Nested-Sets sind für normale Baumstrukturen super, aber wenn man etwas flexibler sein möchte und z.B. ein Item in mehreren Kategorien haben möchte oder eine Kategorie auch als Kind-Element von z.B. einer Angebots-Kampanie, ist man schon nicht mehr bei einem Baum sondern bei einem Netz. Nun hier Eltern-Elemente zu finden und zu wissen in welchen Kategorien ein Item sich befindet ist etwas aufwendiger.
CREATE TABLE exp_structure(
ID int(11) UNSIGNED NOT NULL AUTO_INCREMENT,
NAME VARCHAR(255) NOT NULL,
TYPE VARCHAR(255) NOT NULL,
PRIMARY KEY(ID)
);
Damit man nun schnell herausfinden kann wird, beim Anlegen eines Items in der Struktur wird nicht nur ein Link auf das direkte Parent-Element gesetzt sondern werden auch rekursiv alle weiteren Parent-Element aufgerufen und ein Shadow-Link darauf gesetzt. Dieser Shadow-Link besagt, dass das Item nicht direkt am Parent-Element hängt sondern Subelement zugeordnet ist. In der Oberfläche sind mit Shadow-Links verlinkte Items also nicht anzuzeigen.
Ist ja erst einmal ganz einfach. Wenn ich nun aber z.B. ein Item mit 2 Parent-Elementen habe, muss man wenn man weiter nach oben in die Hierarchie kommt darauf achten, dass man nicht mehrere Shadow-Links setzt. Das ist an sich auch kein großes Problem. Schwierig wird wenn man ein Item entfernt und die Shadow-Links entfernen muss. Bei jedem Shadow-Link müsste man prüfen, ob er durch einen weiteren Pfad noch verwendet wird oder nicht. Dafür gibt die REFCOUNT... ja genau.. wie im Garbage Collector. Wenn man ein Shadow-Link setzten soll, dieser aber schon existiert zählt man Counter hoch. Beim Entfernen zählt man einfach alle Shadow-Links des Pfades runter und entfernt dann alle die auf 0 stehen, weil man dann sicher ist, dass dieser Shadow-Link nicht noch von einem anderen Pfad verwendet wird.
Die PREG_-Funktionen von PHP sind sehr einfach zu verwenden und sehr mächtig.
Ich habe die Einfachheit bei Java vermisst. Java ist da sehr viel komplexer. Also habe ich die Java Funktionalität in Methoden verpackt, die von der Struktur den PHP-Funktionen sehr gleichen und sich auch genau so verwenden lassen. Etwas Prozedur-orientiertes Programmieren in Java.
public static List<String> matchAll(String pattern, String source) {
List<String> result = new ArrayList<String>();
Matcher m = Pattern.compile(pattern).matcher(source);
while (m.find()) {
result.add(m.group());
}
return result;
}
public static List<String> split(String pattern, String source) {
String[] parts = source.split(pattern);
List<String> list = new ArrayList<String>();
for (int ii = 0; ii < parts.length; ii++) {
list.add(parts[ii]);
}
return list;
}
public static List<String> find(String pattern, String source) {
List<String> result = new ArrayList<String>();
Pattern compiled = Pattern.compile(pattern);
Matcher matcher = compiled.matcher(source);
while (matcher.find()) {
result.add(matcher.group());
}
Ich habe mal etwas rumgepsielt und versucht so etwas wie die Enums auf Java in PHP abzubilden. Es ist mir mehr oder weniger gut gelungen. Aber für einfache Status und Fehler-Fälle sollte es funktionieren.
<html>
<body>
<?php
class ErrorCodesEnum{
private static $instance=null;
public $code='';
public $name='';
public $message='';
public $error1 = null;
public $error2 = null;
private function __construct($code='',$name='',$message=''){
if($code!=''){
$this->code=$code;
$this->name=$name;
$this->message=$message;
}
else{
$this->error1=new ErrorCodesEnum('0001','#1','run into error 1');
$this->error2=new ErrorCodesEnum('0002','#2','run into error 2');
}
}
static public function instance(){
if(self::$instance==null){
self::$instance=new ErrorCodesEnum();
}
return self::$instance;
}
}
Lange Zeit habe ich auch immer bei Columns von Datenbank-Tabellen immer ein Prefix verwendet. Die Tabelle TESTS hatte dann z.B. die Spalte TEST_ID. Daran ist ja auch erstmal nichts verkehrt. Probleme gab es mit Oracle und der Beschränkung auf 30 Zeichen für den Spaltennamen in einigen Fällen.
$entity->setId($data["TEST_ID"]);
Der Code oben funktioniert auch super, wenn man jedes Value "per Hand" in das Object schreibt.
Wenn wir aber nun ein automatisches Mapping über Annotationen nutzen kann es in einigen Fällen schnell umständlich werden.
Wenn wir keine Ableitung und Vererbung benutzen, ist auch hier kein Problem zu erwarten. Wenn wir aber eine Basic-Klasse verwenden, von der alle anderen Klassen ableiten, haben wir schnell ein Problem, weil wir in der Basic-Klasse in den Annotationen einen Platzhalter für den Prefix verwenden müssten. Ohne Prefix geht es hier sehr viel einfacher.
/**
* @dbcolumn=ID
*/
private $id=0;
/**
* @dbcolumn={prefix}_ID
*/
private $id=0;
Deswegen sollten Prefixe nur bei FKs verwendet werden, um ein automatisches Mapping unkompliziert nutzen zu können. Wenn man es jetzt nicht nutzt, will man es später vielleicht und kann dann jetzt schon alles so bauen, um später keine Probleme zu bekommen. Platzhalter funktionieren natürlich auch.. gehen aber zur Lasten der Performance.
Gerade im Zend Framework 2 kommt man immer mehr in Bereiche wo man auf altbekannte Konzept aus der Enterprise Welt und dort auch auf viel bekanntes aus Java (EE) trifft. Neben Depenency-Injection und Factories, findet man immer wieder gute Möglichkeiten Konzept wie DAO oder
auch POPOs als PHP-Variante der POJOs anzuwenden (wobei ich hier POJO und Bean gleichsetzen würde).
Auch Getter und Setter gehören hier genau so zum Alltag wie in Java.
Ich möchte hier ein paar Beispiele geben, wie man eine einfache Umsetzung in einem ZF2-Modul realsieren kann. Ich gehe einfach mal davon aus, dass man in der Lage ist ein einfaches Module in ZF2 zu erstellen und auch sich mit Controllern ViewModel und TableGateway zu mindest einmal beschäftigt hat. Der Einstieg ist nicht besonders einfach, wenn man keine lauffähige Anwendung hat, in die man sich einarbeiten kann.
Die hier umgesetzten Ansätze, sollen die Entwicklung möglichst beschleunigen und viel Code sparen, der in vielen Beispielen auch mit drin ist und alles sehr unübersichtlich macht. Auch wenn hier einige Ableitungen vorkommen halte ich das exesive Ableiten und Vererben für einen falschen Ansatz. Factories und Dependency-Incetion halte ich für einen besseren Weg eine Klasse mit bestimmten Eigenschaften auszustaten.
Ich leite auch vom TableGateway ab, wobei die bessere Methode es wohl wäre in der Factory mit Hilfe des ServiceManagers ein TableGateway zuerstellen und dieses an den entsprechenden Constructor zu übergeben.
Aber fanden wir einfach mal mit dem Model bzw der Entität an.
public function setName($name){
$this->_name=$name;
}
public function getValue(){
return $this->_value;
}
public function setValue($value){
$this->_value=$value;
}
}
Die voran gestellen _ entsprechen dem Zend Code-Style und sollen private und protected Attribute der Klasse deutlicher hervor haben.
Eigentlich sollte ja jedes Attribute der Klasse private oder protected sein. Nur wer die PHP eigenen JSON Funktionen oder Klassen verwendet, könnte man in die Verlegenheit kommen etwas public zu machen, aber auch hier gibt es bessere Lösungen.
Ich halte wenig davon alle Attribute grundsätzlich auf protected zu setzen, nur weil die Möglichkeit besteht mal eine Klasse ableiten zu wollen.
In den meisten Fällen, sollte man dann überlegen, ob es wirklich eine andere Entität ist oder man die vorhandene erweitern oder anpassen könnte so, dass keine weitere sehr ähnliche Entität nötig wird. Ableiten von einer BasicEntity oder einem BasicModel ist natürlich sinnvoll. Aber konkrete fachliche
Entitäten abzuleiten ist meistens weniger sinnvoll.
Nun kommen wir zu einem Punkt, der in der ZF2-Welt oft anders gesehen wird. Ich leite das Model nicht direkt vom TableGatway ab. Das Problem ist hier, das man für das TableGateway einen DBAdapter benötigt den man mit Hilfe des ServiceManagers bekommt. Also muss man beim Erzeugen des Model-Objekts immer diesen übergeben und das TableGateway instanzieren. Das kann man natürlich super mit den Factories des ZF2 erledigen. ABER.. wenn ich eine Liste des Models aus der DB lade und in einer Schleife mir für jede Row aus der DB eine Instanz der Klasse erzeuge ist das Vorgehen jede Instanz über diesen Factory bauen zu lassen, alles anderes als elegant oder schnell.
Also bleiben wir bei unserem einfachen POPO und erstellen für die Zugriffe auf die Datenbank nutzen wir eine weitere Klasse. Für jedes Model/Entity erzeugen wir uns eine DAO-Klasse. Diese enthält alle Methoden zum Laden, Speichern und Löschen sowie Listen laden des Models. Wie für fast jedes DAO benötigen wir hier eine Factory um die Einstellungen des Systems (DB-Verbindung) dem DAO bekannt zu machen.
Die Factory tragen wir in der module.config.php ein, die wir in der Methode getConfig der Module.php laden.
$sm ist der ServiceManager, den wir hier an den Constructor des DAOs übergeben. Der Constructor nutzt diesen um den DBAdapter zu bekommen und an das TableGateway weiterzugeben. Wie schon weiter oben geschrieben, hätte man dies auch in der Factory machen können und das TableGateway hier an das DAO übergeben können. Könnte einen etwas Code sparen es so zu machen.
Nun möchte man den DAO in dieser Art und Weise gerne verwenden:
Dafür schreiben wir uns jetzt einen eifnachen DAO, der erstmal nur die load-Methode enthält:
class XWTestDAO extends TableGateway{
$this->_sm=null;
public function __construct($serviceManager){
$this->_sm=$serviceManager;
parent::__construct(
$this->_tableName,
$serviceManager->get('dbAdapter')
);
}
//eine einfache Methode zum Kopieren der Daten aus dem Array in das Objekts
private function _copyData($entity,$array){
$dbm=new XWDBMapper();
return $dbm->setValuesFromArray($entity,$array);
}
public function loadTest($id){
$entity=new XWTest();
if($id!=null && $id>0){
$rsetItem=$this->select(
array('test_id' => $id)
)->current();
Ideal wäre es hier, wie man deutlich sehen kann 'test_id' auch später mal durch Annotationen zu ersetzen. Dafür wäre eine Annotation wie @tableid dann geeignet nach der man sucht und sich dann den @dbcolumn-Eintrag aus dem selben DocComment-Block heraus liest.
Aber so weit ist es ja schon mal ganz schön. Wie brauchten kein Array zu erzeugen und sonst haben wir wenig Code schreiben müssen.
Das wichtigste fehlt hier aber natürlich noch. Wie mappe ich die Annotationen auf das Array und umgekehrt?
Dieser Mapper ist ansich auch nicht wirklich kompliziert und basiert hauptsächlich darauf mit der RefelcetionClass zu arbeiten und mit deren Hilfe die ReflectionProperties zu bekommen.
class XWDBMapper{
public function getColumnNameFromDoc($doc){
$result=null;
if(preg_match("/@dbcolumn=[a-zA-Z0-9_]+/",$doc)){
$result=preg_replace("/^.+@dbcolumn=([a-zA-Z0-9_]+)\s.+$/Uis","$1",trim($doc));
}
return $result;
}
Sehr wenig Code und erleichtert einen das Leben sehr. Ist auch relativ schnell. Das händische Schreiben bzw Mappen der Arrays war doch immer sehr fehleranfällig und wenn man mal eine Column zur Datenbanktabelle hinzugefügt hat, müsste man an vielen stellen diese nachpflegen und hoffen, dass man keine Stelle vergessen hat. Jetzt muss man nur noch eine Annotation einbauen und es wird immer richtig gemappt.
Nachdem wir also nun das Laden einmal durchgegangen sind, kommt hier nur kurz die Methode für den Mapper, wie man ein Array aus einem Objekt erhält (die meisten werden schon wissen wie man die Methode da oben umdrehen kann). Deswegen brauche ich hier wohl auch nicht viel dazu schreiben.
Um jetzt alles noch schneller zu machen könnte man sich einen Cache für die Propert-Liste schreiben, dass diese nicht immer und immer wieder erzeugt werden muss. Beim Laden von Listen wäre das ein großer Vorteil. Aber selbst so ist alles schon sehr schnell. Jeden Falls habe ich zwischen den beiden Varianten bis jetzt in der Benutzung der Anwendungen keinen gravierenden Unterschied feststellen können, was die Performance betrifft. Mit XDebug durch gemessen habe ich noch nicht.
So haben wir mit nur eine paar kleinen Zeilen Code uns viel Arbeit erspart.. vielleicht habe ich hiermit noch anderen deren Arbeit vereinfacht.
Neben DevOps hört man viel über Microservices. Oft sogar zusammen. Der gute Gedanke bei Microservices ist meiner Meinung nach jeden Falls, dass eine gute Modularisierung angetrebt wird. Etwas was ich auch immer in meinen Projekten versuche, aber viele doch es immer wieder für zu kompliziert halten und bei riesigen monolithischen Klötzen bleiben wollen. Aber sich auch dann beschweren, dass das Deployment immer so lange dauert und dass einige Entwickler einfach so frech waren und ihre Methoden geändert haben. Bei diesen riesigen monolitisches Klötzen ohne Abschottungen neigen viele dazu direkt mit fremden Klassen oder NamedQueries zu arbeiten. Wenn ich aber eine Service-Fascade hat und dort meine Methode auf eine andere interne umleite, die sehr viel schneller ist als die alte und die alte entferne, kommen Beschwerden, weil die eine Methode nicht mehr auffindbar ist und ein anderer Teil der Anwendung jetzt nicht mehr funktioniert.
Antworten wie "Benutz einfach die Service-Methode, die liefert dir immer genau was du brauchst", sind dann aber nicht gerne gehört.
Microservices haben eben diesen Vorteil, dass viel mit Schnittstellen gearbeitet werden muss. Damit kommt dann vielleicht auch ein Gefühl dafür Service-Methoden kompatibel zu halten. Nicht einfach vorhandene Methoden von der Aufrufstruktur zu vrerändern, sondern eine neue Methode anzulegen und die alte dann mit standard Werten auf die neue weiter zu leiten.
Der einfachste Gedanke zu Microservices ist bei mir immer eine WAR-Datei. Eine Anwendung auch auf mehrere WAR zu verteilen. Die inter-Modul Kommunikation ist dann auch über URLs oder intern über vielleicht JNDI zu realisieren. Aber alles ist sehr isoliert und man kann einzelene
Teile deployen ohne dass andere auch neu deployed werden müssen.
In PHP habe ich das mit meinem Framework von Anfang an (bzw es hat sich entwickelt) so umgesetzt. Module sind 100%ig getrennt und ein Update eines Modules ist durch einfaches Kopieren in das richtige Verzeichnis möglich. Die Module orientieren sich an sich schon etwas an klassischen WAR-Dateien aus der Java-Welt. Jedes Modul bringt seine eigenen Klassen, seine eigene Admin-Oberfläche, seinen eigenen REST-Service und eben Views mit. Es ist nichts fest in Config-Dateien eingetragen, deswegen sich das System auch nicht beschweren kann, wenn ein Modul plötzlich weg ist. Das dynamische Zusammensuchen und Instanzieren von Modulen und Addons kostet natürlich Zeit, aber hält das System sehr flexibel und robust, weil meistens nichts vom Grundsystem vorraus gesetzt wird. Caching ist hier natürlich doch ein gewisses Problem, aber das kann man auch lösen. Meistens reicht es Module zu dekativieren und man muss sie nicht löschen. Neue Klassen werden einfach gefunden und Klassen bei denen sich der Pfad geändert hat sind nach ein oder zwei Refreshes meistens auch wieder da. Das System ist also im Notfall sogar in der Lage sich selbst zu heilen.
Aber in den meisten Fällen kommt ja immer nur neues hinzu.
Also jeden Teil einer Anwendung als eigenes Modul realisieren. Module isoliert von einander halten und so ein unabhängiges Deployment ermöglichen.
Ein wirkliches Problem sind dann nur Oberflächen und Oberflächen-Fragmente. Wären ich es oft über die Addons gelöst habe wäre es bei Anwendungen mit AngularJS und REST-Backend sehr viel einfacher über einzelene Templates zu realisieren, die dann immer bei Bedarf und Vorhandensein nachgeladen werden können.
Aber es ist und bleibt so erst einmal mit das größte Problem.
Wirklich "micro" sind die Services am Ende auch nicht, aber sie sind doch sehr viel kleiner und einfacher zu handhaben als eine riesige monolithische Anwendung, wo alles von einander abhängig ist und eine Änderung an einem Teil theortisch Auswirkungen auf andere Teile haben kann, weil man nicht sicherstellen kann, dass nicht andere Entwickler die geänderten Klassen wo anders auch direkt verwenden. Auch wenn Microservices nicht die Lösung für alles ist und viele Problem
dadurch auch nciht gelöst werden können, sollte man wenigstens das Prinzip der isolierten Module und deren Fähigkeit unabhängig von einander deployed werden zu können aus diesen Konzept mitnehmen. Wenn das Deployment dann nur noch 5 Sekunden an Stelle von 30 Sekunden dauert, hat man oft gefühlt schon viel gewonnen. (Ich hab mit solchen Zeiten gearbeitet und es ist sehr nervig immer solange warten zu müssen nur um eine kleine Änderung in einer Zeile testen zu können!)
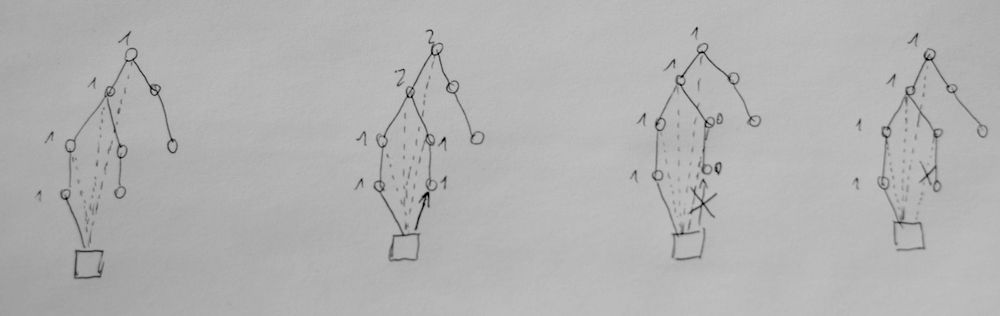
Alternative zu einfachen Child-Parent Strukturen oder Nested-Sets. Der Vorteil würde darin liegen, dass die Inserts im Vergleich zu Nested-Sets bedeutent schneller sind und dass dabei aber nur wenige Vorteile dabei verloren gehen. Trotzdem sind Änderungen noch immer langsamer und das Problem bei Fehlern die Struktur wieder herzustellen bleibt auch in einem gewissen Rahmen. Im Vergleich zu Nested-Sets kann die Struktur aber nicht bei einfachen Inserts zerstört werden, sondern nur wenn Änderungen innerhalb der vorhandenen Struktur vorgenommen werden und dabei eine Transaktion abbricht. Aber auch hier ist das Rekonsturieren sehr viel einfacher, weil die verbliebenen Einträge vor dem Abbruch meistens ausreichen sollten um die Transaction an der abgebrochenen Stelle wieder aufnehmen
zu können.
Das Prinzip basiert auf einer seperaten Tabelle, die alle Relationen der Nodes untereinander (wenn sie Parent oder
Child sind) beinhaltet.
Der Node mit der Id 12 ist also ein direktes Child von dem Node mit der Id 7. Node 7 ist ein Child von Node 3 und Node 3 ist ein Child von Node 1. Node 1 ist das Root-Element.
Direkte Children von Node 3 erhölt man also wenn parentId=3 ist und distance=1. Den direkten Patren von Node 3 mit nodeId=3 und distance=1. Alle Parent mit nodeId=3 und die Sortierung wird über distance vorgenommen.
Inserts sind auch leichter als man erstmal denkt. Wir fügen an Node 12 eine Zusätzliche Node mit der Id 13 an.
Dafür kopieren wir und den Teil der Table für Node 12 und ersetzen die Id von 12 und erhöhen die distance jeweils um 1. Am Ende fügen wir den fehlenden letzten Eintrag einfach hinzu, da dieser keinerlei Berechnung benötigt.
damit haben wir alle Einträge für 13 ohne Rekursion oder dem Ändern anderer Einträge vorgenommen.
Auch das Umhängen eines Nodes innerhalb des Trees ist ähnlich benötigt aber etwas Vorarbeit. Wir hängen z.B. Node 7 an Node 4
Es müssen alle Nodes bei denen Node 7 in den parentId's steht aus gelesen werden und aufsteigend nach distance sortiert werden. Nun werden alle Einträge von Node 7 gelöscht und wie beim Insert neu eingetragen. Danach folgen die direkten Children nach dem selben Muster. Deren Eintrag mit der distance 1 verrät immer noch den Parent und solange der bekannt und vorhanden ist, lassen sich die Tabelleneniträge wie beim Insert schnell wieder aufbauen.
Beim löschen eines Node werden auch alle Children entfernt. Da bedeutet alle Nodes bei denen die parentId gleich der Id des zu entfernden Nodes ist. Dabei spielt die distance keine Role, da solche Einträge nur existieren, wenn der Node ein direktes oder indirektes Child ist.
Dieses Verfahren benötigt natürlich mehr Joins auf DB-Ebene. Aber da sind heutige DBs wohl ausreichend schnell für.
Das einzige wirkliche Problem wäre, dass diese Tabelle sehr schnell sehr sehr groß werden würde. Abhängih von der Tiefe des Baumes kann es ohne Probleme dazu kommen, dass die Tabelle 10x so viele Einträge hat wie die eigentliche
Node-Tabelle.
Blog-entries by search-pattern/Tags:
Möchtest Du AdSense-Werbung erlauben und mir damit helfen die laufenden Kosten des Blogs tragen zu können?
 bezahlt von
bezahlt von  Blog: Blog-entries by search-pattern/Tags:
Blog: Blog-entries by search-pattern/Tags: