Ich habe mich dabei an http://tecadmin.net/install-php-7-on-ubuntu/ orientiert.
Unter Ubuntu < 16.04 PHP 7.0 zu installieren ist gar nicht schwer, wenn man erst einmal weiß, wie es geht. Man muss sich ein zusätzliches PPA einrichten und sonst nicht viel machen.
sudo add-apt-repository ppa:ondrej/php
sudo apt-get update
sudo apt-get install -y php7.0
Damit ist PHP 7.0 an sich schon installiert. Das kann man sehen wenn die Version überprüft (immer die zuletzt installierte Version wird hier verwendet)
php -v
Wenn man nun eine Liste an Modulen haben will bekommt man diese so:
sudo apt-cache search php7-*
Wichtig ist, dass XDebug weiterhin unter php-xdebug zu finden ist und deswegen hier nicht in der Liste auftaucht. Also alles aus der Liste installieren was man braucht.
sudo apt-get install php7.0-mysql php7.0-json php7.0-xml php-xdebug
Nun muss PHP7.0 nur noch aktiviert werden. Ich gehe mal davon aus das momentan eine PHP5-Version aktiv ist.
sudo service apache2 stop
sudo a2dismod php5
sudo a2enmod php7.0
sudo service apache2 start
Danach ist der Apache wieder da und läuft mit PHP7.0
Wer ein aktuelles Linux Mint verwendet muss unter Umständen noch das PHP7.0 Apache Modul nach installieren und auch den ganzen Kleinkram.
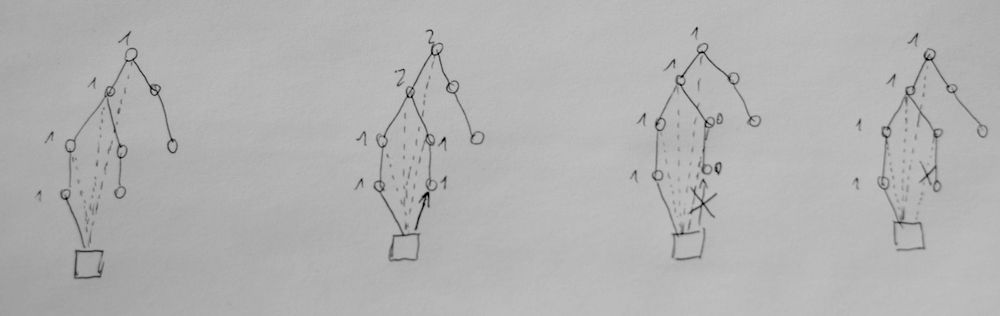
Nested-Sets sind für normale Baumstrukturen super, aber wenn man etwas flexibler sein möchte und z.B. ein Item in mehreren Kategorien haben möchte oder eine Kategorie auch als Kind-Element von z.B. einer Angebots-Kampanie, ist man schon nicht mehr bei einem Baum sondern bei einem Netz. Nun hier Eltern-Elemente zu finden und zu wissen in welchen Kategorien ein Item sich befindet ist etwas aufwendiger.
CREATE TABLE exp_structure(
ID int(11) UNSIGNED NOT NULL AUTO_INCREMENT,
NAME VARCHAR(255) NOT NULL,
TYPE VARCHAR(255) NOT NULL,
PRIMARY KEY(ID)
);
CREATE TABLE exp_links(
ID_PARENT int(11) UNSIGNED NOT NULL,
ID_CHILD int(11) UNSIGNED NOT NULL,
IS_SHADOW_LINK int(1) DEFAULT 0,
REFCOUNT int(1) DEFAULT 0,
PRIMARY KEY(ID_PARENT, ID_CHILD)
);
Damit man nun schnell herausfinden kann wird, beim Anlegen eines Items in der Struktur wird nicht nur ein Link auf das direkte Parent-Element gesetzt sondern werden auch rekursiv alle weiteren Parent-Element aufgerufen und ein Shadow-Link darauf gesetzt. Dieser Shadow-Link besagt, dass das Item nicht direkt am Parent-Element hängt sondern Subelement zugeordnet ist. In der Oberfläche sind mit Shadow-Links verlinkte Items also nicht anzuzeigen.
Ist ja erst einmal ganz einfach. Wenn ich nun aber z.B. ein Item mit 2 Parent-Elementen habe, muss man wenn man weiter nach oben in die Hierarchie kommt darauf achten, dass man nicht mehrere Shadow-Links setzt. Das ist an sich auch kein großes Problem. Schwierig wird wenn man ein Item entfernt und die Shadow-Links entfernen muss. Bei jedem Shadow-Link müsste man prüfen, ob er durch einen weiteren Pfad noch verwendet wird oder nicht. Dafür gibt die REFCOUNT... ja genau.. wie im Garbage Collector. Wenn man ein Shadow-Link setzten soll, dieser aber schon existiert zählt man Counter hoch. Beim Entfernen zählt man einfach alle Shadow-Links des Pfades runter und entfernt dann alle die auf 0 stehen, weil man dann sicher ist, dass dieser Shadow-Link nicht noch von einem anderen Pfad verwendet wird.
Wenn man noch einzelne Nodes oder Relations hat, kann man eine Summe schnell und einfach mit sum() berechnen. Wenn man aber schon eine Collection vorliegen hat oder komplexere Berechnungen ausführen möchte, hilft hier die
reduce() Funktion.
Die an sich wie eine kleine Schleife arbeitet und einen Ausdruck auf jedes
Element einer Collection ausführt.
Das man eine direkt eine Collection erhält, kann ganz schnell der Fall sein. Gerade wenn man mit variablen Path Längen arbeitet.
MATCH p = (start:entity{id:4})-[:relates_to*1..10]->(end:entity{id:100})
RETURN p
hier erhält man alle Relations bis zu einer Anzahl von 10, die einen Path zwischen start und end bilden.
Will man nun Gewichtungen an den Relations zusammen rechnen, damit nicht nur die Anzahl der Relations als Bewertung genutzt werden kann, kommt reduce() zum Einsatz.
Mit so einem Prinzip kann man auch reale Wege mit Meter-Angaben zwischen Stationen und Wegpunkten und Neo4j abbilden.
MATCH p = (start:entity{id:4})-[rels:relates_to*1..10]->(end:entity{id:100})
RETURN reduce(weight=0, r in rels) | weight + r.weight) AS total_weight
Wenn man nicht möchte, dass ein CodeMirror Eingabefeld unkontrolliert in die Breite wächst und statt desen Scroll-Balken zeigt, hilft dieses CSS:
<style type="text/css">
.CodeMirror{
width:99%;
max-width:700px;
border:1px solid #000000;
}
</style>
 bezahlt von
bezahlt von