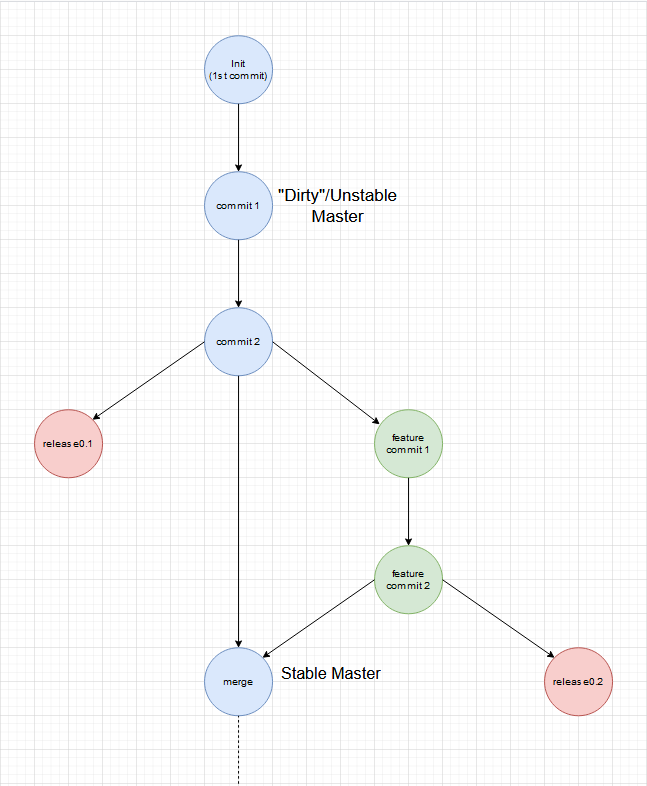
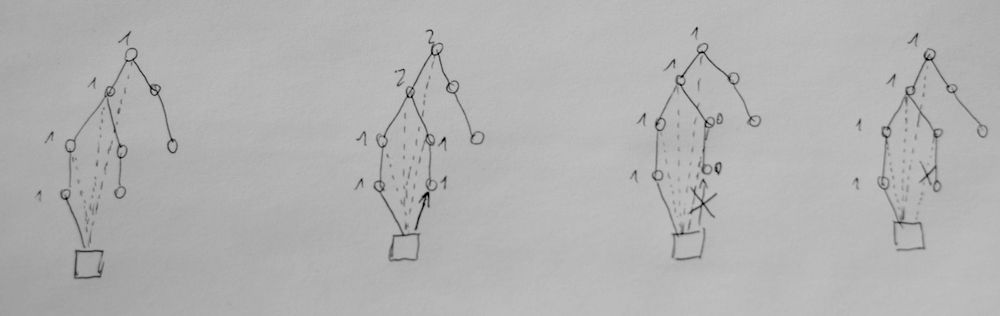
Ist es okay mit einem dreckigen Master-Branch zu starten?
Meiner Meinung nach ist es vollkommen ok. Ein leeres Projekt als stable zu deklarieren macht keinen Sinn und ist in den meisten Fällen auch nicht deploybar, da z.B. eine build.xml oder .gitlab-ci.yml noch fehlen.
Master mit dirty Commit vor dem ersten Release
Ich vertrete die Meinung, dass der Master erst nach dem ersten Release stable gehalten werden muss. Es folgt der Regel, dass im Master der letzte nutzbare Stand liegt. Wenn kein Release vorhanden ist, ist der letzte Commit der Dev-Version, die nutzbarste Version die man finden kann. In dem Sinne bemühe ich bei der Regel eine Art Fallback auf die Dev-Version, für die Zeit wo kein Release existiert. Nach dem ersten Release ist immer das letzte Release die nutzbarste Version.
Es gibt also immer eine nutzbare Version und nie "Nichts".
Am Freitag hat mir mein Kollege 2 Links zu Blogposts geschickt, die sich mit der Frage beschäftigen ob Git-Flow in der heutigen Zeit überhaupt noch funktioniert oder ob Git-Flow veraltet ist. Der 1. Blogpost zeigt erstmal nur Probleme auf und enthält keine Lösungen. Es passiert zu leicht das Release-Branches zu lange leben und dann darin selbst Entwicklung geschieht. Es dauert relativ lange bis eine Änderung durch die verschiedenen Branches im Master ankommen und am Schlimmsten ist noch, dass bei parallelen Entwicklungen ein nicht releaster Branch einen anderen aktuelleren, der einfach schneller war, blockiert.
Ja. Das ist jetzt nicht neu. Über diese Probleme habe ich 2009 schon im dem damaligen ERP-Team diskutiert (mein Gott waren wir damals schon modern...). Die Lösung hier ist einfach dass man harte Feature- und Code-Freezes braucht. Auch darf die Fachabteilung nicht erst im Release-Branch das erste Mal die neuen Features sehen. Ich habe es so erlebt. Dann kamen die neuen Anforderungen, Änderungen der gerade erst implementierten Features. Das soll aber so sein. Wenn das so ist braucht man aber auch noch das. Das ist falsch und muss so funktionieren... Alles Dinge die schon viel früher hätten klar sein müssen und erst dann hätte es zu einem Release-Branch kommen dürfen. Der Stand eines Feature-Branchs muss genau so auf einem System für Test und Abnahmen deploybar sein wie ein Release-Branch. Anders gesagt jeder Stand muss einfach immer präsentierbar sein!
Der 2. Blogpost brachte jetzt auch nicht wirklich neue Erkenntnisse, was am Ende der Author auch selbst schreibt.
Ich halte die Darstellung von Branches in parallelen Slots oder Lanes, die in dem Sinne ein Rennen um die Aktualität austragen für vollkommen falsch. Es darf auch nicht den develop-Branch oder den einen Release-Branch geben, der auch dann immer deckungsgleich mit dem Stand des Deployments auf einem System ist. In Zeiten von Docker und Reverse-Proxies zusammen mit Wildcard-Subdomains sind feste Systeme sowie so überholt. Jeder Branch kann ein System haben, auf dem Test, Abnahmen und Dokumentation stattfinden kann.
Das gilt auch für Tags. Branches sind variabel und ändern sich immer wieder. Tags sind statisch und damit perfekt für Zwecke, wo man kontrolliert bestimmte Stände deployen möchte. Tags persitieren einen bestimmten State/Zustand des gesamten Git-Repositories. Branches bilden einen State/Zustand aus der Sicht eines bestimmten Entwicklers oder eines bestimmten Features ab.
Deswegen halte ich feste Branches wie mit festen Aufgaben für komplett falsch. Ein Feature = ein Branch und am Ende steht ein Tag, der den gewünschten State/Zustand persitiert.
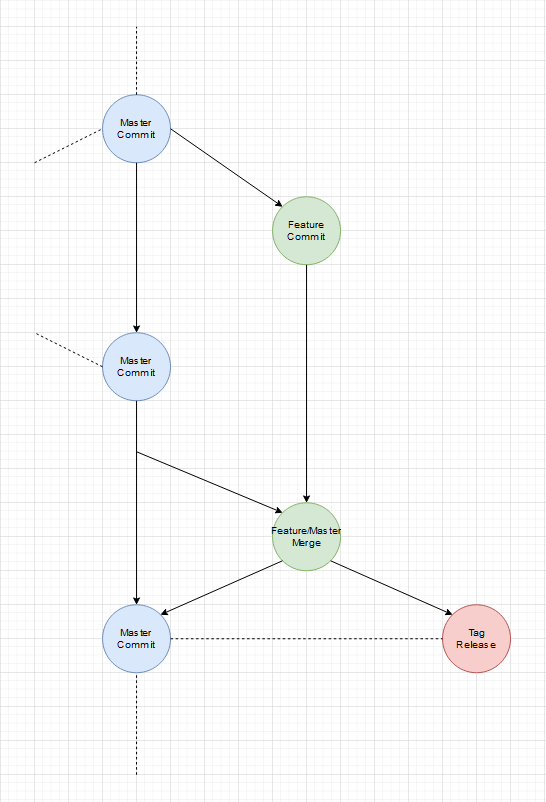
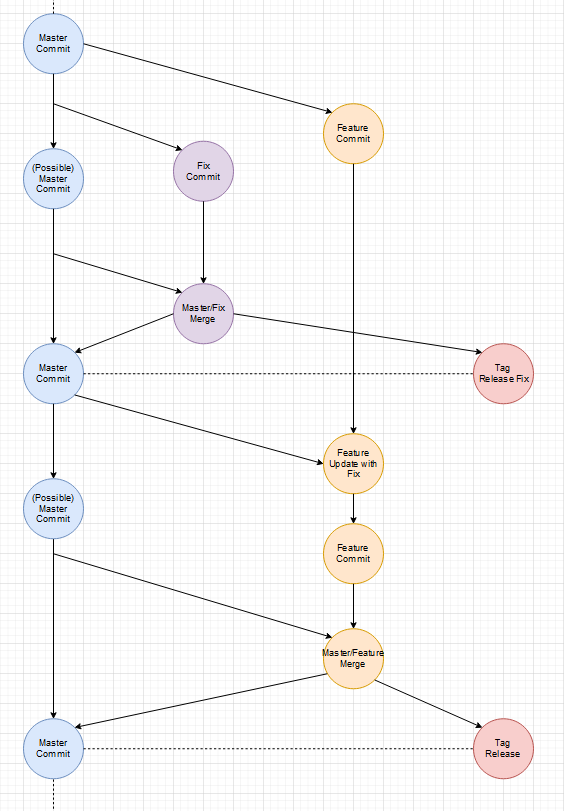
Ein einfacher Feature Branch:
Ja es gibt noch einen Master-Branch, der aber in dem Sinne nur ein 2D Abbild des wilden mehr dimensionallen Feature Raum ist. Wenn wir jeden Feature-Branch als Vektor der auf das einzelne Feature/Tag als Ziel zeigt versteht, ist der Master einfach die Projektion aller Vektoren auf eine Fläche. Diese vereinfachte Projektion hilft Feature-Branches vor dem Release auf den aktuellen Stand (was andere Features und Fixes angeht) zu bringen.
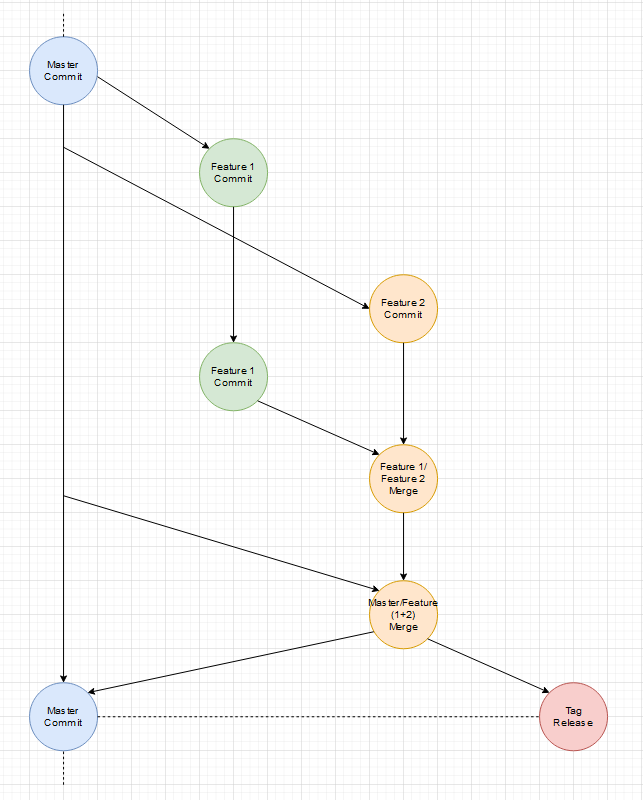
Es gibt auch immer mal Abstimmungsprobleme bei Features, die auf einander aufbauen. Interfaces haben minimale Abweichungen oder ein kleiner Satz in der Dokumentation wurde falsch verstanden. Was also wenn ein Feature doch noch eine kleine Änderung braucht, weil Entwicklungen parallel liefen?
Beides wird gleichzeitig fertig (ein extra Release-Branch wäre möglich):
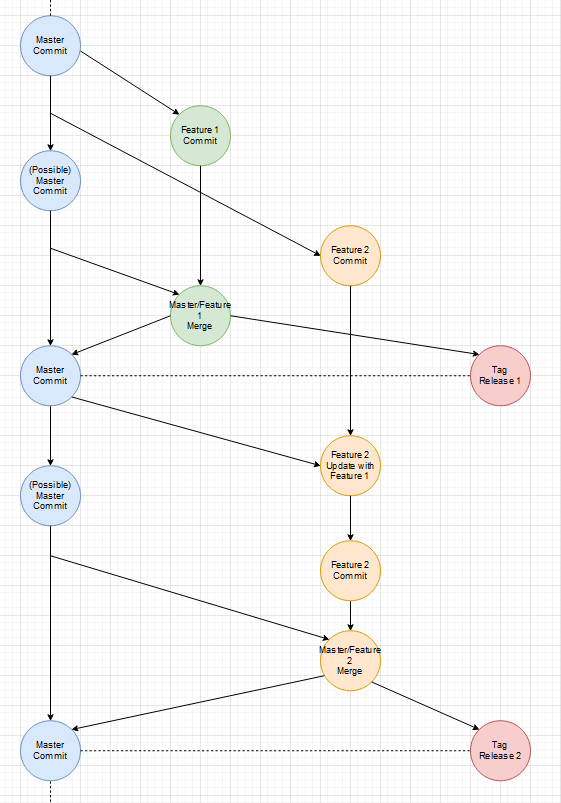
Das Basis-Feature geht vorher live:
Das bessere und flexiblere Vorgehen
Gibt es einen Unterschied zwischen Fixes und Features? Nein. Beides sind Improvements des aktuellen States/Zustands. Wenn einem in einem Feature-Branch ein allgemeines Problem auffällt, fixt man das Problem und merged den Master mit der neuen Version erneut in den Feature-Branch.
Zwischenzeitlicher Fix:
Es ist an sich kein Unterschied zwischen einem Fix und einen weiteren Feature-Branch, außer dass der Fix-Branch sehr viel kurzlebiger ist und wohl weniger Commits enthält.
Der Master ist immer stable, weil nur Release-Tags darauf abgebildet sind.
Dieses Herangehen macht es sehr einfach jeden State/Zustand auf System abzubilden. Jeder Branch ist unter seinem Namen zu finden und Tags werden nach Typ auf Systeme gemappt.
Tag auf System: - release-XXX auf das produktive System
- staging auf das Staging-System (1:1 Namenabbildung)
- demo1-n auch 1:1 per Namen abbilden
Bei staging muss man den Tag löschen und neu anlegen, so kann jeder Zustand auf dem Staging-System deployt werden oder besser gesagt, wird ein Deployment durchgeführt das dann unter der Staging-Domain erreichbar ist. Hier gibt es eine tolle Anleitung wie man solche Systeme mit Traefik oder Kubernetes ganz einfach bauen kann. Ich werde das aber vielleicht auch noch mal genauer beschreiben, wie ich es für gut halte.
Denn Branches halte ich persönlich es nicht für wert wo anders als lokal in einem Docker-Container zu laufen. Da kann ich um es der Fachabteilung lieber schnell einen Tag erstellen und diesen nach dem Input der Abteilung auch wieder unter selben Namen neu anlegen oder unter einen neuen wenn zwei mögliche Umsetzungen verglichen werden sollen (macht das mal mit Git-Flow!).
Edit: Ich habe die per Hand gezeichneten Diagramme durch vollständigere Diagramme, die per Software erstellt wurden, ausgetauscht.
Gehen wir mal davon aus wir erstellen eine Homepage für eine Restaurant-Kette mit 3 Restaurants. Die Seite soll so gebaut sein, dass Mitarbeiter der Restaurants einfache Datenänderungen vornehmen können, ohne dafür um Hilfe fragen zu müssen. Auch sollen Änderungen im Layout einfach und schnell möglich sein, dass aber nicht durch die Mitarbeiter, da diese wohl kein HTML beherrschen.
Jedes Restaurant hat eine eigene Unterseite, die vom Aufbau aber immer gleich sind.
Das Problem ist, dass wenn es Änderungen im Layout dieser 3 Seiten geben soll, müssen die Änderungen auch in allen 3 Seiten getätigt werden. Ein einfaches Kopieren geht natürlich nicht, da man sonst ja die individuellen Texte und Bilder überschreiben würde. Die speziellen Öffnungszeiten für Feiertage einzutragen ist nicht ganz so kompliziert, wenn man einen WYSIWYG-Editor hat. Aber einfacher wäre es natürlich, wenn diese Angaben atomar eingegeben werden können und so auch nicht die Gefahr besteht, durch Fehler die gesamte Seite durcheinander zu bringen.
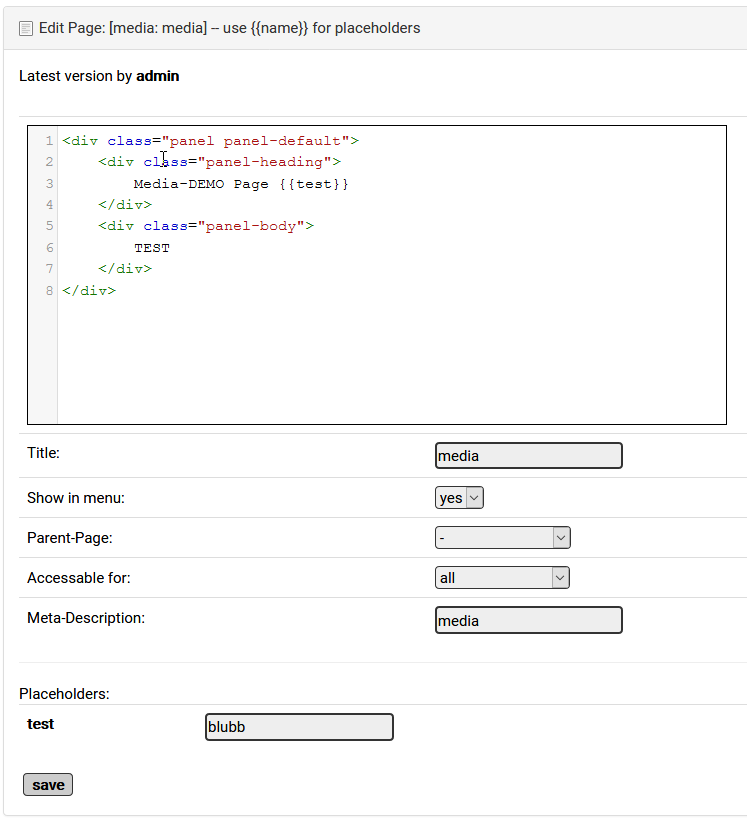
Ich habe für mein Framework/CMS diese Lösung entwickelt. In dem Code der Seite sind Platzhalter eingebaut, die heraus geparst werden und mit individuellen Werten gefüllt werden können. Daher kann man einfach eine vorhandene Seite kopieren und muss nur die im Formular ausgewiesenen Platzhalter neu füllen. Das Layout zu Ändern geht auch einfach weil man den Code wirklich mit Copy und Paste in alle Seiten übernehmen kann, ohne Werte zu überschreiben.
Man hätte natürlich auch Entitäten und Controller mit Templates bauen können. Aber für solche Zwecke ist das oft vom Aufwand her nicht gerechtfertigt, weil die verwendete Zeit nicht entsprechend bezahlt werden würde und mit dieser Lösung es wohl auch schneller geht.
Und für die einfachen Benutzer ist es so auch viel übersichtlicher und sie können dann bestimmt mehr alleine Ändern, weil sie nicht der Content der gesamten Seite erschlägt.
Oft hat man das Problem, dass man verschiedene Einheiten verarbeiten muss und nicht alle sich an Standardeinheiten (SI) halten. Mag es daran liegen, dass die Person historisch gewachsene Einheiten wie Liter oder Pfund verwendet oder auch einfach daran, dass diese Person Amerikaner ist. Natürlich gibt es genug Frameworks, die einen helfen mit allen möglichen Einheiten klar zu kommen, aber es ist an sich gar nicht schwer sich so etwas selber zu schreiben.
Man muss nur die Basis-Einheit (SI) bestimmen und alle anderen Einheiten sich darauf beziehen lassen. Ein gutes Beispiel ist hier Inch/Zoll um das ganze zu demonstrieren.
Wir befinden uns in der Gruppe der Einheiten zur Bestimmung von Längen. Die Basiseinheit ist laut SI der Meter. Wir bauen uns jetzt 3 Einheiten Entitäten (die man am Besten in einer Datenbank anlegen sollte).
Wie kommen wir jetzt ganz einfach von Inch auf Zentimeter? Wir nehmen den Inch-Wert und multiplizieren ihn mit dem Conversionfactor. Dann haben wir bei 1 Inch einen Wert von 0,0254 Meter. Nun nehmen wir uns unseren Zentimeter und teilen den Meter-Wert durch den Conversionfactor des Zentimeter. 0,0254 / 0.01 = 2.54 damit haben wir Inch in Centimeter umgerechnet. Einfacher Dreisatz. Wenn wir nun Einheitenwerte zu irgendwas speichern wollen, ist es eine gute Idee, diese vor dem Speichern immer auf die Basis-Einheit umzurechnen.
Das vereinfacht die Ausgabe, weil eine Methode sich so direkt die Einheit bilden kann, die sie gerne hätte.
In dem Zusammenhang ist auch eine Methode gut, die eine ideale Maßeinheit für einen Wert bestimmt. Wenn wir nun 0,001cm haben sollte diese Methode uns sagen können, dass die Repräsentation 1m für den Benutzer sehr viel einfacher zu lesen ist und uns den Wert und die Einheit liefern können.
Auch praktisch ist, dass man so dem Benutzer es überlassen kann in welcher Einheit er Ausgaben gerne sehen würde. Würden wir uns im Bereich der Flächeneinheiten befinden und die Fernsehsendung Galileo über die Größe der Flächen von bestimmten Dingen berichten wollen, können wir für sie direkt die Einheit "Fußballfeld" definieren und sie ihnen als Ausgabemöglichkeit anbieten.
Weitere Gedanken zu Einheiten/Units
Bei Bestellsystemen bereitet oft die Pseudo-Einheit "Stück" Probleme. Aber hier muss man sich einfach von der Vorstellung von Stück als eigene Einheit trennen. Maßeinheiten werden gemessen.. Stück werden einfach gezählt. Am Ende wird alles auf eine Verpackungseinheit herunter gebrochen und diese ist alleinstehend "1 Stück". Wenn ich 5L Wasser bestellen möchte ist es weiterhin sehr wichtig wie dieses Verpackt ist. 5x 1L oder 10x 0,5L. Verpackungseinheiten können auch rein virtuell sein. 100L = 100x 1L wobei nicht gesagt ist, dass dieses "verpackt" sein muss und nicht einfach direkt von einem Tank in einen anderen umgefüllt werden kann. Also.. Stück ist keine Maßeinheit sondern existiert parallel dazu um beschreibt nur eine Portionierung der in der Maßeinheit gemessenen Sache, die so geliefert werden kann.
Wo ist der Unterschied zwischen einer 1L Flasche Wasser und einem Stuhl? Beides ist "1 Stück" wobei man bei der Flasche den Inhalt in eine Maßeinheit fassen kann und bei einem Stuhl nicht. Ok.. man könnte.. es ergibt aber einfach keinen Sinn sich 25kg Stuhl zu bestellen.
Für Produktionssysteme ist der obige Ansatz sogar ohne solche Überlegungen einfach direkt umsetzbar und funktioniert sehr gut.
Nested-Sets sind für normale Baumstrukturen super, aber wenn man etwas flexibler sein möchte und z.B. ein Item in mehreren Kategorien haben möchte oder eine Kategorie auch als Kind-Element von z.B. einer Angebots-Kampanie, ist man schon nicht mehr bei einem Baum sondern bei einem Netz. Nun hier Eltern-Elemente zu finden und zu wissen in welchen Kategorien ein Item sich befindet ist etwas aufwendiger.
CREATE TABLE exp_structure(
ID int(11) UNSIGNED NOT NULL AUTO_INCREMENT,
NAME VARCHAR(255) NOT NULL,
TYPE VARCHAR(255) NOT NULL,
PRIMARY KEY(ID)
);
Damit man nun schnell herausfinden kann wird, beim Anlegen eines Items in der Struktur wird nicht nur ein Link auf das direkte Parent-Element gesetzt sondern werden auch rekursiv alle weiteren Parent-Element aufgerufen und ein Shadow-Link darauf gesetzt. Dieser Shadow-Link besagt, dass das Item nicht direkt am Parent-Element hängt sondern Subelement zugeordnet ist. In der Oberfläche sind mit Shadow-Links verlinkte Items also nicht anzuzeigen.
Ist ja erst einmal ganz einfach. Wenn ich nun aber z.B. ein Item mit 2 Parent-Elementen habe, muss man wenn man weiter nach oben in die Hierarchie kommt darauf achten, dass man nicht mehrere Shadow-Links setzt. Das ist an sich auch kein großes Problem. Schwierig wird wenn man ein Item entfernt und die Shadow-Links entfernen muss. Bei jedem Shadow-Link müsste man prüfen, ob er durch einen weiteren Pfad noch verwendet wird oder nicht. Dafür gibt die REFCOUNT... ja genau.. wie im Garbage Collector. Wenn man ein Shadow-Link setzten soll, dieser aber schon existiert zählt man Counter hoch. Beim Entfernen zählt man einfach alle Shadow-Links des Pfades runter und entfernt dann alle die auf 0 stehen, weil man dann sicher ist, dass dieser Shadow-Link nicht noch von einem anderen Pfad verwendet wird.
Meine erste Reallife-Erfahrung mit dem ZF2 und Models war eine eher weniger positive. Das TableGateway braucht unbedingt den Service-Manager bzw den DB-Adapter daraus. Meine Vorgängerin hat sich dazu entschlossen eine Basis-Entität zu bauen, die wiederum von TableGateway ableitet und man so relativ einfach save() und
load()-Methoden in die Model-Klasse einbauen konnte. Der Service-Manager wurde dann durch den Constructor der Model-Klasse durch gereicht bis man den Constructor des TableGateways mit dem DB-Adapter aufrufen konnte. Auch zwischen durch wurde der Service-Manager immer mal benötigt. Weil.. man ohne ihn keine Instanz einer Model-Klasse bekommen konnte.
Um so eine Instanz zu bekommen wurde eine Factory verwendet:
/**
* By default, the ServiceManager assumes all services are shared (= single instantiation),
* but you may specify a boolean false value here to indicate a new instance should be returned.
*/
'shared' => array(
'sModel' => false
)
)
Jedes mal aber die Factory zu bemühen eine neue Instanz zu erzeugen ist nicht gerade performant und mit den ganzen Ableitungen ist es auch sehr unübersichtlich. Ich wollte einfach schnell eine Instanz einer Model-Klasse haben und nicht ein riesiges Object bekommen. Also sowas wie in POPO .. eine POJO in PHP eben.
Ein Cosntructor ohne Argumente und eine Klasse nur mit Attributen ohne Logik. Also find ich an mir zu überlegen, ob diese ganzen Ableitungen überhaupt nötig sind oder man mit der Dependency-Injection nicht was viel besseres bauen könnte.
Ich bin dann schnell zu DAOs gwechselt. Die Factory injeziert einmal den Service-Manager und kann immer die selbe Instanz des DAOs liefern. Die DTO/Model-Klasse ist schön klein und beim Befüllen in Schleifen viel schneller als eine Intanz über die Factory anfordern zu müssen.
 bezahlt von
bezahlt von  Blog: Blog-entries by search-pattern/Tags:
Blog: Blog-entries by search-pattern/Tags: