine Ansichten gerendert werden, die dann vielleicht nur 1s sichtbar sind, bis der Filter vom Benutzer wieder geändert wird. Man erspart sich also viele unnötige Render-Aktivitäten.
Wenn ich bei Webcams sowohl "720p" und auch "1080p" auswähle, werden mir alle angezeigt, die zu einem der Werte passen.
Produkte live nachladen: Wie oben nur das die Ergebnisse nicht erst einmal als Zahl da gestellt werden sondern direkt als Listing gerendert werden. Erhöht also die Last auf dem
Server.
Produkte & Filter live nachladen: Hier ist das wichtige der kleine Satz "Nicht mehr kombinierbare Filter werden deaktiviert." Das bedeutet nämlich, dass wenn ich "720p" auswähle, dass Geräte mit dieser Eigenschaft angezeigt werden und nur noch Filter möglich sind, die auf die geladene Liste anwendbar sind. Also wird "1080p" direkt deaktiviert. Ich kann die Liste durch eine zusätzliche Auswahl also nicht mehr erweitern, die bei den anderen Modi. Wenn ich mir jetzt alle Tablets mit "m3", "i3" und "64GB" sowie "128GB" SSD anzeigen lassen möchte, habe ich bei diesen Modus ein Problem.
Warum der 3. Modi bei den Performance-Einstellungen zu finden ist und nicht in den Grundeinstellungen, ist hier etwas seltsam. Klar kann man dann keine riesigen Ergebnismengen mehr bauen, aber ein kartesisches Produkt sollte nicht das Problem sein oder man müsste einen 4. Modi mit diesem Verhalten aber mit Button implementieren.
Und das ist dann der Punkt an dem ich wieder anfange daran zu zweifeln, dass ORMs wirklich für mehr als load-by-id, update, insert oder delete brauchbar sind.
Gefühlt liefern ORMs bei Performance-Fällen immer nur Lösungen, die man mit nativen Queries schon von sich aus hätte und das ORM nur zusätzlichen Overhead ohne Vorteil verursacht.
Nachdem ich im letzten halben Jahr mit Neo4j und nun auch mit Elasticsearch zu tun hatte, bin ich was NoSQL-Datenbanken angeht etwas zwiegespalten. Graphen-Datenbanken sind toll um Beziehungen zwischen Entitäten abzubilden. Dokumenten-orientierte Datenbanken wie Elasticsearch ideal um unstrukturierte Daten zu speichern und neben der eigentlichen Abfrage auch z.B. Durchschnittswerte oder Übersichten von der Abdeckung von bestimmten Attributen/Feldern gleich mit abzufragen.
Die Abfragen sind schnell. Aber.. auch sind die Queries komplexer (Neo4j) bis sehr viel komplexer (Elasticsearch). Der Vorteil der NoSQL Datenbanken ist, dass man schon fertige Objekte zurück bekommt und man nicht auf Tabellenstrukturen beschränkt ist. So kann man also Listen mit Objekten die zu einer Entität gehören gleich mit abfragen und erspart sich ein zweites Query und zusätzliches Mapping.
Aber sind die NoSQL Datenbanken wirklich so viel schneller, wie man immer hört? Dafür muss man verschiedene Dinge bedenken. Zuerst ob die Datenbank die primäre Datenquelle ist oder nur zusätzlich zu einem RDBMS verwendet wird. Ich hatte bis jetzt nur mit zusätzlichen Datenbanken zu tun. Deren Daten wurden durch Cronjobs aus dem RDBMS gelesen, aufbereitet und dann in die NoSQL-Datenbank geschrieben.
Entweder per CSV-Import (Neo4J) oder direkt über die REST-API (Elasticsearch). Die gleichen Abfragen waren in der MySQL-Datenbank langsamer. Nicht viel langsamer. Aber es war doch spürbar und lagen bei der Neo4J bei so 30%-40%.
Wenn man nun aber einberechnet wie viel Aufwand der Import darstellt, der bei beiden Anwendungsfällen zwischen 1,5-5min lag, sieht es schon sehr viel anders aus. Die Importscripte reduzierten die Datenmenge natürlich sehr extrem und schrieben nur die nötigsten Daten in die NoSQL-Datenbanken. Bei der Neo4J waren es wirklich nur Ids und Relationen. Die Elasticsearch hatte alle elementaren Felder und auch Unterobjekte, die bei SQL über Joins geladen werden würden. Auf dieser reduzierten und stark vereinfachten Datenbasis waren die Abfragen sehr schnell.
Wenn man mit ein paar SQL-Statements die selben Daten in der MySQL in dem selben Umfang in eigene Tabellen schreibt, ist die MySQL Datenbank meiner Erfahrung nach genau so schnell. Im Vergleich von MySQL und Neo4J muss man sagen, dass für die Abfragen plötzlich viel mehr Daten zur Verfügung stand und diese auf genutzt wurden. Außerdem wurden doppelt so viele Queries verwendet. Am Ende war die MySQL-Lösung langsamer aber auch sehr viel komplexer und in dem Sinne besser.
Ich für meinen Teil sehe in den NoSQL-Datenbank nur einen Vorteil, wenn man die Vorteile derer auch nutzt. Wenn ich keine Graphen brauche, brauche ich auch keine Neo4J-Datenbank. Habe ich nur Entitäten und DTOs die ich schnell speichern und laden möchte, brauche ich keine Elasticsearch. Elasticsearch ist komplex und kann ein paar wirklich interessante Dinge durch deren Aggregations. Wenn ich haufenweise unterschiedliche Daten aus vielen verschiedenen Quellen zusammen fahren möchte bin ich mit Elasticsearch gut beraten. Aber wenn ich nur Geschwindigkeit haben möchte muss ich nur die Datenbasis verringern und vereinfachen. Neo4J ist auch extrem Speicher hungrig. Was bringt es mir wenn ich 96GB an RAM brauche um das zu machen was ich mit 32GB und einer MySQL oder einer Oracle-DB genau so schnell hinbekomme. Wenn ich dann sehr viel RAM habe und ganze Datenbanken im Speicher halten kann, habe ich die selbe Geschwindigkeit und bin mit der größeren Datenbasis sehr viel flexibler. Außerdem ist alles schneller und sicherer was ich direkt innerhalb der Datenbank machen kann. Ein Import von der MySQL in die Neo4J brauchte viel darum herum um sicher zu sein. In einer Oracle würde alles sowie so in einer Transaction laufen, die auch nicht noch den Server der das Script startet belastet.
Wer also in seinem RDBMS Performanceprobleme hat, soll sie auch dort lösen und nicht glauben, dass ein weiteres System anzubinden (und synchron zu halten) dieses Probleme lösen würde.
Ich habe MP4toGIF.com in den letzten Tagen immer mal wieder in Vivaldi getestet. Das WebM-Rendering ist extrem schnell und ich habe noch mal einen Bugfix für den FileSaver eingebaut.
Oft werden NoSQL für sehr spezielle Fälle eingesetzt. Die normale Datenhaltung bleibt weiter hin den SQL-Datenbanken überlassen. Also müssen regelmäßig die Daten aus dem SQL-Bestand in die NoSQL Datenbank kopiert werden. Das dauert oft und viele aufbereitungen der Daten wird schon hier erledigt. die NoSQL Varianten sind deswegen auch oft schneller, weil man eine Teil der Arbeit in den Import-Jobs erledigt, die sonst bei jedem Query als Overhead entstehen. Natürlich haben die NoSQL auch ohne das ihre Vorteile, aber man sollte immer im Auge behalten, ob die Performance von der Engine kommt oder auch von der Optimierung der Daten, weil die Optimierungen der Daten könnte man auch in die SQL-Struktur zurück fließen lassen und diese in die Richtung hin verbessern.
So ein Import dauert... wenn man in der Nacht ein Zeitfenster von einer Stunde hat, ist alles kein Problem. Will man aber auch in kurzen Abständen importieren, muss der Import schnell laufen. Auch wenn man als Entwickler öfters mal den Import braucht, ist es wichtig möglichst viel Performance zu haben.
Hier geht es darum wie man möglichst schnell und einfach Daten aus einer MySQL Datenbank in eine Neo4j Graphen-Datenbank importieren kann, ohne viel Overhead zu erzeugen. Ich verwende hier PHP, aber da an sich keine Logik in PHP implementiert werden wird, kann man ganz leicht auf jeden andere Sprache, wie Java, JavaScript mit node.js und so übertragen. Es werden keine ORMs verwendet (die extrem viel Overhead erzeugen und viel Performance kosten) sondern nur SQL und Cypher.
Wie man einfach sich eine oder mehrere Neo4J-Instanzen anlegt (unter Linux) kann man hier sehr gut sehen:
Wir verwenden bei Neo4j den Import über eine CSV-Datei. Wir werden also nicht jeden Datensatz einzeln Lesen und Schreiben, sondern immer sehr viele auf einmal. Ob man alles in einer Transaktion laufen lässt und erst am Ende commited hängt etwas von der Datenmenge ab. Bis 200.000 Nodes und Relations ist alles kein Problem.. bei Millionen von Datensätzen sollte man aber nochmal drüber nachdenken.
PERIODIC COMMIT ist da eine super Lösung, um alles automatisch laufen zu lassen und sich nicht selbst darum kümmern zu müssen, wann commited wird. Alle 1000 bis 10_000 Datensätze ein Commit sollte gut sein, wobei ich eher zu 10_000 raten würde, weil 1000 doch noch sehr viele Commits sind und so mit der Overhead noch relativ groß ist.
Unsere Beispiel Datenbank sieht so aus:
CREATE TABLE USERS(
USER_ID INT(11) UNSGINED NOT NULL,
USER_NAME VARCHAR(255) NOT NULL,
PRIMARY KEY (USER_ID)
);
CREATE TABLE MESSAGES(
MESSAGE_ID INT(11) UNSIGNED NOT NULL AUTO_INCREMENT,
MESSAGE_TITLE VARCHAR(255) NOT NULL,
FROM_ID INT(11) UNSIGNED NOT NULL,
TO_ID INT(11) UNSIGNED NOT NULL,
CC_ID INT(11) UNSIGNED NOT NULL,
PRIMARY KEY (MESSAGE_ID)
);
Wir legen uns 50.000 User an dann noch 100.000 Messages mit jeweils einen FROM, einem TO und einem CC (hier hätte man über eine Link-Table sollen, aber das hier ist nur ein kleines Beispiel, wo das so reicht). Das sollten erst einmal genug Daten sein. (Offtopic: da ich das gerade neben bei auch in PHP schreibe.. warum kann ich für eine 100000 nicht wie in Java 100_000 schreiben?)
Die erste Schwierigkeit ist es die Daten schnell zu exportieren. Ziel ist eine CSV. Wir könnten entweder über PHP die Daten lesen und in eine Datei schreiben oder aber einfach die OUTFILE-Funktion von MySQL nutzen, um die Datenbank diese Arbeit erledigen zu lassen. Wir werden es so machen und erstellen für jede Art von Nodes und Relations eine eigene CSV. Weil wir Header haben wollen fügen wir diese mit UNION einmal oben hinzu
$sql="
SELECT 'user_id', 'user_name'
UNION
SELECT USER_ID,USERNAME
FROM USERS
INTO OUTFILE ".$exchangeFolder."/users.csv
FIELDS TERMINATED BY ','
ENCLOSED BY ''
LINES TERMINATED BY '\n'
";
Damit schreibt MySQL das Ergebnis des Queries in die angegebene Datei. Falls ein Fehler auftritt, muss man gucken, ob der Benutzer unter dem die MySQL-DB läuft in das Verzeichnis schreiben darf und ob nicht eine Anwendung wie apparmor unter Linux nicht den Zugriff blockiert. Es darf keine Datei mit diesen Namen schon vorhanden sein, sonst liefert MySQL auch nur einen Fehler zurück. Wir müssen
die Dateien also vorher löschen und dass machen wir einfach über PHP. Also muss auch der Benutzer unter dem die PHP-Anwendung läuft entsprechende Rechte haben.
Man kann das gut einmal direkt mit phpmyadmin oder einem entsprechenden Programm wie der MySQL Workbench testen. Wenn die Datei erzeugt und befüllt wird ist alles richtig eingestellt.
Mit dem Erstellen der CSV-Datei ist schon mal die Hälfte geschafft. Damit der Import auch schnell geht brauchen wir einen Index für unsere Nodes. Man kann einen Index schon anlegen, wenn noch gar kein Node des Types erstellt wurde. Zum Importieren der User benutzen wir folgendes Cypher-Statement:
$cyp="USING PERIODIC COMMIT 10000
LOAD CSV WITH HEADERS FROM "file:///".$exchangeFolder."/messages.csv" AS row
MERGE (m:message{mid:row.msg_id,title:row.msg_title});";
Der Pfad zur Datei wird als File-URL angegeben. Hier merkt man auch Neo4J seine Java-Basis an. Wenn man mal in eine Temp-Verzeichnis schaut sieht man dort auch Spuren von Jetty.
Am Ende wird der Importer nur eine Reihe von SQL und Cypher Statements ausführen. Wir benötigen um komfortabel zu arbeiten 3 Hilfsmethoden. Dass alles in richtige Klassen zu verpacken wäre natürlich besser, aber es reicht zum erklären erst einmal ein Funktionsbasierter Ansatz.
Da MySQL keine Dateien überschreiben will, brauchen wir eine Funktion zum Aufräumen des Verzeichnisses über das die CSV-Dateien ausgetauscht werden. Wir räumen einmal davor und einmal danach auf. Dann ist es kein Problem den Importer beim Testen mal mittendrin zu stoppen oder wenn er mal doch mit einem Fehler abbricht.
function cleanFolder($folder){
$files=scandir($folder);
foreach($files as $file){
if(preg_match("/\.csv$/i", $file)){
unlink($folder."/".$file);
}
}
}
Für Neo4J bauen wir uns eine eigen kleine Funktion.
use Everyman\Neo4j\Client;
use Everyman\Neo4j\Cypher\Query;
$client = new Everyman\Neo4j\Client();
$client->getTransport()->setAuth("neo4j","blubb");
function executeCypher($query){
global $client;
$query=new Query($client, $query);
$query->getResultSet();
}
Der Rest ist nun sehr einfach und linear. Ich glaube ich muss da nicht viel erklären und jeder Erkennt sehr schnell wie alles abläuft. Interessant ist wohl das Cypher-Statement für die Receive-Relations, da neben der Relation diese auch mit einem Attribute versehen wird im SET Bereich.
//clear for export (if a previous import failed)
cleanFolder($exchangeFolder);
//export nodes
echo "create users.csv\n";
$sql=" SELECT 'user_id', 'user_name' UNION
SELECT USER_ID,USER_NAME
FROM USERS
INTO OUTFILE '".$exchangeFolder."/users.csv'
FIELDS TERMINATED BY ','
ENCLOSED BY ''
LINES TERMINATED BY '\n'";
$db->execute($sql);
echo "create messages.csv\n";
$sql=" SELECT 'msg_id', 'msg_title' UNION
SELECT MESSAGE_ID, MESSAGE_TITLE
FROM MESSAGES
INTO OUTFILE '".$exchangeFolder."/messages.csv'
FIELDS TERMINATED BY ','
ENCLOSED BY ''
LINES TERMINATED BY '\n'";
$db->execute($sql);
//export relations
echo "create relations_etc.csv\n";
$sql=" SELECT 'user_id', 'msg_id', 'type' UNION
SELECT TO_ID, MESSAGE_ID, 'TO'
FROM MESSAGES
UNION
SELECT CC_ID, MESSAGE_ID, 'CC'
FROM MESSAGES
INTO OUTFILE '".$exchangeFolder."/relations_etc.csv'
FIELDS TERMINATED BY ','
ENCLOSED BY ''
LINES TERMINATED BY '\n'";
$db->execute($sql);
echo "create relations_from.csv\n";
$sql=" SELECT 'user_id', 'msg_id', 'type' UNION
SELECT FROM_ID, MESSAGE_ID, 'FROM'
FROM MESSAGES
INTO OUTFILE '".$exchangeFolder."/relations_from.csv'
FIELDS TERMINATED BY ','
ENCLOSED BY ''
LINES TERMINATED BY '\n'";
$db->execute($sql);
//create indexes for fast import
echo "create index's in neo4j\n";
$cyp="CREATE INDEX ON :user(uid);";
executeCypher($cyp);
$cyp="CREATE INDEX ON :message(mid);";
executeCypher($cyp);
//import nodes
echo "import users.csv\n";
$cyp="USING PERIODIC COMMIT 10000\n
LOAD CSV WITH HEADERS FROM "file:///".$exchangeFolder."/users.csv" AS row\n
MERGE (u:user{uid:row.user_id,name:row.user_name});";
executeCypher($cyp);
echo "import messages.csv\n";
$cyp="USING PERIODIC COMMIT 10000
LOAD CSV WITH HEADERS FROM "file:///".$exchangeFolder."/messages.csv" AS row
MERGE (m:message{mid:row.msg_id,title:row.msg_title});";
executeCypher($cyp);
//import relations
echo "import relations_from.csv\n";
$cyp="USING PERIODIC COMMIT 10000
LOAD CSV WITH HEADERS FROM "file:///".$exchangeFolder."/relations_from.csv" AS row
MATCH(u:user{uid:row.user_id})
MATCH(m:message{mid:row.msg_id})
MERGE (u)-[r:send]->(m);";
executeCypher($cyp);
echo "import relations_etc.csv\n";
$cyp="USING PERIODIC COMMIT 10000
LOAD CSV WITH HEADERS FROM "file:///".$exchangeFolder."/relations_etc.csv" AS row
MATCH(u:user{uid:row.user_id})
MATCH(m:message{mid:row.msg_id})
MERGE (m)-[r:receive]->(u)
SET r.type=row.type;";
executeCypher($cyp);
//clear after import
cleanFolder($exchangeFolder);
Hier sieht man wie der Importer die 50.000 User, 100.000 Messages und insgesamt 300.000 Relations von einer MySQL in die Neo4J Instanz importiert.
Die Festplatte ist nur über SATA-2 Angeschlossen und nicht besonders schnell. Eine SSD, wie für Neo4J empfohlen, würde alles sehr beschleunigen.
Zum Löschen aller Daten aus der Neo4J kann man diese Statement verwenden:
Auch heute in Zeiten von JSON und XML ist einer der Haupt Import- und Export-Formate immer noch CSV. Der Vorteil ist eben, dass es sich einfach erstellen lässt, einfach einlesen und zur Kontrolle in einem Texteditor laden lässt. Excel kann es auch irgendwie und OpenOffice bzw LibreOffice kann super damit umgehen.
Meistens erstellt man die Dateien ja in dem man Daten aus der Datenbank lädt und dann das Resultset durchläuft und direkt ausgibt oder in einen String schreibt, den man in eine Datei schreibt. Der Vorteil ist, dass man die Daten noch mal bearbeiten kann. Aber wenn man nicht zu komplexe Bearbeitungen vornehmen will und man diese auch mit SQL erledigen kann, gibt es auch die Möglichkeit CSV-Dateien direkt in der Datenbank (hier MySQL) zu erstellen.
Gerade wenn man die Datei nicht ausgeben will über eine PHP Datei sondern sie direkt in einer Verzeischnis kopiert (auch über FTP oder SSH) und die Datei dann von dort von einem anderen System eingelesen wird (z.B. von Neo4J.. so bin ich darauf gekommen) ist dieses Vorgehen sehr viel performanter (gerade wenn OR-Mapper im Spiel sind) als das normale Vorgehen.
SELECT ID,NAME
FROM TEST
WHERE ID>5
INTO OUTFILE '/var/www/app/data/export/out_test.csv'
FIELDS TERMINATED BY ','
Wenn man das FILE-Right hat, kann man so eine CSV in ein beliebiges Verzeichnis schreiben.
Man muss nur sicher stellen, dass man die nötigen Rechte im Verzeichnis hat und dass keine Programme wie apparmor das Schreiben verhindern. ERRCODE 13 wäre der Fehlercode der in so einem Fall angezeigt werden würde.
Wenn man nun alle Rechte erteilt hat und es nicht geht und apparmor läuft, kann man kontrollieren, ob MySQL davon überwacht wird.
sudo aa-status
Um den Zugriff auf das Verzeichnis zu erlauben muss man folgendes tun. Man muss /etc/apparmor.d/usr.sbin.mysql.d bearbeiten und einfach den Pfad an die vorhanden anfügen. Dann mit noch mal apparmor neu laden und es sollte gehen.
Immer wenn ich jemanden Fragen höre "Weißt du, was der Unterschied zwischen einfachen und doppelten Anführungszeichen in PHP ist?" Denke ich immer: "Gleich.. gleich kommt es wieder mit der Performance". Und es kommt immer die selbe Antwort am Ende raus, dass doppelte Anführungszeichen langsamer sein als die einfachen.
Ich habe es getestet und die doppelten waren meistens minimal schneller, aber nicht so sehr dass man nicht sagen kann, dass eine der beiden Varianten schneller als die andere wäre. Der Opcode sieht auch gleich aus. Die meisten vergessen einfach dabei, dass auch bei PHP der Code erst einmal geparst und optimiert wird und dann erst der erzeugte Opcode ausgeführt wird. Bei der Ausführung hat sich das mit den verschiedenen Anführungszeichen schon erledigt, weil String intern immer gleich abgebildet werden.
Also wenn keine Variablen im String vorkommen, macht es keinen Unterschied, welche Art von Anführungszeichen verwendet werden. Und der Punkt als Concat-Zeichen schneller ist als Variablen direkt im String anzusprechen ist wieder eine andere Frage.
Ein wenig besinnliches zu Weihnachten. Performance-Analyse auf Oracle Datenbanken. Wenn man heraus finden will welche SQLs viel Zeit verbrauchen, kann man das Query hier verwenden. Es ist ein erster Ansatz und keine absolute Lösung. Aber wenn man Probleme hat, ist es ein guter Einstieg in die Analyse.
select ROUND(disk_reads/decode(executions,0,1,executions)/300) EXTIME, SQL_TEXT
from v$sql
where disk_reads/decode(executions,0,1,executions)/300 >1
and executions>0
order by (disk_reads/decode(executions,0,1,executions)/300) DESC
Oft hilft es am Ende einfach einen Index zu setzen. Aber manchmal muss man tiefer in die Materie gehen.
Bei Java ist es ja bekannt dass man setAccessible(true) setzen sollte, wenn man mit Reflections arbeitet. Deswegen habe ich mich gefragt, ob es bei PHP genaus so ist und ob man auch hier einen Unterschied feststellen kann. Ich kam zu folgenden Ergebnis beim lesen eines public Properties in iner Klasse:
100000x: 0.061945 (accessible nicht geändert)
100000x: 0.036735 (accessible=true)
Der Unterschied fällt nicht immer so stark aus, aber ist doch immer sehr deutlich.
Und weil ich schon mal dabei war hier ein Vergleich für 10000 Durchläufe von serialize() und json_encode():
serialize: 0.05022
json_encode: 0.027367
und einmal wieder zurück:
unserialize: 0.047767
json_decode: 0.03802
Wenn man also vorhat ein Objekt oder sogar mehrere irgendwo zwischen zu speichern, sollte man überlegen ob nicht eine JSON-Codierung die bessere Wahl ist. Es werden natürlich nur die public Felder mit json_encode gelesen. Hier muss man einfach von Fall zu Fall gucken was besser passt.
preg_match und strpos sind nicht ganz so spannend:
Irgendwann kommt der Zeitpunkt, da ist eine Anwendung langsam. Es liegt nicht am Datenbankserver oder der Netzwerkanbindung oder der Auslastung des Servers. Es liegt einfach ganz allein daran, dass die Anwendung langsam ist.
Oft findet man einige Dinge von selbst heraus. Aber oft ist man einfach überfragt in welchen Teilen der Anwendung die Zeit verloren geht. Was braucht lange? Werden einige Dinge unnötig oft aufgerufen? Zu viele Dateisystem-Zugriffe?
Hier hilft dann nur noch ein Profiling der Anwendung. Profiling ist einfach die Anwendung eine Zeit lang zu überwachen und zu protokollieren, wie viel Zeit in der Zeit auf welche Methoden oder Funktionen verwendet wird.
Das alleine sagt natürlich erstmal nicht wo Probleme vorhanden sind. Deswegen halte ich die Idee ein separate Team solche Performance-TEst durch zu führen und zu analysieren für nicht ganz so zielführend. Denn manchmal brauchen einige Methoden viel Zeit. Da man Zeit sowie so meistens nur in Verhältnis der Methoden zu einander betrachtet muss man wissen was schnell sein soll und was langsam sein sollte oder darf.
Ich hatte mal bei Bouncy Dolphin das Problem, dass alles an sich ganz schnell lief, aber beim Profiling auf eine Methode fast 40% der Zeit ging, die nur den aktuellen Punktestand auf das Canvas zeichnete. Nach viel hin und her Probieren kopierte ich den Inhalt eines Canvas mit dem Punktestand auf das Haupt-Canvas. Das Canvas mit dem Punktestand wurde nur neu gezeichnet wenn sich der Punktestand auch änderte. Danach verbrauchte die Methode nur nach 15%. Also war es schneller das gesamte Canvas zu kopieren als eine oder zwei Ziffern zeichnen zu lassen.
document.getElementById["aaaaa"].value=score verursacht z.B. auch extrem hohe Kosten. Also immer alle wichtigen Elemente in Variablen halten und nicht jedesmal neu im Document suchen!
Wärend man in Java extrem mächtige Tools wie VisualVM hat und der Profilier des Firefox oder Chrome einem bei JavaScript Problem sehr gut hilft, ist die Situation bei PHP etwas umständlicher. Zwar kann man so gut wie immer XDebug verwenden, aber so einfaches Remote-Profiling wie mit VisualVM ist da nicht zu machen.
Aber da man meistens sowie so lokal auf dem eigenen PC entwickelt und testet, reicht es die Daten in eine Datei schreiben zu lassen und diese dann mit Hilfe eines Programms zu analysieren.
Aber ich habe bis jetzt WinCacheGrind verwendet. Damit ließen sich nach etwas Einarbeitung dann schnell heraus finden, wo die Zeit verloren ging und welche Methoden wie oft aufgerufen wurden.
Der Class-Loader durchsuchte das System-Verzeichnis zu oft, weil an der Stelle nicht richtig geprüft wurde, ob die Klasse schon bekannt war. So konnte ich die Ladezeit einer Seite in meinem Framework am Ende nach vielen solcher Probleme von 160ms auf ungefähr 80ms senken. Viel Caching kam auch noch dazu und das Vermeiden von Zugriffen auf das Dateisystem.
Aber es gibt noch andere Profiler als XDebug für PHP. Hier findet man eine gute Übersicht:
PHP Profiler im Vergleich
Ich hab schön öfters gehört, dass solche Test und das Profiling ans Ende der Entwicklung gehören und man so etwas nur macht wenn man keine andere Wahl hat. Aber am Ende findet man viele Fehler dabei und ich halte es für falsch nicht schon am Anfang zu testen ob eine Anwendung auch später mit vielen produktiven Daten noch performant laufen wird. Denn am Ende sind grundlegende Fehler in der Architektur schwerer und auf wendiger zu beheben als am Anfang oder in der Mitte der Entwicklung.
Nachträglich an einzelnen Stellen Caching einzubauen ist auch nicht so gut wie von Anfang an ein allgemeinen Caching-Mechanismus zu entwerfen, der an allen relevanten Stellen automatisch greift.
Deswegen sollte man auch schon ganz am Anfang immer mal einen Profiler mitlaufen lassen und gucken, ob alles so läuft wie man es sich dachte.
Lange Zeit habe ich auch immer bei Columns von Datenbank-Tabellen immer ein Prefix verwendet. Die Tabelle TESTS hatte dann z.B. die Spalte TEST_ID. Daran ist ja auch erstmal nichts verkehrt. Probleme gab es mit Oracle und der Beschränkung auf 30 Zeichen für den Spaltennamen in einigen Fällen.
$entity->setId($data["TEST_ID"]);
Der Code oben funktioniert auch super, wenn man jedes Value "per Hand" in das Object schreibt.
Wenn wir aber nun ein automatisches Mapping über Annotationen nutzen kann es in einigen Fällen schnell umständlich werden.
Wenn wir keine Ableitung und Vererbung benutzen, ist auch hier kein Problem zu erwarten. Wenn wir aber eine Basic-Klasse verwenden, von der alle anderen Klassen ableiten, haben wir schnell ein Problem, weil wir in der Basic-Klasse in den Annotationen einen Platzhalter für den Prefix verwenden müssten. Ohne Prefix geht es hier sehr viel einfacher.
/**
* @dbcolumn=ID
*/
private $id=0;
/**
* @dbcolumn={prefix}_ID
*/
private $id=0;
Deswegen sollten Prefixe nur bei FKs verwendet werden, um ein automatisches Mapping unkompliziert nutzen zu können. Wenn man es jetzt nicht nutzt, will man es später vielleicht und kann dann jetzt schon alles so bauen, um später keine Probleme zu bekommen. Platzhalter funktionieren natürlich auch.. gehen aber zur Lasten der Performance.
Was haben PHP und Java gemeinsam? Deren unterste Schicht der VM/Engine ist in C geschrieben. Aber was interessiert die VM oder Engine? Irgendwann kommt man an den Punkt wo man Performance-Probleme hat und dann muss man verstehen warum etwas Langsam ist. Die Frage dann sollte auch nicht lauten: "Wie bekomme ich die Anwendung schnell?" Sondern eher: "Wie habe ich sie langsam bekommen?" Denn erstmal muss man die Gründe kennen, um dann Lösungen zu finden. Lösungen sind nicht immer so einfach zu finden, weil manche Dinge sind einfach langsam und manchmal muss man sein ganzes Vorgehen ändern. Assoc-Arrays sind toll, aber es sind eigentlich keine Array sondern Hash-Maps und die sind nun mal nicht ganz so performant.
Aber warum das so ist und warum die in PHP7 viel besser implementiert sind, erschließt sich aber nicht einfach so, wenn man nicht weiß, wie die Engine arbeitet. Auch einen Garbage-Collector gibt es in PHP, der genau wie in Java zu 98% super läuft. Aber wenn er Probleme macht, muss man wissen wie er arbeitet um ansatzweise überhaupt das Problem zu verstehen. Zirkel bei Referenzen sind ein großes Problem, wenn er die Objekte zum freigeben markieren will. Reference-Count gibt es auch dort.
Jedem der sich auch für die Interna der Zend Engine 5.x und 7 interessiert und sich etwas über Performance informieren möchte kann ich diese Artikel empfehlen:
Gerade beim Laden großer Datenmengen wie Lagerstrukturen oder bei Exporten ganzer Datenbestände, kommt man schnell in Bereiche, wo das Laden und Aufbereiten mehr als ein paar Minuten dauern kann. Bei normalen Desktop-Programmen und Skripten ist das nicht ganz so relevant. Wenn man aber im Web-Bereich arbeitet, kann es schnell zu Problemen mit Timeouts kommen. 3 Minuten können hier schon ein extremes Problem sein. Asynchrone Client helfen hier, aber keiner Wartet gerne und Zeit ist Geld.
Es gibt dann einen Punkt, wo die Zeit pro zu ladenen Element sich nicht mehr weiter verringern lässt. Hier hilft dann nur noch die Verarbeitung der einzelnen Elemente zu parallelisieren. Bei Java gibt es den ExecutorService, in JavaScript die WebWorker und in PHP gibt es pthreads. Es ist nichts für Leute mit einem Shared-Hosted Webspace, weil man eine Extension nach installieren muss.
Hier ist ein kleines Beispiel wo eine Liste von MD5-Hashes erzeugt werden soll. Die Threaded-Variante lief bei mir meistens fast doppelt so schnell
wie die einfache Variante mit der Schleife.
Man kann also auch in PHP moderne Anwendungen schrieben die Multi-Core CPUs auch wirklich ausnutzen können und muss sich hinter Java in den meisten Bereichen nicht mehr verstecken.
Profilling ist wichtig. Das klassische Rausschreiben von microtime()-Werten ist nicht wirklich verlässlich, gerade wenn das Bootstraping und die Class-Loader teilweise vorher laufen. Da bei meinem Framework die Verbesserungen in der Performance zwar immer ein wenig was brachten, aber der Rest immer noch länger dauerte als der Code vermuten lies, habe ich mal xdebug aktiviert.
Mit WinCacheGrind dann die dort erzeugte Datei nach einem Seiten-Aufruf analysiert. Es gab wirklich einen Fehler im Class-Loader der dafür sorgte, dass das system/classes/ Verzeichnis immer wieder gelesen wurde, wenn nur die Klasse noch nicht eingebunden war, aber schon der Pfad dorthin bekannt war. Dateizugriffe kosten extrem und selbst mit den PHP internen Caches sollte man so wenige wie möglich verwenden. Übersetzungsdateien werden nun in der Session gecached. Das Einlesen war auch sehr aufwendig.
Ein dummy User-Objekt versuchte, die eigenen UserGroups zu laden. Da die Id aber 0 war kam natürlich nie ein Ergebnis aus der DB, aber der Overhead wurde erzeugt. Also eine Prüfung auf id==0 und schon lief alles besser.
Meine Grundregeln sind jetzt:
* wenige Zugriffe auf das Dateizugriff
* Caching von Daten
* unnötige DB-Connections verhindern
* Objekte instanziieren kostet viel, wenn möglich SingleTons für DAOs und ToolKits verwenden
* nur laden was man braucht
* ob JSON oder XML ist am Ende nicht so wichtig, solange die Dateien keine unnötigen Daten enthalten (schnell Parsen und Cachen)
* Profilling ist wichtig und sollte man immer mal wieder machen (auch ohne konkreten Anlass)
* Das Bootstraping des Frameworks/der Anwendung muss schnell sein, der Rest liegt in der Hand des Entwicklers und er sollte so entwickeln können, also würde das Framework keine Zeit benötigen (er soll sich auf seinen Code konzentieren können)
Wichtig bei der oben gezeigten Config in der php.ini ist, dass dasVerzeichnis shon exisieren muss,da xdebug es nicht von sich auch anlegen würde.
Um Java-Anwendungen schnell zu bekommen, habe ich schon viel gelernt. Das meiste basiert darauf möglichst viel Caching zu verwenden, andere Serialisierungen (die default Serialisierung von Java ist wirklich extrem langsam), Reflections richtig zu verwenden (method.setAccessible(true)) und am Ende eigentlich so wenig neue Objekte wie möglich zu erzeugen.
Das alles ist toll, aber man muss immer daran denken, dass Datebank- und Dateizugriffe immer sehr aufwenig sind. Dafür gibt es dann Connection-Pooling und NIO.
Bei PHP ist es an sich sehr ähnlich. Nur hat man hier das Problem, dass man keinen Application-Scope hat und somit alles auch mindestes für jeden Benutzer machen muss, um es dann in der Sesion zwischen zu speichern, was am Ende wieder Serialiserung bedeutet.
Mit Aoop habe ich viel über Performance gelernt in einem Framework auf PHP gelernt. Dateizugriffe sind
das schlimmste! SingleTon-Beans helfen um global zu vermeiden oder dass man einige Dinge mehrfach durchführen muss.
Was erstaunlich schnell ist, ist die Datenbank. Natürlich abhängig von den Daten, Struckturen und Queries. In Java wird immer gesagt, man solle ORMs verwenden und dann bei Schulungen zum Thema Performance lernt man die Constructor-Queries kennen und lernt wie man mit nativen SQL arbeitet. In PHP habe ich bis jetzt nur natives SQL verwendet und kann sagen, dass selbst ohne Connection-Pooling, es oft schneller ist als ORMs/JPA in Java.
Aber Connection-Pooling mit PHP wäre echt toll. ES geht.. über Umwege. Vor ein paar Jahren hatte ich mal mit Java-Bridge herum experimentiert und da war es dann auch relative einfach (da man eben Java aus PHP heraus aufrufen kann) auf JDBC zuzugreifen oder eben auch auf das JNDI und dich dort eine DataSource vom Tomcat zu holen. Mit Quercus habe ich hier noch nicht weiter getestet, aber ich gehe mal davon aus, dass man hier sehr viel mehr Performance bekommen kann. Quercus an sich soll schnell sein und mit Connection-Pooling und NIO sollten sich Anwortzeiten und Laufzeiten stark reduzieren lassen.
Vor ein paar Tagen bin ich auf ein seltsames "Problem" gestossen. Vieleicht lag es auch an was anderen aber es hat mich irritiert.
$pattern="";
$pattern=substr($result,$from,$len);
Das obere war immer schneller als wenn ich den Substring direkt zugewiesen habe ohne die Varibale vorher zu initialisieren.
$pattern=substr($result,$from,$len);
Das finde ich seht seltsam. Entweder greift hier die dynamische Typisierung ein... oder.. keine Ahnug.. aber ich werde mal weiter nachforschen.
Auch die moderneren MySQL-Funktionen werde ich mal durch testen. Hier köntne sich auch was getan haben.
Am Ende wäre es aber natürlich toll zu sehen was PHP7 oder die HHVM bringen würden. Wenn sie halten was sie versprechen würde für Lösungen wie Java-Bridge oder Quercus nur noch das Connection-Pooling bei Datenbank-Abfragen sprechen.
Blog-entries by search-pattern/Tags:
Möchtest Du AdSense-Werbung erlauben und mir damit helfen die laufenden Kosten des Blogs tragen zu können?
 bezahlt von
bezahlt von  Blog: Blog-entries by search-pattern/Tags:
Blog: Blog-entries by search-pattern/Tags: