Plugins für Shopware 6 zu schreiben ist an sich garnicht so unterschiedlich zu dem selben Vorgang für Shopware 5. Was nur anders geworden ist, dass Shopware eigene XMLs und Enlight-Components durch den Composer und Symfony abgelöst wurden. Man kann nun wirklich Namespaces definieren, die unabhängig vom Plugin-Namen sind und es ist kein Problem mehr den Composer mit Plugins zu verwenden, sondern es ist jetzt der zu gehende Weg.
Setup
Wie gehabt kann man sein Plugin unter custom/plugins anlegen.
custom/plugins/HPrOrderExample
Zu erst sollte man mit der composer.json anfangen.
Wichtig in der composer.json ist einmal der PSR-4 Namespace den man auf das src/ Verzeichnis setzt und der "extra" Teil. Dort wird alles definiert, was mit Shopware zu tun hat. Hier wird auch die zentrale Plugin-Class angegeben, die nicht mehr wie in Shopware 5 den selben Namen des Verzeichnisses des Plugins haben muss. Auch sieht man hier dass der Namespace-Name nichts mehr mit dem Verzeichniss-Namen zu tun hat.
Wir könnten durch die composer.json das Plugin auch komplett außerhalb der Shopware-Installation entwickeln, weil die gesamte Plattform als Dependency eingebunden ist. Deswegen müssen wir auch einmal den Composer ausführen.
php composer install
Plugin programmieren Nun fangen wir mit dem Schreiben des Plugins an.
Die Plugin-Klasse enthält erst einmal keine weitere Logik:
<?php
namespace HPr\OrderExample;
use Shopware\Core\Framework\Plugin;
class OrderExample extends Plugin{
}
Wir wollen auf ein Event reagieren. Dafür benutzen wir eine Subscriber-Klasse. Während man diese in Shopware 5 nicht unbedingt brauchte und alles in der Plugin-Klasse erldedigen konnte, muss man nun eine extra Klasse nutzen und diese auch in der services.xml eintragen. Die Id des Services ist der fullqualified-classname des Subscribers
Resources ist vordefiniert, kann aber in der Plugin-Klasse angepasst werden, so dass diese Dateien auch in einem anderen Package liegen könnten.
src/Subscribers/OnOrderSaved
<?php
namespace HPr\OrderExample\Subscribers;
use Shopware\Core\Checkout\Order\OrderEvents;
use Shopware\Core\Framework\DataAbstractionLayer\Event\EntityWrittenEvent;
use Symfony\Component\EventDispatcher\EventSubscriberInterface;
class OnOrderSaved implements EventSubscriberInterface {
/**
* @return array The event names to listen to
*/
public static function getSubscribedEvents()
{
return [
OrderEvents::ORDER_WRITTEN_EVENT => ['dumpOrderData']
];
}
public function dumpOrderData(EntityWrittenEvent $event) {
file_put_contents('/var/test/orderdump.json', json_encode($event->getContext()));
}
}
Hier sieht man, dass nur noch Symfony benutzt wird und keine Shopware eigenen Events.
Wir schreiben einfach die Order-Entity, die gespeichert wurde in eine Datei. Dort können wir UUID und ähnliches der Order finden.
Das ganze kann man dann weiter ausbauen und auf andere Order-Events (die man alle in der OrderEvents.php finden kann) reagieren.
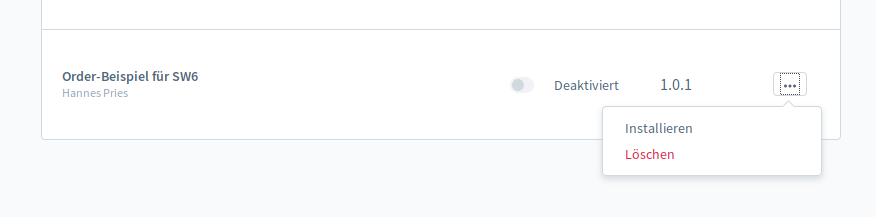
Installieren
Damit ist das Plugin auch schon soweit fertig. Den Composer haben wir schon ausgeführt (ansonsten müssen wir es spätestens jetzt machen).
Nun geht es über die UI oder die Console weiter. Dort wird das Plugin installiert und und aktiviert.
Wenn man nun eine Bestellung ausführt wird, deren Entity in die oben angegebene Datei geschrieben.
Wenn man sich für Shopware ein Plugin kauft, kann es sein, dass man die Daten genau so vorfindet, wie man sie braucht, aber möchte das dort verwendete Template ersetzen oder die Daten in einem Template verwenden, das im Plugin noch gar nicht vorgesehen war.
Dafür kann man sich ein eigenes kleines Plugin schreiben. Das geht in 5 Minuten. Wir schreiben uns das Plugin TESTNotLoggedIn und blenden damit den Newsletter in der Footer Navigation aus.
Ins Verzeichnis TESTNotLoggedIn kommt die Datei TESTNotLoggedIn.php:
namespace TESTNotLoggedIn;
use Shopware\Components\Plugin;
class TESTNotLoggedIn extends Plugin{
public static function getSubscribedEvents()
{
return [
'Enlight_Controller_Action_PostDispatchSecure_Frontend' => 'addTemplateDir',
'Enlight_Controller_Action_PostDispatchSecure_Widgets' => 'addTemplateDir',
];
}
public function addTemplateDir(\Enlight_Controller_ActionEventArgs $args)
{
try {
$args->getSubject()->View()->addTemplateDir($this->getPath() . '/Resources/views/');
}
catch(\Exception $e){
//TODO
}
}
}
jetzt kommt das Verzeichnis Resources/views/ dazu und die Datei plugin.xml:
<?xml version="1.0" encoding="utf-8"?>
<plugin xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="https://raw.githubusercontent.com/shopware/shopware/5.2/engine/Shopware/Components/Plugin/schema/plugin.xsd">
<label lang="de">TEST Not Logged In</label>
<label lang="en">TEST Not Logged In</label>
Hier wird das Plugin, das wir erweitern wollen, angegeben. Ich verwendet das kostenlose "Globale Kunden Smarty-Variablen". Nun können wir einfach unsere Templates im views-Verzeichnis anlegen und vorhandene erweitern.
Als Beispiel kommt hier Resources/views/frontend/index/footer-navigation.tpl
Damit ist das Plugin schon fertig und kann installiert werden. Der Newsletter Bereich im Footer ist nun nur sichtbar, wenn man eingelogged ist.
Das Plugin "Eigenschaften in Artikel-Listing" bietet z.B. auch an in der Detailseite die Daten nur als Smarty-Variable bereit zu stellen, damit man selbst direkt die Darstellung implementieren kann und nicht noch eine vorhandene unpassende anpassen oder entfernen und ersetzen muss.
Events behandeln wir hier bei wie einen normalen Kunden. Ich werde die Übersetzung noch mal neu machen und dann wird es alles auch auf Deutsch geben und dann werde ich Events direkt mit einbringen.
Zuerst legen wir uns eine Gruppe für unsere Events an. Gruppen haben die Aufgabe ähnliche Kunden und Events zusammen und auch die Zuordnung zu den Benutzern abzubilden. Gruppen sind dafür da wenn man für verschiedene Firmen Kunden als Freelancer bedient oder für Teams und Abteilungen in einer Firma, die alle einzeln ihre Kunden und Zeiten abrechnen.
Wir legen also hier eine Gruppe „Events“ an, damit wir unseren Mitarbeitern und Aushilfen bei den Events die Möglichkeit geben Zeiten auf die Events buchen zu können.
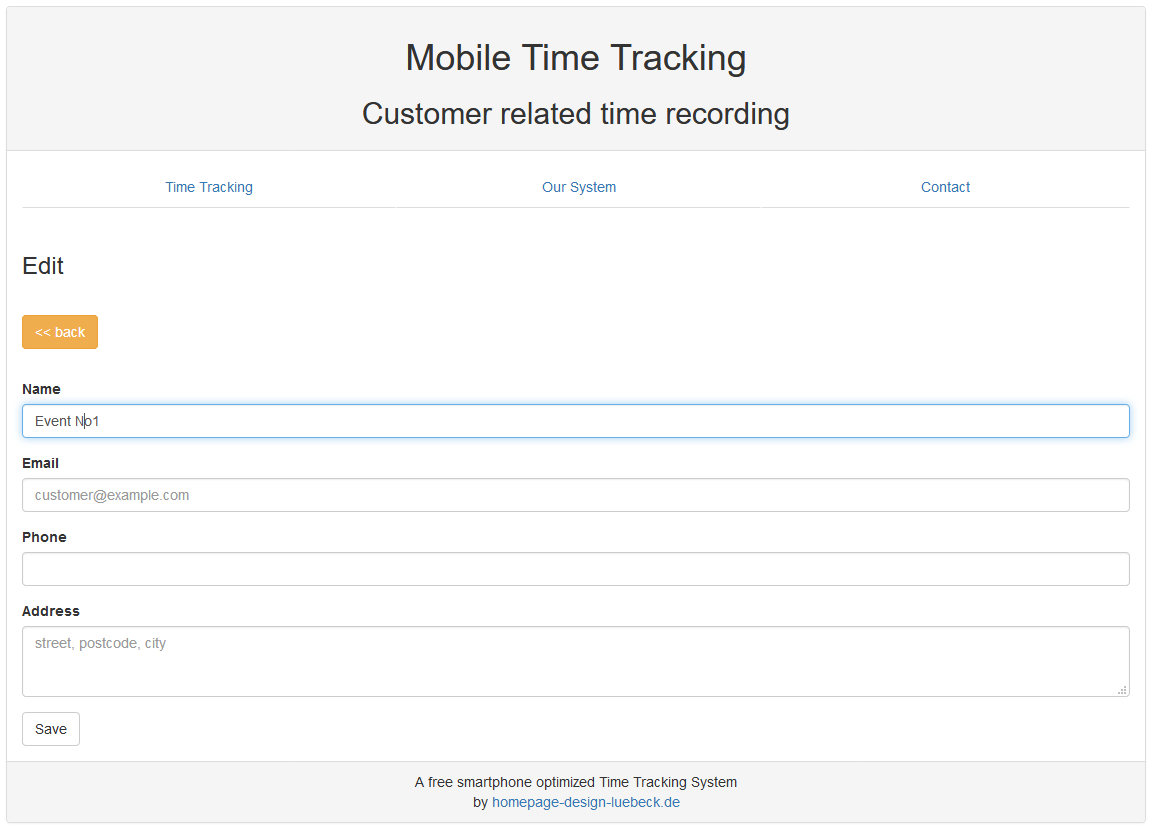
Danach kommt jetzt unser Event No1. Das legen wir direkt an. Wir brauchen dafür nur einen Namen. Kontaktinformationen werden nicht benötigt, helfen aber den Mitarbeiten um zum Kunden oder zur Event-Location zu finden oder sich dort zu melden, falls etwas etwas zu klären ist. Die OpenStreetMap-Integration ist jetzt nicht wirklich toll, aber doch eine Hilfe, um den Weg zu finden, falls man sich dort nicht auskennen sollte. Aber es ersetzt keine "echte" Navi-App.
Ich überlege gerade ob Appointments praktisch wären.. also man Termine für einen Mitarbeiter eintragen kann, so damit der Mitarbeiter weiß, wann er wo sein soll. Also etwas wie „Event No1, Appointment 17:00“. Dann weiß der Mitarbeiter, dass er um 17:00 an der Event-Location von Event No 1 sein soll.
Falls jemand das System benutzt und so etwas gerne hätte.. einfach bei mir melden und ich bauen es ein :-)
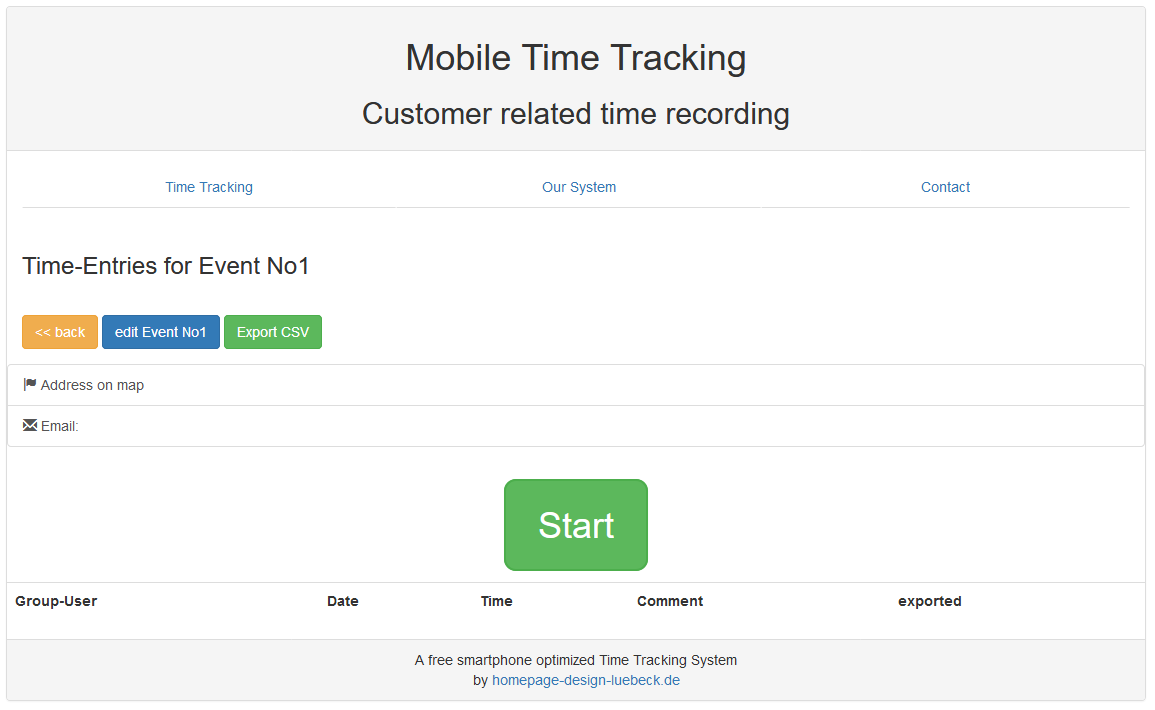
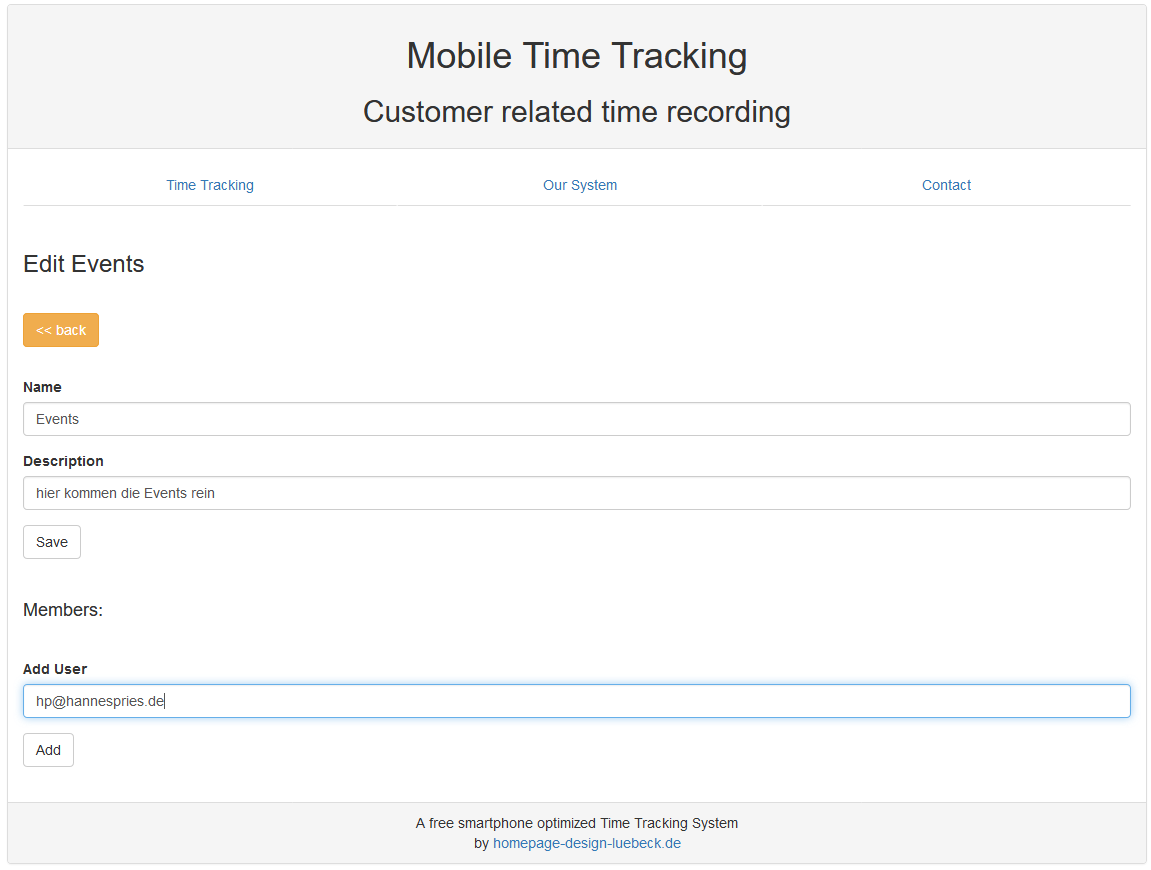
Nachdem wir unser Event No1 anlegt haben, können wir Zeiten darauf buchen. Aber wir wollen ja, dass unsere Mitarbeiter ihre Zeiten darauf buchen.
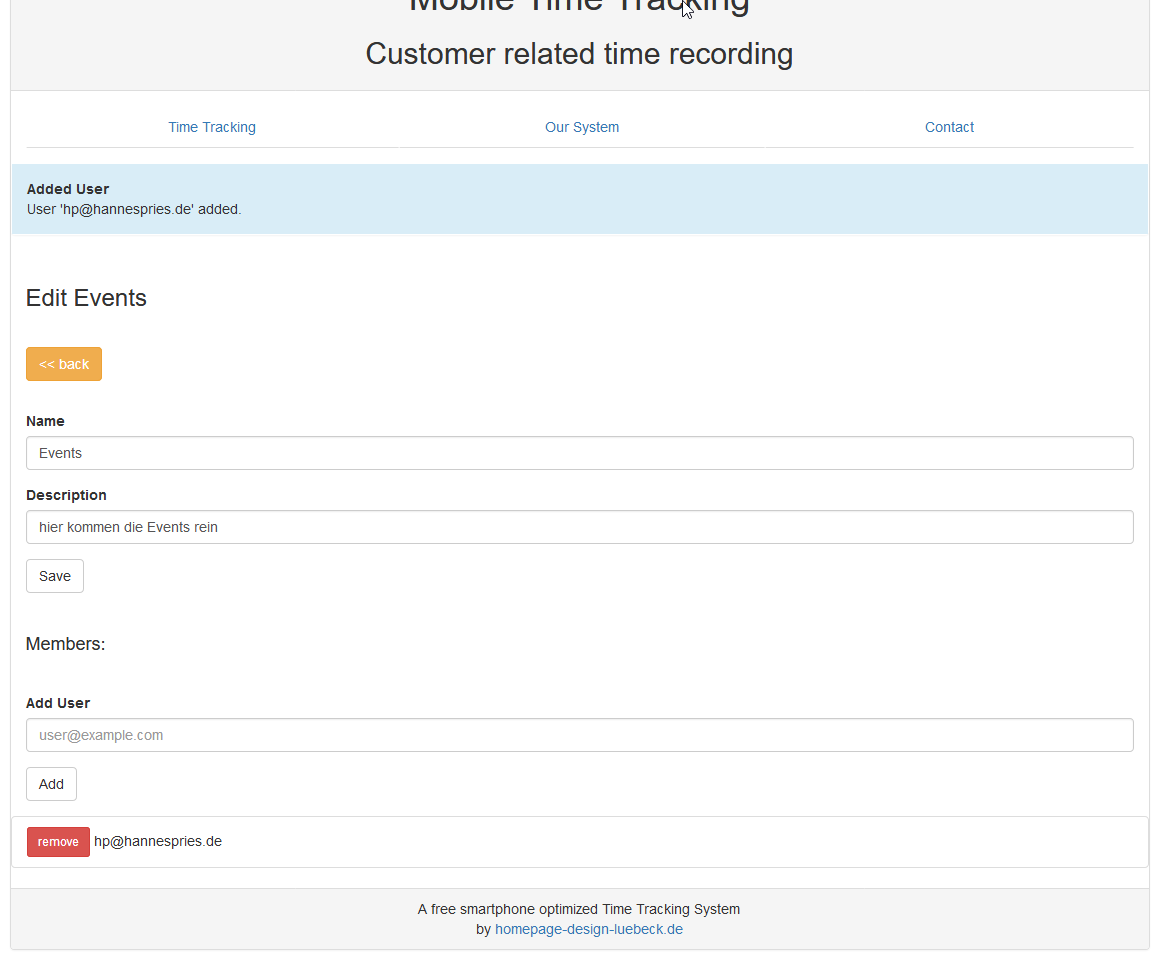
Also gehen wir "edit“ bei der Gruppe und tragen weiter unten den Benutzernamen/ die Emailadresse unseres Mitarbeiter ein. Er muss dafür bei mobile-time-tracking.com registriert sein.
Danach sieht er die Gruppe auch auf seiner Startseite und kann seine Zeiten auf die Events in der Gruppe buchen.
Wenn er also bei der Event-Location ankommt, wählt er das Event aus und drückt auf "Start“. Nachdem er dort fertig ist drückt er auf "Stop“ und geht glücklich und erschöpft nach Hause.
Der Besitzer der Gruppe darf alle Zeiten sehen. Normale Mitarbeiter (also !Besitzer) sehen nur ihre eigenen Buchungen.
Bevor es dann wirklich mal um die Installation von PDT in Eclipse geht, wollen wir uns erst einmal eine MySQL Datenbank einrichten, damit wir auch richtige kleine Anwendungen schreiben können und nur ganz selten kommt man da ohne Datenbank aus. Auch wenn NoSQL Datenbanken wie Neo4J wirklich toll und momentan sehr in sind, bleiben wir bei einem klassischen RDBMS. Weil MySQL gerade im Web sehr verbreitet ist und sich einfach lokal einrichten lässt, bleiben wir auch bei MySQL.
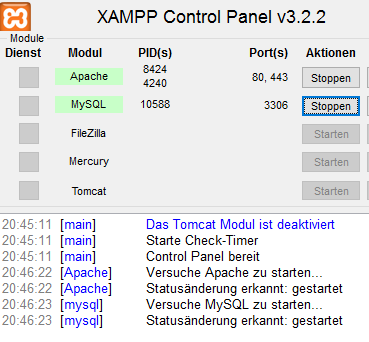
Wer ein Linux benutzt, kann MySQL immer ganz einfach über den Paket-Mananger installieren. Für Windows kann man schnell zu XAMPP greifen. XAMPP enthält alles vom Apache, PHP7 und MySQL bzw MariaDB.
XAMPP funktioniert am Besten wenn man es direkt unter C:\ installiert.
Zum Verwalten der Server-Anwendungen von XAMPP gibt es das XAMPP Control Panel. Hier müssen nur der Apache und der MySQL Server gestartet
werden.
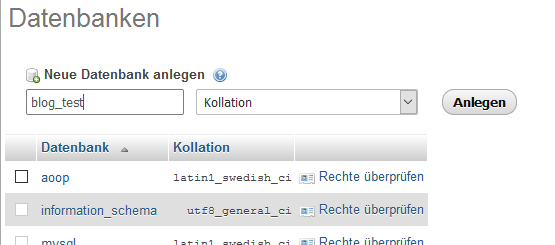
Damit auf die Datenbank zugegriffen werden kann bringt XAMPP phpMyAdmin mit. phpMyAdmin ist eine Datenbankverwaltung die in PHP geschrieben ist und auch von den meisten Hostern angeboten wird.. wenn nicht sogar von allen. Man kann direkt über die URL http://localhost/phpmyadmin darauf zugreifen.
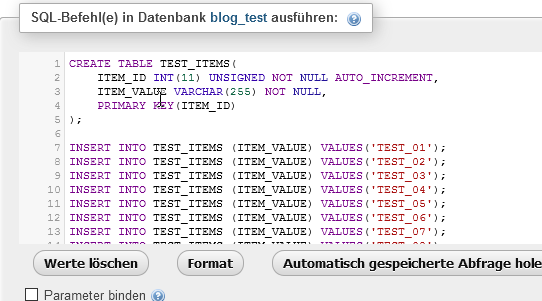
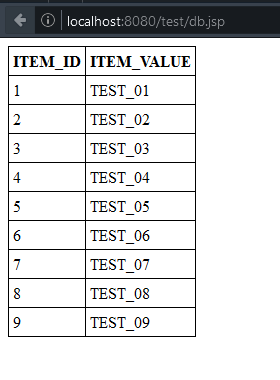
Zuerst erstellen wir eine Datenbank mit dem Namen blog_test.
Damit wir ein paar Daten haben, legen wir uns eine Tabelle mit ein paar wenigen Daten an. Hier ist das SQL-Script dafür:
CREATE TABLE TEST_ITEMS(
ITEM_ID INT(11) UNSIGNED NOT NULL AUTO_INCREMENT,
ITEM_VALUE VARCHAR(255) NOT NULL,
PRIMARY KEY(ITEM_ID)
);
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_01');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_02');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_03');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_04');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_05');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_06');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_07');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_08');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_09');
Die IDs werden automatisch hochgezählt und müssen deswegen nicht extra angegeben werden.
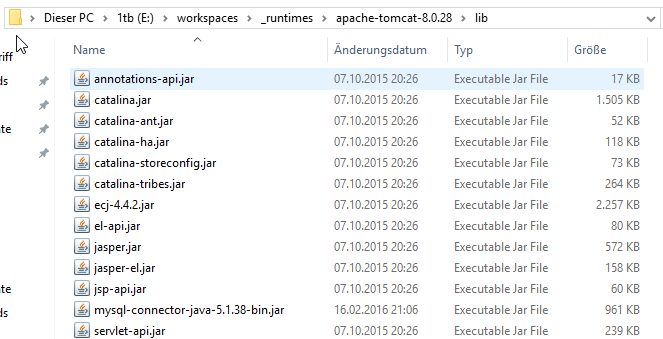
Nun gehen wir wieder in Eclipse zurück und erstellen uns eine kleine JSP mit einer Datenbankabfrage. Und hier wird es etwas komplizierter mit den verschiedenen ClassLoader des Tomcats und den verschiedenen Config-Dateien. Ich hab die einfachste aber nicht beste Variante gewählt. Die JAR-Datei mit dem JDBC-Treiber kommt direkt in das lib-Verzeichnis des Tomcat und wir passen die zentrale context.xml Datei, die uns von Eclipse zur Verfügung gestellt wird.
Die aktuelle JAR mit dem MySQL-Treiber findet man auf dev.mysql.com.
In die Context-Datei definierten wir die DataSource als Resource.
Nun können wir über JNDI uns diese DataSource in eine JSP holen. Wir erstellen eine ganz einfach Abfrage. Das Ergebnis liefert uns ein Statement in Form eines ResultSets. Ich benutzt hier die Methode über den Index die Ergebnisse zu bekommen, z.B. getString(1) wobei aber auch getString("ITEM_ID") funktioniert und für den zielgerichteten Einsatz sehr viel besser ist, weil man so das SQL-Statement ändern kann und auch die Reihenfolge der Columns ändern, ohne dabei auf den Java-Code achten zu müssen. Hier wird aber nicht zielgerichtet ein Wert ausgelesen und z.B. in ein anderes Object geschrieben sondern einfach alles ausgegeben. Deswegen auch nur getString() und keine anderen Methoden, die einen passenden Datentyp zurück liefern und ein eigenes Casten der Werte unnötig machen.
Der Vorteil die Connection über eine DataSource zu bekommen und nicht jedes mal selbst zu initiieren ist, dass die DataSource ein Pooling der Connections vornimmt und Datenbankverbindungen zur Wiederverwendung offen hält, um den Overhead für Verbindungsaufbauten zu verringern.
SQL-Abfragen direkt in einer JSP-Seite zu ist aber eine schlechte und man sollte so etwas in DAO-Klassen auslagern und in der JSP nur die Ansicht mit schon fertigen Objekten erstellen, die dann vom DAO geliefert werden.
Außerdem werden immer mehr JPA verwendet, wo die SQL-Statements automatisch erzeugt werden. Handgeschriebenes SQL ist in komplexen Fällen meistens schneller und besser, aber ORM-Frameworks erleichtern einen die Arbeit schon sehr und man sollte sich JPA auf jeden Fall einmal
ansehen, bevor man noch direkt mit JDBC und SQL arbeitet.
Im nächsten Teil geht es dann wirklich mit PHP weiter.
Oft werden NoSQL für sehr spezielle Fälle eingesetzt. Die normale Datenhaltung bleibt weiter hin den SQL-Datenbanken überlassen. Also müssen regelmäßig die Daten aus dem SQL-Bestand in die NoSQL Datenbank kopiert werden. Das dauert oft und viele aufbereitungen der Daten wird schon hier erledigt. die NoSQL Varianten sind deswegen auch oft schneller, weil man eine Teil der Arbeit in den Import-Jobs erledigt, die sonst bei jedem Query als Overhead entstehen. Natürlich haben die NoSQL auch ohne das ihre Vorteile, aber man sollte immer im Auge behalten, ob die Performance von der Engine kommt oder auch von der Optimierung der Daten, weil die Optimierungen der Daten könnte man auch in die SQL-Struktur zurück fließen lassen und diese in die Richtung hin verbessern.
So ein Import dauert... wenn man in der Nacht ein Zeitfenster von einer Stunde hat, ist alles kein Problem. Will man aber auch in kurzen Abständen importieren, muss der Import schnell laufen. Auch wenn man als Entwickler öfters mal den Import braucht, ist es wichtig möglichst viel Performance zu haben.
Hier geht es darum wie man möglichst schnell und einfach Daten aus einer MySQL Datenbank in eine Neo4j Graphen-Datenbank importieren kann, ohne viel Overhead zu erzeugen. Ich verwende hier PHP, aber da an sich keine Logik in PHP implementiert werden wird, kann man ganz leicht auf jeden andere Sprache, wie Java, JavaScript mit node.js und so übertragen. Es werden keine ORMs verwendet (die extrem viel Overhead erzeugen und viel Performance kosten) sondern nur SQL und Cypher.
Wie man einfach sich eine oder mehrere Neo4J-Instanzen anlegt (unter Linux) kann man hier sehr gut sehen:
Wir verwenden bei Neo4j den Import über eine CSV-Datei. Wir werden also nicht jeden Datensatz einzeln Lesen und Schreiben, sondern immer sehr viele auf einmal. Ob man alles in einer Transaktion laufen lässt und erst am Ende commited hängt etwas von der Datenmenge ab. Bis 200.000 Nodes und Relations ist alles kein Problem.. bei Millionen von Datensätzen sollte man aber nochmal drüber nachdenken.
PERIODIC COMMIT ist da eine super Lösung, um alles automatisch laufen zu lassen und sich nicht selbst darum kümmern zu müssen, wann commited wird. Alle 1000 bis 10_000 Datensätze ein Commit sollte gut sein, wobei ich eher zu 10_000 raten würde, weil 1000 doch noch sehr viele Commits sind und so mit der Overhead noch relativ groß ist.
Unsere Beispiel Datenbank sieht so aus:
CREATE TABLE USERS(
USER_ID INT(11) UNSGINED NOT NULL,
USER_NAME VARCHAR(255) NOT NULL,
PRIMARY KEY (USER_ID)
);
CREATE TABLE MESSAGES(
MESSAGE_ID INT(11) UNSIGNED NOT NULL AUTO_INCREMENT,
MESSAGE_TITLE VARCHAR(255) NOT NULL,
FROM_ID INT(11) UNSIGNED NOT NULL,
TO_ID INT(11) UNSIGNED NOT NULL,
CC_ID INT(11) UNSIGNED NOT NULL,
PRIMARY KEY (MESSAGE_ID)
);
Wir legen uns 50.000 User an dann noch 100.000 Messages mit jeweils einen FROM, einem TO und einem CC (hier hätte man über eine Link-Table sollen, aber das hier ist nur ein kleines Beispiel, wo das so reicht). Das sollten erst einmal genug Daten sein. (Offtopic: da ich das gerade neben bei auch in PHP schreibe.. warum kann ich für eine 100000 nicht wie in Java 100_000 schreiben?)
Die erste Schwierigkeit ist es die Daten schnell zu exportieren. Ziel ist eine CSV. Wir könnten entweder über PHP die Daten lesen und in eine Datei schreiben oder aber einfach die OUTFILE-Funktion von MySQL nutzen, um die Datenbank diese Arbeit erledigen zu lassen. Wir werden es so machen und erstellen für jede Art von Nodes und Relations eine eigene CSV. Weil wir Header haben wollen fügen wir diese mit UNION einmal oben hinzu
$sql="
SELECT 'user_id', 'user_name'
UNION
SELECT USER_ID,USERNAME
FROM USERS
INTO OUTFILE ".$exchangeFolder."/users.csv
FIELDS TERMINATED BY ','
ENCLOSED BY ''
LINES TERMINATED BY '\n'
";
Damit schreibt MySQL das Ergebnis des Queries in die angegebene Datei. Falls ein Fehler auftritt, muss man gucken, ob der Benutzer unter dem die MySQL-DB läuft in das Verzeichnis schreiben darf und ob nicht eine Anwendung wie apparmor unter Linux nicht den Zugriff blockiert. Es darf keine Datei mit diesen Namen schon vorhanden sein, sonst liefert MySQL auch nur einen Fehler zurück. Wir müssen
die Dateien also vorher löschen und dass machen wir einfach über PHP. Also muss auch der Benutzer unter dem die PHP-Anwendung läuft entsprechende Rechte haben.
Man kann das gut einmal direkt mit phpmyadmin oder einem entsprechenden Programm wie der MySQL Workbench testen. Wenn die Datei erzeugt und befüllt wird ist alles richtig eingestellt.
Mit dem Erstellen der CSV-Datei ist schon mal die Hälfte geschafft. Damit der Import auch schnell geht brauchen wir einen Index für unsere Nodes. Man kann einen Index schon anlegen, wenn noch gar kein Node des Types erstellt wurde. Zum Importieren der User benutzen wir folgendes Cypher-Statement:
$cyp="USING PERIODIC COMMIT 10000
LOAD CSV WITH HEADERS FROM "file:///".$exchangeFolder."/messages.csv" AS row
MERGE (m:message{mid:row.msg_id,title:row.msg_title});";
Der Pfad zur Datei wird als File-URL angegeben. Hier merkt man auch Neo4J seine Java-Basis an. Wenn man mal in eine Temp-Verzeichnis schaut sieht man dort auch Spuren von Jetty.
Am Ende wird der Importer nur eine Reihe von SQL und Cypher Statements ausführen. Wir benötigen um komfortabel zu arbeiten 3 Hilfsmethoden. Dass alles in richtige Klassen zu verpacken wäre natürlich besser, aber es reicht zum erklären erst einmal ein Funktionsbasierter Ansatz.
Da MySQL keine Dateien überschreiben will, brauchen wir eine Funktion zum Aufräumen des Verzeichnisses über das die CSV-Dateien ausgetauscht werden. Wir räumen einmal davor und einmal danach auf. Dann ist es kein Problem den Importer beim Testen mal mittendrin zu stoppen oder wenn er mal doch mit einem Fehler abbricht.
function cleanFolder($folder){
$files=scandir($folder);
foreach($files as $file){
if(preg_match("/\.csv$/i", $file)){
unlink($folder."/".$file);
}
}
}
Für Neo4J bauen wir uns eine eigen kleine Funktion.
use Everyman\Neo4j\Client;
use Everyman\Neo4j\Cypher\Query;
$client = new Everyman\Neo4j\Client();
$client->getTransport()->setAuth("neo4j","blubb");
function executeCypher($query){
global $client;
$query=new Query($client, $query);
$query->getResultSet();
}
Der Rest ist nun sehr einfach und linear. Ich glaube ich muss da nicht viel erklären und jeder Erkennt sehr schnell wie alles abläuft. Interessant ist wohl das Cypher-Statement für die Receive-Relations, da neben der Relation diese auch mit einem Attribute versehen wird im SET Bereich.
//clear for export (if a previous import failed)
cleanFolder($exchangeFolder);
//export nodes
echo "create users.csv\n";
$sql=" SELECT 'user_id', 'user_name' UNION
SELECT USER_ID,USER_NAME
FROM USERS
INTO OUTFILE '".$exchangeFolder."/users.csv'
FIELDS TERMINATED BY ','
ENCLOSED BY ''
LINES TERMINATED BY '\n'";
$db->execute($sql);
echo "create messages.csv\n";
$sql=" SELECT 'msg_id', 'msg_title' UNION
SELECT MESSAGE_ID, MESSAGE_TITLE
FROM MESSAGES
INTO OUTFILE '".$exchangeFolder."/messages.csv'
FIELDS TERMINATED BY ','
ENCLOSED BY ''
LINES TERMINATED BY '\n'";
$db->execute($sql);
//export relations
echo "create relations_etc.csv\n";
$sql=" SELECT 'user_id', 'msg_id', 'type' UNION
SELECT TO_ID, MESSAGE_ID, 'TO'
FROM MESSAGES
UNION
SELECT CC_ID, MESSAGE_ID, 'CC'
FROM MESSAGES
INTO OUTFILE '".$exchangeFolder."/relations_etc.csv'
FIELDS TERMINATED BY ','
ENCLOSED BY ''
LINES TERMINATED BY '\n'";
$db->execute($sql);
echo "create relations_from.csv\n";
$sql=" SELECT 'user_id', 'msg_id', 'type' UNION
SELECT FROM_ID, MESSAGE_ID, 'FROM'
FROM MESSAGES
INTO OUTFILE '".$exchangeFolder."/relations_from.csv'
FIELDS TERMINATED BY ','
ENCLOSED BY ''
LINES TERMINATED BY '\n'";
$db->execute($sql);
//create indexes for fast import
echo "create index's in neo4j\n";
$cyp="CREATE INDEX ON :user(uid);";
executeCypher($cyp);
$cyp="CREATE INDEX ON :message(mid);";
executeCypher($cyp);
//import nodes
echo "import users.csv\n";
$cyp="USING PERIODIC COMMIT 10000\n
LOAD CSV WITH HEADERS FROM "file:///".$exchangeFolder."/users.csv" AS row\n
MERGE (u:user{uid:row.user_id,name:row.user_name});";
executeCypher($cyp);
echo "import messages.csv\n";
$cyp="USING PERIODIC COMMIT 10000
LOAD CSV WITH HEADERS FROM "file:///".$exchangeFolder."/messages.csv" AS row
MERGE (m:message{mid:row.msg_id,title:row.msg_title});";
executeCypher($cyp);
//import relations
echo "import relations_from.csv\n";
$cyp="USING PERIODIC COMMIT 10000
LOAD CSV WITH HEADERS FROM "file:///".$exchangeFolder."/relations_from.csv" AS row
MATCH(u:user{uid:row.user_id})
MATCH(m:message{mid:row.msg_id})
MERGE (u)-[r:send]->(m);";
executeCypher($cyp);
echo "import relations_etc.csv\n";
$cyp="USING PERIODIC COMMIT 10000
LOAD CSV WITH HEADERS FROM "file:///".$exchangeFolder."/relations_etc.csv" AS row
MATCH(u:user{uid:row.user_id})
MATCH(m:message{mid:row.msg_id})
MERGE (m)-[r:receive]->(u)
SET r.type=row.type;";
executeCypher($cyp);
//clear after import
cleanFolder($exchangeFolder);
Hier sieht man wie der Importer die 50.000 User, 100.000 Messages und insgesamt 300.000 Relations von einer MySQL in die Neo4J Instanz importiert.
Die Festplatte ist nur über SATA-2 Angeschlossen und nicht besonders schnell. Eine SSD, wie für Neo4J empfohlen, würde alles sehr beschleunigen.
Zum Löschen aller Daten aus der Neo4J kann man diese Statement verwenden:
Nachdem wir uns im letzte Teil schon eine Entwicklungsumgebung für Java eingerichtet haben, können wir Desktop Anwendungen schreiben. Aber für Serveranwendungen benötigen wir einen Servlet Container oder einen Application Server. Für Microservices gibt es auch andere Frameworks, aber wir beschränken uns hier erstmal auf eine einfache JSP-Seite.
Ein kleines Servlet kommt auch noch hinzu. Man könnte auch direkt mit JSF anfangen, aber um sich mit dem Thema Webdevelopment in Java vertraut zu machen fangen wir ganz einfach an. Mit JSP und Servlet kann man auch alles bauen. Von einfachen Webanwendungen mit einzelnen Pages, über MVC-Frameworks bis hin zu REST-APIs. Für das meiste gibt natürlich fertige Frameworks, aber es in einem kleinen Beispiel mal selbst zu versuchen, bringt einen oft einen besseren Einblick in diese Bereiche und man versteht, die vorhandenen Frameworks besser und auch warum sie so funktionieren wie sie funktionieren.
Zuerst downloaden wir uns einen aktuellen Tomcat 8. Den Tomcat Servlet-Container gibt es schon seit vielen Jahren.. eigentlich seit Anfang an und entsprang dem Jarkata-Projekt von Apache. Ich bin 2004/2005 mit dem Tomcat 4 angefangenm wo noch alles unter Apache Jarkata tomcat lief und erst später dann mit der 5er Version zum Apache Tomcat wurde. Man wird aber den Begriff Jarkata noch oft genug bei den Libs und Klassen des Tomcat finden.
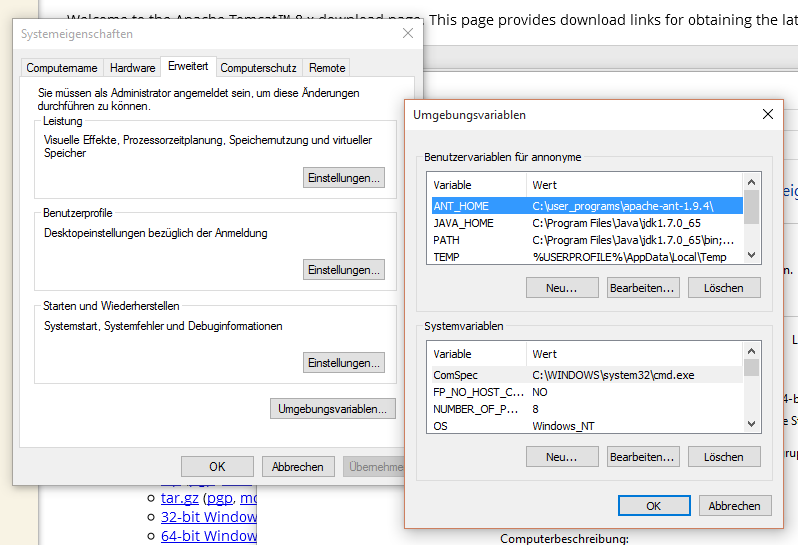
Einfach die passende ZIP-Datei downloaden und an einen beliebigen Ort entpacken. Da wir alles über Eclipse steuern, müssen wir erst einmal da nichts weiter machen. Wer den Tomcat auch mal so ausprobieren möchte muss JAVA_HOME bei den Umgebungsvariablen von Windows setzen und auch den Pfad zum JRE (zum Bin-Verzeichnis) im Path von Windows hinterlegen. Dann kann man im Tomcat-Verzeichnis mit bin/startup.bat den Tomcat starten. Die einfache Startseite sollte dann unter http://localhost:8080/ aufrufen.
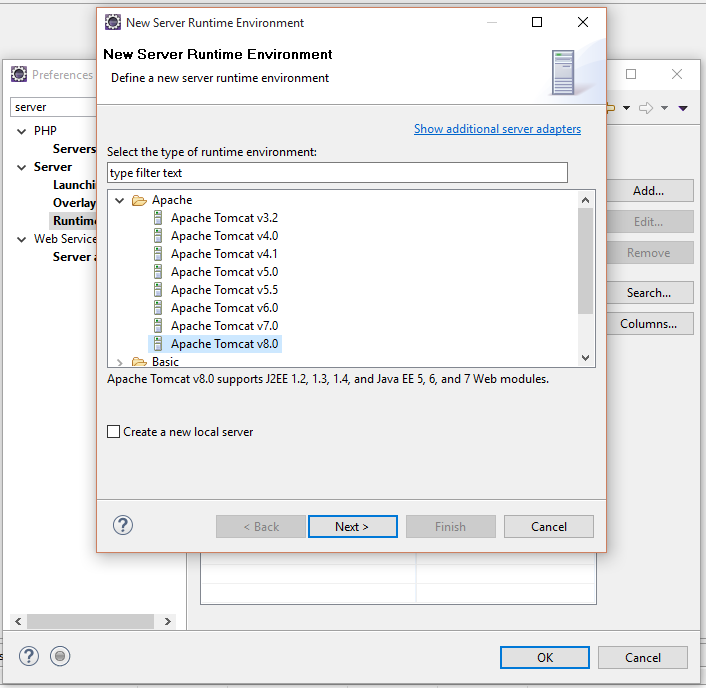
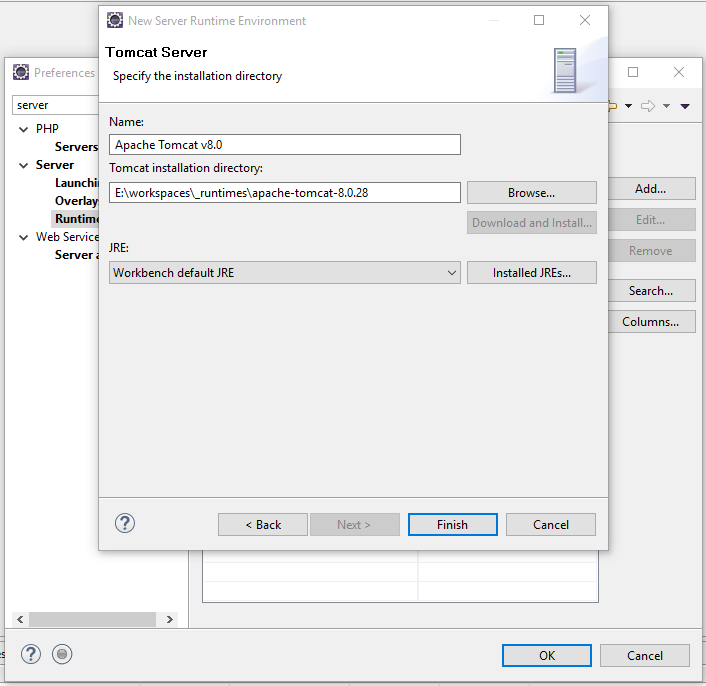
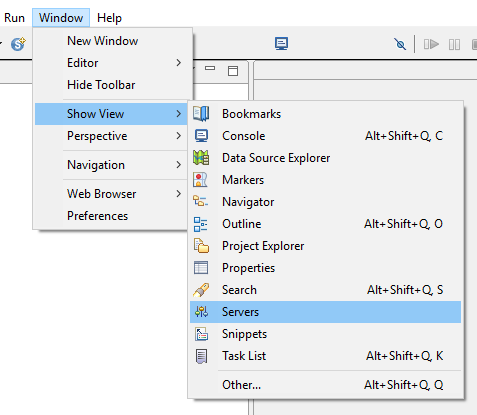
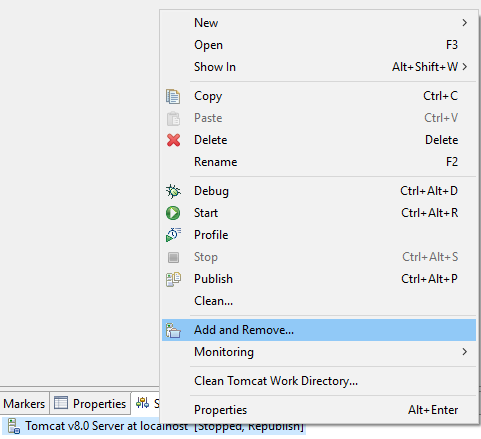
Aber jetzt zurück zu Eclipse. Wir laden unseren Workspace aus dem letzten Teil oder einen anderen den wir benutzen möchten. Wir öffnen Window -- Preferences -- Server - Runtime Environments.
Dort clicken wir auf Add..., um den Tomcat hinzu zufügen.
Wir wählen den Tomcat 8 aus und clicken auf Next. Dann wählen wir unser Tomcat Verzeichnis aus.
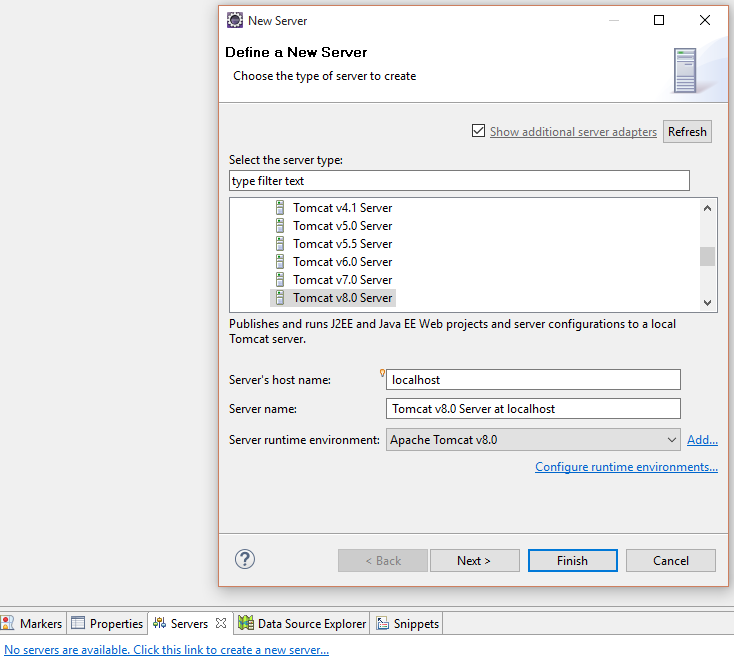
Wenn noch keine Server-View angezeigt wird, müssen wir uns diese nochmal hinzufügen.
Dort clicken wir auf den Link, um einen neuen Server hinzu zufügen. Da wir nur eine Runtime haben, wird uns diese auch direkt vorgeschlagen. Wir übernehmen alle Vorgaben und wählen Finish.
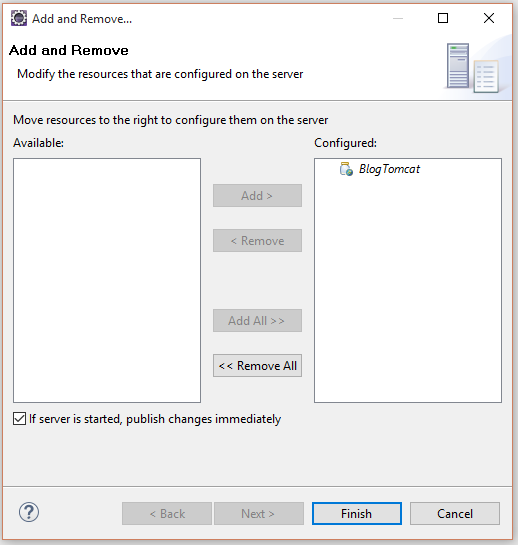
Damit haben wir unseren Server fertig eingerichtet und können nun zu unserem kleinen Beispiel-Projekt übergehen. Wir fangen ganz einfach mit einer JSP-Seite an, bei der wir ein Input-Feld für einen Namen haben, der dann an die Seite übergeben wird und diesen mit Hallo {name}! wieder ausgibt. Klassisch, einfach und die wichtigsten Dinge wie Forms, Request und Ausgabe sind dabei.
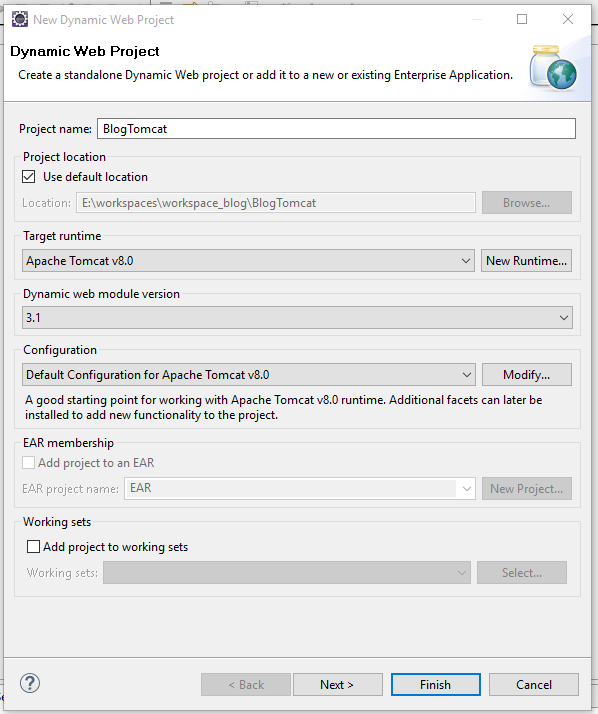
Wir brauchen ein Dynamic Web Project:
Das Projekt fügen wir auch gleich zu den Projekten hinzu die automatisch bei Änderungen neu auf dem Tomcat deployed (wichtiges Wort in der Java-Welt!) werden. Wenn also etwas geändert wird, wird Projekt einmal auf dem Tomcat entfernt und neu hinzugefügt, so dass die Änderungen über einen Webbrwoser betrachtet werden können. So etwas kann bei größeren Projekten paar Sekunden dauern.. aber zum Glück muss nur bei Java-Dateien neu deployed werden. HTML, CSS oder JavaScript Dateien erfordern kein erneutes Deployment und Änderungen sind einfach so verfügbar, weil direkt auf die Dateien zu gegriffen wird und nichts kompiliert werden muss.
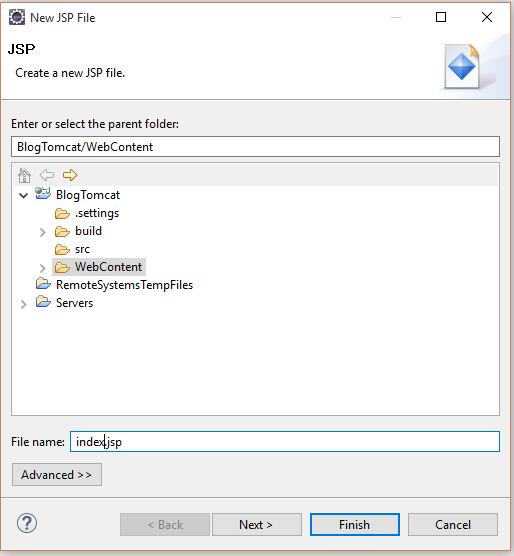
Nun fügen wir uns eine index.jsp hinzu. JSP-Seiten werden im WebContent angelegt, um gefunden zu werden. Die index.jsp ist wie eine index.html und wird beim Aufruf verwendet, wenn keine andere Seite angegeben wurde. Das Verhalten kann man über eine web.xml definieren. Dort kann man auch Servlet-Mappings und Resources definieren. Aber so eine brauchen wir erst einmal nicht.
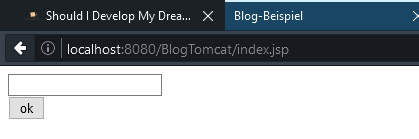
Auf die Seite kommt eine einfache Form und die Ausgabe des Namen, wenn im Request ein Name gefunden wird. Wir übergeben einfach mal den Namen per GET damit man sehen kann, wie der Parameter über die URL übergeben wird. Normal sollte man Form-Eingaben über POST übergeben. Aber die Änderung ist ja im Form-Tag schnell gemacht.
Aufrufen können wir diese Seite mit der URL nach dem Schema http://localhost:8080/{projectname}/ bei meinem Beispiel als http://localhost:8080/BlogTomcat/.
Eine JSP-Seite ist ja nur die Ausgangsdatei und diese wird in ein Servlet kompiliert. Servlets sind gerade für Dinge noch sehr gut, wenn man keine große Ausgaben hat, z.B. für Uploads, Downloads (mit vorherigen Benutzercheck) oder REST-APIs, die einfach immer ein Object in JSON umwandeln. Um schon mal ein Servlet gesehen zu haben erstellen wir unser Beispiel noch mal direkt als Servlet.
@WebServlet(name="nameservlet",urlPatterns={"/name"})
public class NameServlet extends HttpServlet{
private static final long serialVersionUID = 609957577169396811L;
Das URL-Pattern ist hier sehr einfach gehalten. Man kann auch Wildcards und ähnliches setzen, was sehr praktisch ist, wenn man Werte in URLs einbauen möchte, was sehr gut für SEO ist. Beipsiel /service/item/2/ wobei 2 die Id des Item in der Datenbank ist und darüber geladen werden kann.
Wobei wir zum Thema Datenbanken im nächsten Teil kommen, wo wir uns eine Entwicklungsumgebung für PHP einrichten. Da auch dort Eclipse zum Einsatz kommt, sollte man auch wenn man sich nur für Java interessiert den Teil doch mal durchlesen und gerade der Bereich mit der Einrichtung einer MySQL-Datenbank ist interessant, wenn man eine Webanwendung im Tomcat entwickelt. Das Anlegen einer Datasource in der Config des Tomcats werde ich dort auch nochmal kurz erläutern.
Auch im ZF1 ist es sehr einfach einen REST-Service zu implementieren.
public function restAction(){
$this->getHelper('Layout')->disableLayout();
$this->getHelper('ViewRenderer')->setNoRender();
$this->getResponse()->setHeader(
'Content-Type', 'application/json; charset=UTF-8'
);
$data=............;
echo json_encode($data);
return;
}
Man muss nur das Layout und den ViewRenderer deaktivieren und schon kann man sein Response ganz nach Belieben gestalten. Das Vorgehen über das Response als return Wert im Zend Framework 2 finde ich aber insgesamt klarer und strukturierter als die Art und Weise um ZF1.
Ein einfaches Code-Beispiel um mit JavaScript ein Bild in ein schwarz-weiß Bild umzuwandeln. Läuft schnell und ist relativ unkompliziert einzubauen.
if(this.color=="bw"){
var idata=ctx.getImageData(0,0,ctx.canvas.width,ctx.canvas.height);
var data=idata.data;
for(var i=0;i<data.length;i+=4){
var grayValue=data*0.3+data[i+1]*0.59+data[i+2]*0.11;
Nun haben wir unsere Daten in entsprechend aufbereiteter Form. Was noch fehlt ist, dass wir die Daten an unser Script senden, das dann alles Speichert. Das ist an sich der elementare Teil hier und wie wohl erwartet an sich auch der einfachste Teil. Da wir einfach mit append immer hinten an die Datei ran schreiben, bleiben wir synchron. Sollte man asynchron werden wollen, müßte man die Nummer des aktuellen Teils und die gesamt Zahl der Teile mitsenden. Dann och die Größe der Teile und man könnte eine Dummy-Datei erzeugen mit der gesamten Größe und dann die Teile immer an den entsprechenden Bereichen einfügen. Sollte an sich auch nicht so kompliziert sein und am JavaScript-Code würde sich kaum was ändern, ausser den paar mehr Infos im Request.
Aber erstmal alles Synchron, weil wir dann auch einfach mit einer for-Schleife durch unser Array durch laufen können.
var result;
for(var i=0;i<chunks.length;i++){
var last=false;
if(i==(chunks.length-1)){
last=true;
}
result=uploadFileChunk(chunks,filenamePrefix+file.name,url,params,last);
}
return result;
Es wird nur das Result des letzten Teil-Uploads zurück geliefert. Weil dort dann meistens auch die Datei nochmal umkopiert wird und entsprechende Datenbankeinträge vorgenommen werden. Es ist gut die Datei erstmal in einem separaten Verzeichnis als *.part oder so zu speichern und erst wenn der letzte Teil (last Variable) angekommen und gespeichert die DB-Einträge und an einen entsprechenden Ort zu kopieren. Über den Ordner mit den *.part Dateien kann dann ein Cron-Job laufen der alle dort vorhanden *.part Dateien entfernt die länger als 20min nicht geändert wurden.
Ich übergebe noch einen Prefix für den Filename, dann kann am Server userid+filenname+prefix+parterweiterung als Dateiname verwendet werden. Damit ist es auch für einen User möglich Dateien mit selben Dateinamen hochzuladen ohne dass es am Server zu Verwechselungen kommt.
Idealer Weise sollte noch mal der eigentliche Dateiname zusätzlich noch mal mit übergeben werden. Ist hier im Beispiel nicht so hat direkt ersichtlich, weil der Name mit in den "params" steht wo auch noch alle möglichen anderen Daten für das Request mit drin stehen können.
function uploadFileChunk(chunk,filename,url,params,lastChunk) {
var formData = new FormData();
formData.append('upfile', chunk, filename);
formData.append("filename",filename);
for(key in params){
formData.append(key,params[key]);
}
Hier der eigentliche Uplaod-Code. Ansich entspricht es einer Form nur eben rein in JavaScript. Die Daten der Form werden dann per AJAX-Request an das Script geschickt.
Nach dem wir nun unser File-Object haben, wollen wir es in kleine Teile zerlegen, die wir dann einzelnd hoch laden
können. JavaScript kann seit einiger Zeit super mit Dateien umgehen. Direkter Zugriff auf das Dateisystem ist natürlich nicht möglich aber Öffnen- und Speicherdialoge reichen ja auch. Um anders Datenabzulegen gibt es noch die indexeddb von JavaScript auf dich in vielleicht in einem weitern Eintrag mal eingehe. Aber ansosnten kommen wir mit Öffnen/Drag and Drop und Speichern vollkommen aus.
function createChunksOfFile(file,chunkSize){
var chunks=new Array();
var filesize=file.size;
var counter=0;
while(filesize>counter){
var chunk=file.slice(counter,(counter+chunkSize));
counter=counter+chunkSize;
chunks[chunks.length]=chunk;
}
return chunks;
}
Die Methode arbeitet an sich ganz einfach. Die Schleife läuft so lange wie die kopierte Größe kleiner ist als die Gesamtgröße der Datei. Bei slice(from,to) gibt man den Anfang und das Ende an. Wenn das Ende hinter dem realen Ende der Datei liegt wird nur das was noch vorhanden war kopiert und kein Fehler geworfen, was es uns hier sehr einfach macht. Wir addieren also z.B. bei jeden Durchlauf 250000 auf die aktuelle Kopie-Größe rauf, bis wir über der Dateigröße liegen. Bei jedem dieser Durchläufe wird von der Position der Größe der Kopie bis zu der Größe + Größe des zu kopierenden Teils, der Teil der Datei mit in ein Array kopiert.
Am Ende haben wir also ein Array mit den Teilen der Datei in der korrekten Reihenfolge.
Man hätte natürlich vorher die Anzahl der Teile ausrechenen können und dann mit einer for-Schleife und für jeden Teil die Position in der Datei berechnen können.. ich fand es so aber erstmal einfacher.
var chunks=createChunksOfFile(file,250000);
Damit erhalten wir Array mit alleien Teilen der Datei zu je ~250KB. Eine Datei von 1MB hätte also ~4 Teile. Alles ungefähr weil eben 250000 keine exakten 250KB sind (1024Byte wären ja 1KB... aber das will uns hier mal nicht interessieren).
Ein einfacher Fileupload ist einfach zu erstellen. Ein <input> vom Typ "file" in eine Form. "method" auf "post" und "action" auf die Zielseite. enctype="multipart/form-data" nicht vergessen und schon ist alles erledigt.
Nun hat diese Implementierung natürlich ihre Grenzen und bei heuten Web-Anwendungen will man oft nicht mehr nur einfach eine Datei hochladen. Man will Bilder vorher bearbeiten und skalieren. Den Fortschritt des Uploads sehen und mehrere Dateien in einer Queue hochladen lassen. Früher nutzte man für sowas Flash.. aber Flash ist tot. Heute hat man HTML5 und JavaScript. Damit kann man alles realisieren was man sich für einen File-Upload wünscht. Die File-API hilft die Dateien zu Laden (aus einem <input> oder auch per Drag and Drop). Per Notification kann man den Benutzer über den Zustand der Uploads informieren, z.B. eine Benachrichtigung ausgeben wenn eine besonders große Datei fertig hochgeladen wurde.
Der hier entworfene File-Upload ist natürlich auch nicht perfekt, aber er funktioniert gut in mehreren Projekten und Scripte um die Hochgeladenen Dateien entgegen zunehmen und zu Speichern, lassen sich gut in PHP oder als Servlet realsieren.
Für Tests reicht ein einfaches PHP-Script:
PHP:
<?php
//see $_REQUEST["lastChunk"] to know if it is the last chunk-part or not
if(isset($_FILES["upfile"])){
file_put_contents($_REQUEST["filename"],file_get_contents($_FILES["upfile"]["tmp_name"]),FILE_APPEND);
}
?>
oder für Java (FileIOToolKit ist eine eigene Klasse wo append einfach das byte[] an eine Datei ran hängt oder damit eine neue Datei erzeugt, wenn diese noch nicht existieren sollte):
String filename = request.getParameter("filename");
for (Part part : request.getParts()) {
if (part.getName().equals("upfile")) {
byte[] out = new byte[part.getInputStream().available()];
part.getInputStream().read(out);
Wie man hier schon sieht wird die Datei nicht als ganzes hochgeladen sondern in mehreren Stücken. Das hat den Vorteil, dass man sehr sein den Fortschritt beim Upload bestimmen kann.
Das Laden einer Datei ist relativ einfach. Das Drag and Drop oder das onChange einer <input> vom Typ "file" liefern jeweils ein Event, dass die Dateien enthält (es können immer mehrere sein!).
Hier ein einfaches Beispiel, wobei ein boolean verwendet wird, um die beiden Arten zu unterscheiden:
var files = null; // FileList object
if(!nodragndrop){
files=evt.dataTransfer.files; //input
}
else{
files=evt.target.files; //drag and drop
}
Wir werden aber das Laden ignorieren und davon ausgehen, dass man ein File-Object hat, egal ob aus einer Datei oder vielleicht auch vom JavaScript-Code erzeugt (eine Anleitung wie man die Data-URL in sowas umwandelt findet man in einem älteren Beitrag, wo man lernt wie man ein Bild vor dem Upload automatisch verkleinert).
Im nächsten Teil wird das File dann in kleine Teile zerlegt.
Eine der Stärken bei Java sind die Threads und die ExecutorServices, die die Workloads auf einen festen Pool von Threads verteilen und dann die Ergebnisse Sammeln (Future<...>). Man kann natürlich auch alles in einer großen Schleife erledigen. Bei JavaScript hat man aber das Problem, dass nicht stoppende Scripte sehr schnell gestoppt werden. Das mit Timeouts zu lösen scheitert ganz schnell wenn einzelne Workloads zu lange dauern. Aus diesem Grund wurden die WebWorker entwickelt, die es erlauben nebenläufige Vorgänge in JavaScript zu realisieren und somit auch diese Probleme mit Timeouts von Scripts zu umgehen.
WebWorker und das Hauptscript kommunizieren dabei über Nachrichten, die hin und her geschickt werden. WebWorker können dabei entweder die ganze Zeit existieren oder man kann diese auch direkt nach dem erledigen der Aufgabe wieder beenden. In den meisten Fällen ist
dieses Verhalten wohl das Beste.
Man kann z.B. auch in einem Spiel AI-Gegner mit WebWorkern realisieren. Dann muss der WebWorker natürlich nach dem Starten so lange existieren bis er von außen die Nachricht erhält sich zu beenden.
Man schreibt einen WebWorker, der gegen einen zweiten antritt und versucht möglichst viel Fläche des Spielfeldes mit seiner Farbe zu markieren. Die Kommunikation ist sehr einfach. Der WebWorker gibt über postMessage() in einen JavaScript-Object eine Direction an das Hauptscript zurück und bekommt im nächsten Schritt das Ergebnis ob der letzte Schritt funktioniert hat. Anhang dieses Ergebnisses muss der WebWorker seinen nächsten Schritt planen. Der eigentliche WebWorker ist in der onmessage-Function gekapselt.
Also schickt das Hauptscript eine Message, onmessage des Workers reagiert und darin wird mit postMessage ein Ergebnis zurück geschickt.
Das ist die Struktur nach der WebWorker funktionieren.
Die Kommunikation hat natürlich Grenzen. Ein Element aus dem DOM an einen WebWorker zu über geben und dann dort zu ändern funktioniert (wie man wohl schon erwartet hat) nicht. Wenn man mit einem Canvas etwas machen will muss man die getImageData() Methode bemühen.
Wenn man mit einem WebWorker arbeitet hat man oft den Wunsch auch hier mit Scripten aus externen JS-Files zu arbeiten. Die klassische Variante mit den <script>-Tags funktioniert hier natürlich nicht. Dafür gibt es die importScripts-Function. Der Pfad ist relativ zur Datei des
WebWorkers anzugeben.
Beispiel:
importScripts('../lib/libwebp-0.1.3.demin.js');
Anstelle von onmessage direkt im Script kann man die Haupt-Function auch natürlich über addEventListener setzen, was sehr viel sauberer
aussieht.
Es sollte sowie so beim WebWorker immer "self" verwendet werden.
Die an den WebWorker übermittelten Daten erhält man ganz klassisch über das Event.
var data=event.data;
Was in den Daten drin steht hat man ja selbst bestimmt.
Am Ende der Haupt-Function wird dann das Ergebnis zurück geschickt und wenn gewünscht der WebWorker von sich heraus auch beendet. Der WebWorker kann auch von außen beendet werden, aber es ist wohl sicherer, wenn er sich selbst schließt.
So. Nachdem wir nun wissen wie der WebWorder intern funktioniert, bleibt am Ende eigentlich nur noch die Frage, wie man nun so einen WebWorker aus dem Haupt-Script heraus startet und wie man die Ergebnisse entgegen nehmen kann. Das ist aber an sich nicht wirklich kompliziert und da alles ja auch Event-Listener und Events setzt, ist nicht schwer zu erraten wie zurück geschickt Messages verarbeitet werden können.
function func(controller){
return function(event){
controller.doSomeThing(event.data);
};
};
var worker = new Worker('./controllers/webpWorker.js');
worker.addEventListener('message', func(this), false);
worker.postMessage(post);
Das Closure der Funktion ist noch das komplexeste hier dran. Der Code hier wird in einer Methode des Controllers ausgeführt und um die Verarbeitung des Ergebnisses in einer anderen Methode des Controllers durch zu führen muss eben der Controller der Function mit einem Binding an das WebWorker-Object im Hauptscript bekannt sein. Closures sind sehr wichtig und ohne diese JavaScript zu schreiben ist extrem umständlich und depremierent. Also wenn das Konzept noch nicht kennt, sich das als erstes erst einmal ansehen!
Die in "post" übergeben Daten findet man im Event im WebWorker unter event.data wieder.
Das hier war jetzt doch relativ kurz gehalten, aber zeigt hoffentlich die Hauptstrukturen sehr gut und reicht für erste Experimente.
Blog-entries by search-pattern/Tags:
Möchtest Du AdSense-Werbung erlauben und mir damit helfen die laufenden Kosten des Blogs tragen zu können?
 bezahlt von
bezahlt von  Blog: Blog-entries by search-pattern/Tags:
Blog: Blog-entries by search-pattern/Tags: