Das ist an sich sehr einfach, da man diese Funktion nicht erst in ExtJS einbinden muss, sondern direkt eine globale JavaScript-Variable ansprechen kann.
Ich bin bei diesen Artikel bei Heise mal wieder auf das Werben der Arbeitgeber mit Team-Events gestoßen. Dieser Kommentare zeigt aber auch, dass nicht nur ich diese Events auch skeptisch sehe.
Wahrscheinlich will die Masse der Arbeitnehmer einfach irgendwann nach Hause gehen um Zeit mit Freunden und Familie verbringen bzw. Hobbies nachgehen.
Wenn ich ein Job-Angebot mit "regelmäßigen Team-Events" sehe, bin ich eher geneigt, dieses Angebot erst gar nicht in Betracht zu ziehen. Nicht dass ich was gegen die anderen Team-Mitglieder hätte, werden schon nette Leute sein. Nur das Wort "regelmäßig" impliziert für mich, dass auch ein "regelmäßiges" Erscheinen vom Arbeitgeber erwünscht wird.
Wenn man Frau, Haus, Freunde, Familie, Privatleben, etc hat, ist es aber schon so schwer, alles in der Woche unterzubringen, was man erledigen muss. Einkaufen, Putzen, etc und am Ende soll man sich ja auch noch entspannen und für spontane Nachfragen oder Kontrollen von Änderungen von zu Hause soll man ja auch noch zur Verfügung stehen.
Wenn man Single ist und seine Wohnung nur als Ort sieht, den man zum Schlafen aufsucht und sonst seinen Lebensmittelpunkt bei der Arbeit sieht, mögen diese Events schön und toll sein. Für die meisten werden sie aber eher Zeit belegen, die man für andere Dinge gebraucht hätte.
Auf den jährlichen Weihnachtsmarktbesuch mit dem Team würde ich nicht verzichten wollen. So etwas im monatlichen Rhythmus würde ich auch ok finden, wobei ich aber eine Anwesenheitsrate von 50% schätzen würde, die ich realistisch einhalten könnte.
"Du kannst fast immer pünktlich gehen" wäre also für mich viel mehr ein Anreiz als Team-Events. Weil was bringt es mir pünktlich Feierabend zu machen und dann 4h bei einem Team-Event zu verbringen.
Das bei Webentwicklern PHP meistens hinter Java kommt ist bei dieser Statistik wieder eine andere Geschichte...
Die Differenz zwischen zwei Datumswerten in Tagen:
Java (LocalDateTime)
if(ldt1.isAfter(ldt2)){
days = Duration.between(ldt1.toLocalDate().atStartOfDay(), ldt2.toLocalDate().atStartOfDay()).toDays();
days = Math.abs(days);
}
Java (Date)
long days = TimeUnit.DAYS.convert(date.getTime() - date2.getTime(), TimeUnit.MILLISECONDS);
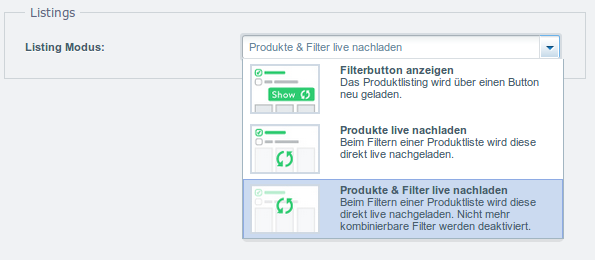
Unter den Performance-Einstellungen findet man die Einstellungen zu Filter. Leider beeinflussen diese Einstellungen nicht nur die Performance, sondern auch dass Verhalten des Filters.
Filterbutton anzeigen: Es wird erst einmal ein Button mit der Anzahl der Treffer angezeigt. Um diese zu sehen muss man auf den Button klicken. Es müssen also keine Ansichten gerendert werden, die dann vielleicht nur 1s sichtbar sind, bis der Filter vom Benutzer wieder geändert wird. Man erspart sich also viele unnötige Render-Aktivitäten.
Wenn ich bei Webcams sowohl "720p" und auch "1080p" auswähle, werden mir alle angezeigt, die zu einem der Werte passen.
Produkte live nachladen: Wie oben nur das die Ergebnisse nicht erst einmal als Zahl da gestellt werden sondern direkt als Listing gerendert werden. Erhöht also die Last auf dem
Server.
Produkte & Filter live nachladen: Hier ist das wichtige der kleine Satz "Nicht mehr kombinierbare Filter werden deaktiviert." Das bedeutet nämlich, dass wenn ich "720p" auswähle, dass Geräte mit dieser Eigenschaft angezeigt werden und nur noch Filter möglich sind, die auf die geladene Liste anwendbar sind. Also wird "1080p" direkt deaktiviert. Ich kann die Liste durch eine zusätzliche Auswahl also nicht mehr erweitern, die bei den anderen Modi. Wenn ich mir jetzt alle Tablets mit "m3", "i3" und "64GB" sowie "128GB" SSD anzeigen lassen möchte, habe ich bei diesen Modus ein Problem.
Warum der 3. Modi bei den Performance-Einstellungen zu finden ist und nicht in den Grundeinstellungen, ist hier etwas seltsam. Klar kann man dann keine riesigen Ergebnismengen mehr bauen, aber ein kartesisches Produkt sollte nicht das Problem sein oder man müsste einen 4. Modi mit diesem Verhalten aber mit Button implementieren.
Einkaufswelten im Kopfbereich von Kategorien werden mit diesem Plugin nicht nur auf der ersten Seite angezeigt, sondern auf allen. Ohne kann es ein Problem sein, dass wenn man auf z.B. ?p=2 auf einen Artikel klick und wieder zurück wechselt, die vorher (bei Infinite Scrolling) noch angezeigt wurde, nicht mehr sichtbar ist.
Das nur auf ?p=0 die Einkaufwelt angezeigt wird, ist fest im Code hinterlegt und nicht über das Backend konfigurierbar. Das Plugin ändert nun dieses Verhalten.
Wenn man mit Events und Hooks für Controller arbeitet, wird man oft die Request-Parameter manipulieren wollen. Wenn man aber nun einen Parameter entfernen will, muss man die setParam()-Methode verstehen, weil man sonst leicht in ein kleines Problem läuft, dass mit der getParam()-Methode zusammen hängt.
$request->setParam('sPage', null);
wird nicht funktionieren und getParam() wird den ursprünglichen Wert zurückliefern. Aber warum? Weil das Request-Object ein internes Array mit den Params beinhaltet. setParam() setzt aber den Eintrag im Array aber nicht auf null, sondern entfernt diesen aus dem Array. Soweit ok. Aber nun kommt das Problem. Wenn getParam den Key im Array nicht findet, get es auch $_GET und $_POST zurück und findet dort natürlich noch den Original-Wert von sPage und liefert den zurück.
$_GET oder $_POST kann man natürlich auch ändern.. ABER das fällt bei der automatischen Prüfung im Shopware Store auf und das Plugin wird instant abgelehnt (auch wenn $_GET in einem Kommentar steht....).
$request->setParam('sPage', 0);
So funktioniert es und durch das seltsame Casting von PHP ist 'if($request->getParam('sPage'))' dann auch false.
Wenn man mit dem XML-Parser von jcabi-xml arbeitet und der direkt am Anfang der Datei behauptet, es würde nicht nach einer XML aussehen, kann es am UTF8-BOM liegen.
Nachdem Firefox 57 meine alten Plugins entsorgt hat, brauchte ich auf die schnelle wieder ein Plugin um Xdebug triggern zu können, damit ich wieder in PHPStorm debuggen konnte. Ich bin jetzt bei diesen hier gelandet...
Wenn eine Exception auftritt oder eine Fehlermeldung kommt (egal ob per Email oder aus einem Log) ist eine Sache ganz wichtig: Ruhe bewahren!
So. Da wir nun ruhig sind, gucken wir uns die Fehlermeldung oder Exception an. Wir überlegen nicht was wir als letztes geändert haben oder welcher Klick oder welche Eingabe alles ausgelöst hat. Das wäre verschwendete Zeit, weil genau diese Info steht ja in der Fehlermeldung/Exception.
Wir lesen einmal quer rüber. Kommt uns etwas Bekannt vor? Klassennamen? Module? SQL-Statements?
Nein? Schade.. aber auch nicht so schlimm.
Wir müssen uns nur 3 Fragen beantworten:
1) Welche Daten sollten hier durch gereicht werden?
2) Wo fing es an (Ursprung der Daten)?
3) Wo wollte man hin (Ziel der Daten)?
Bei einer Nullpointer-Exception z.B. geht es darum, erst einmal heraus zu bekommen, welche Daten verloren gegangen sind.
Dann gucken wir wo die herkommen sollten und ob von dort vielleicht schon NULL her kam.
Als letztes gucken wir wo es hin sollte und ob der mit dem NULL vielleicht sogar klar gekommen wäre und der Fehler bei einem zwischen Schritt liegt oder bei so einem schon auffiel.
Am Ende bleibt nur dann zu klären, wo in dieser Kette passierte das Falsche und dann muss geklärt werden warum eben jenes passierte.
Vermuten und Eingebungen sind Teil des letzten Schrittes und nie des ersten. Aber das Wichtigste ist immer noch die Fehlermeldung/Exception auch erst einmal in Ruhe zu lesen und in ihre Teile zu zerlegen, um alle Informationen atomar vorliegen zu haben.
Alles hat nicht geholfen? Dann ist das Logging scheiße und unvollständig.. bitte das Logging verbessern :-)
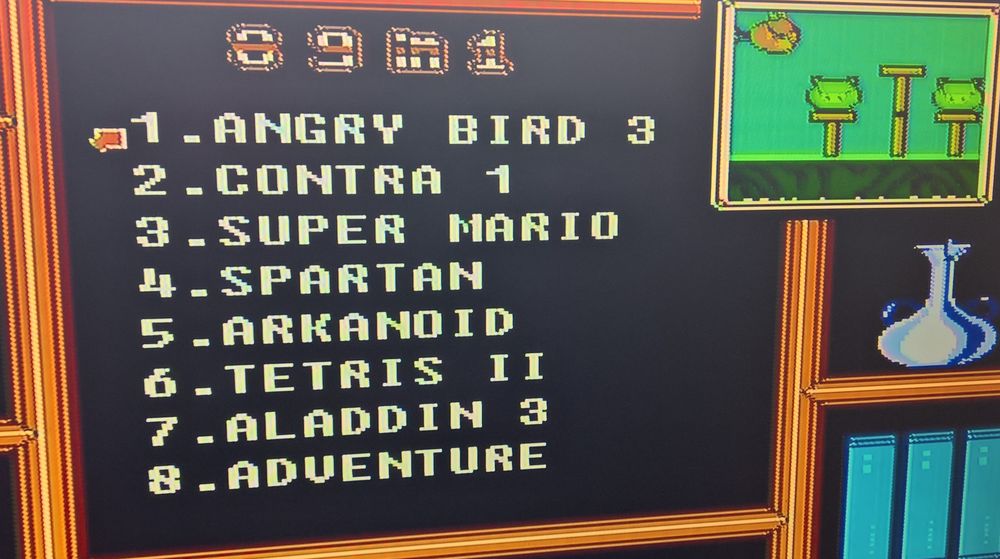
Was ist das? Es soll wohl wie ein Sonic-Kopf oder -Flügel aussehen. Man kann damit Videospiele spielen in dem man es mit einem doch ausreichend langem Kabel an die Cinch-Anschlüsse eines TV-Gerätes anschließt.
Außerdem hat es einen eingebauten Laserpointer, der sich sehr gut als Katzenspielzeug eignet. Ideale Kombination.. wenn die Katzen ankommen und nerven, weil sie glauben man will mit ihnen spielen, obwohl man eigentlich nur eine Runde Zocken will.
Die Verpackung allein ist schon Wunder moderner Designer-Albträume. Wenn man sich die angesehen hat, weiß man noch weniger was einen eigentlich erwartet. Sonic, Mega-Drive, Mario, Spongebob, eine mir unbekannte Figur die mit Photoshop "erweitert" wurde, Angry Birds, Shawn das Schaf, usw ... und endlose sich unterschiedene Aufzählungen der 4 Funktionen.. wiese sollte ich mir so ein Ding ins Auto hängen?
Man braucht nur eine AAA-Batterie und es kann losgehen. Das Batteriefach ist nicht verschraubt, was es wohl mal sein sollte, da die Bohrungen dafür vorhanden sind.
Ist es wirklich ein Mega-Drive-Clone dadrin? Würde ja zur Optik passen. 89in1 Spiele-Sammlung und es sieht eher nach einer Auswahl aus 3-4 brauchbaren Famicom Spielen aus und einer Ansammlung von Spielen, die man wohl eher gerne aus der Famicom Historie streichen würde.
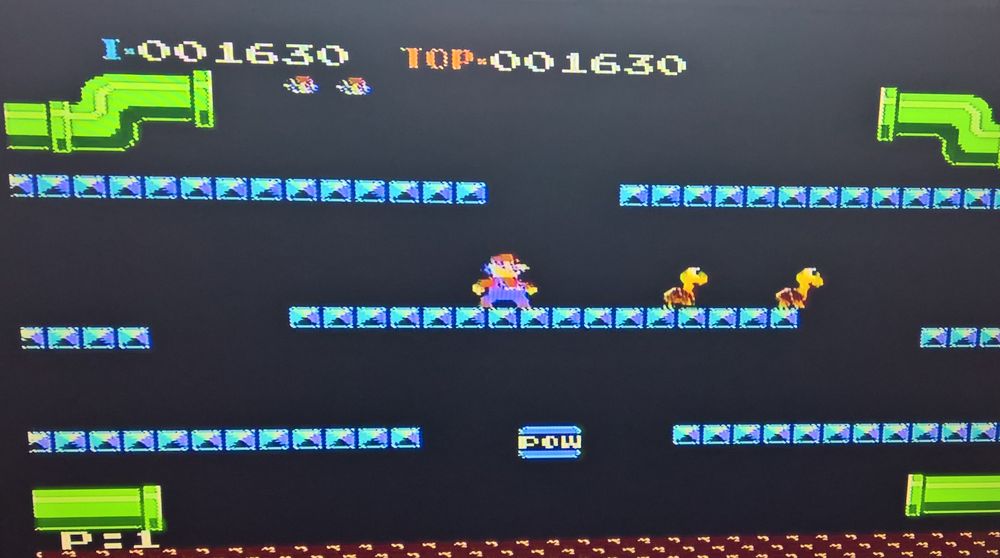
Die Grafik ist extrem matschig und unscharf. Ein NES liefert ein sehr viel besseres Bild. Oder aber es ist gewollt und man wollte nicht, dass man auf modernen Tv-Geräten die einzelnen Pixel sieht.. also eine Art Weichzeichner. Aber es ist auf den Pixel genau die NES Version von Contra/Probotector.. abgesehen von den geänderten Sprites.
Die Steuerung ist dabei sogar noch erstaunlich brauchbar. Nicht gut und das Startmenü funktioniert mehr schlechter als schlecht, aber innerhalb der Spiele (anhand von Contra getestet) ausreichend gut, um damit spielen zu können.
Ich habe sonst nur noch Mario Bros (ohne das Super vorne) ausprobiert und diese RipOffs wie "Angry Bird" ohne s komplett ignoriert. Es ist kein Turtles dabei, was neben Contra echt ein Highlight gewesen wäre.
Fazit: Für 5 Euro ist es ein lustiges kleines Spielzeug.. für Katzen und für Menschen.
Nachtrag: Super Mario Bros funktioniert wirklich gut und ist nicht merklich schlechter als auf dem NES oder Famicom
Eine wichtige Erkenntnis das Code-Element in Shopware Einkaufswelten betreffend ist, dass es Smarty unterstützt. Wer also im HTML-Teil direkt JavaScript verwenden will muss etwas mit den geschweiften Klammern aufpassen. Das gilt besonders, wenn man einfach minimized Code-Snippets von einem Anbieter in die eigene Seite integrieren möchte.
Mein 2. Shopware Plugin (also.. das 2. das in den Community-Store soll..) ist jetzt so gut wie fertig. Es fehlen nur noch ein paar Test und Dokumentation.
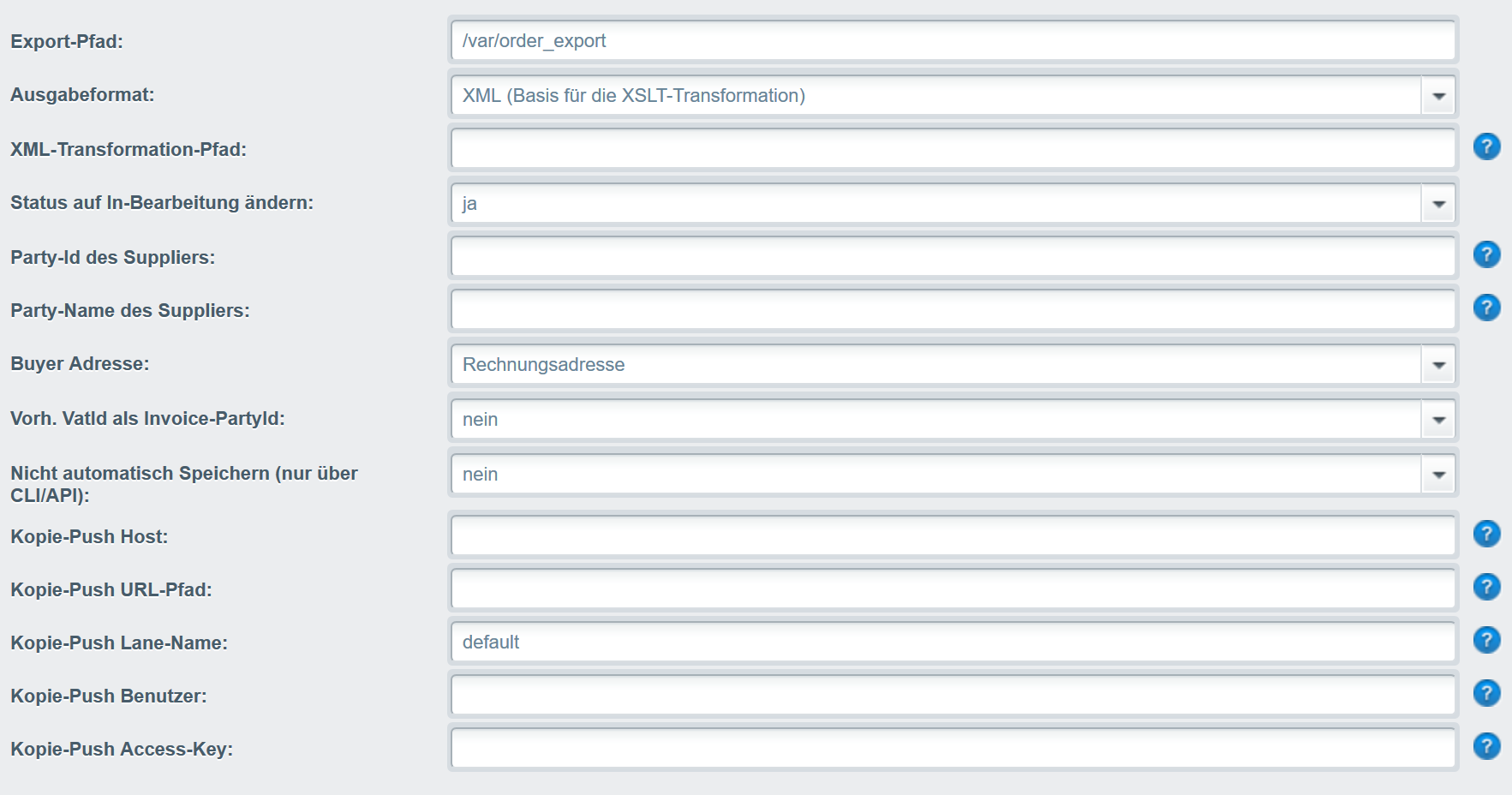
Das Plugin stellt einen Export der Orders bereit. Im Gegensatz zu den eingebauten Export hat man hier ein paar mehr Möglichkeiten das Aufgabeformat (so lange es XML ist) anzupassen und alles zu automatisieren.
Features:
- XML Formate: nativ, openTRANS 1.0 (eher experimentell), openTRANS 2.1
- automatischer Export direkt nach der Bestellung als Datei in ein lokales Verzeichnis
- automatischer Export als XML in einem JSON Container per Push (getestet mit einem Wildfly 11 und einem RestEasy Endpoint)
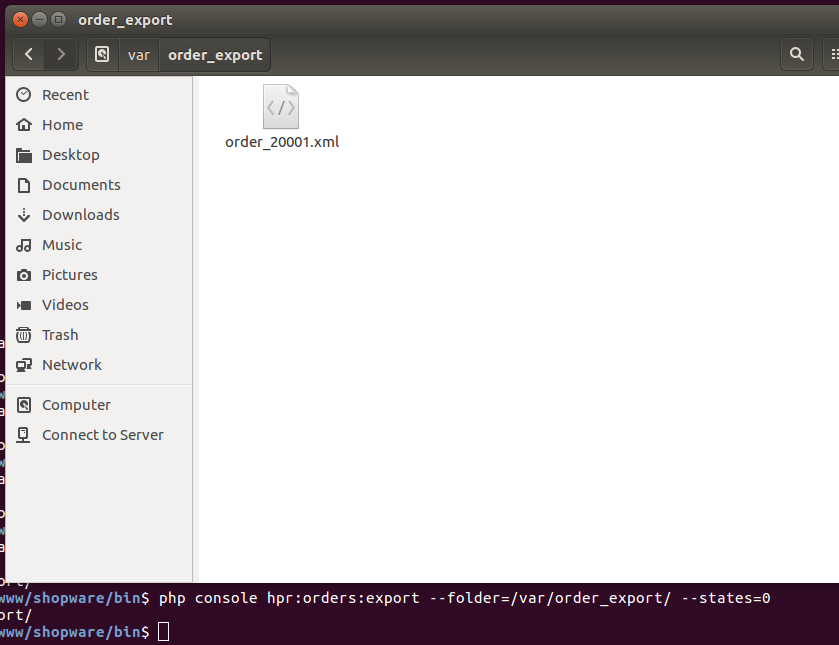
- Export bestimmter Orders in ein Verzeichnis per CLI
- Abfrage über die REST-API
- REST-API: Als XML in einem JSON-Container (Liste und einzelnd)
- REST-API: Als XML (einzelnd)
- XSLT-TRansformation, damit ist man im Ausgabeformat nicht eingeschränkt (egal ob mit Automatisch, CLI oder REST-API)
- Für die openTRANS-Formate gibt es verschiedene Einstellung für Buyer-Definition und die Party-Ids
Es ist also ein Plugin was rein auf die Integration von Shopware in vorhandene Bestell-Prozesse mit ERP-Systemen wie SAP ausgelegt ist. Arbeit wirklich gut mit Java Application Servern wie Wirldfly zusammen und auch zum Debuggen ist es sehr praktisch die Bestellungen als XML zu dumpen.
Ein relativ alter Fork des Plugin wird bei https://www.notebookswieneu.de genutzt, um die Bestellungen als openTRANS 1.0 an das SAP-System
zu übermitteln.
Diese Woche werden die letzten Dinge erledigt und dann wird es hoffentlich Anfang nächster Woche für den Store eingereicht.
Older posts:
Möchtest Du AdSense-Werbung erlauben und mir damit helfen die laufenden Kosten des Blogs tragen zu können?
 bezahlt von
bezahlt von