Viele erinnern sich noch an Zeiten, wo man direkt auf einem Webserver seinen HTML-Seiten und Scripts geschrieben und getestet hat. HTML ging meistens schon lokal, aber wenn es um PHP oder anderes ging brauchte man einen Server. Dann schwenkte man auf XAMPP um, wo man einen lokalen Apache nutze. Linux brachte den Apache und PHP direkt mit. Aber man hatte oft kein Linux und half sich mit VirtualPC oder VirtualBox, so man entweder eine shared Speicher hatte oder ganz klassisch per FTP oder später SCP/SSH seine Dateien aus der IDE ins Zielsystem bekam. Dann kam Docker und die Welt wurde gut.. über all gut? Nein, dann erstaunlich viele gerade im Agentur-Bereich arbeiten immer noch mit einem Server und einem FTP-Sync. Gut heute oft mit SFTP oder SCP, aber ohne Docker oder lokalen Webserver.
Während ich klassische vServer mit Apache und ohne Reverse-Proxy und Docker für veraltet halte, sind sie noch öfter Realität als Docker-/K8n-Umgebungen. Selbst shared-Hosting für produktive Umgebungen sind noch öfters anzutreffen.
Nach einem Gespräch, wo noch direkt auf dem Server gearbeitet wurde und nicht mal eine lokale IDE einen Sync in Richtung Server vornahm sondern direkt die Datei vom Server aus geöffnet wurde (da kann man fast direkt mit vi auf dem Server arbeiten...), hier eine einfache kostenlose Lösung, wo man wenigstens die Dateien lokal hat und so auch ohne Probleme mit Git arbeiten kann.
Genutzt wird VisualStudio Code (die Intellij-IDEs bringen so einen Sync direkt von Haus aus mit, kosten aber in den meisten Varianten Geld).
Ein Plugin installieren:
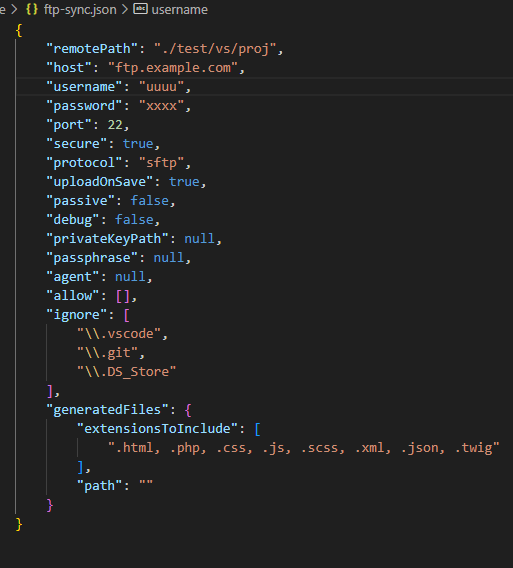
FTP-Config anlegen (wird geöffnet nach dem ersten Sync-Versuch):
Wenn uploadOnSave aktiviert ist am Besten die IDE noch mal neustarten.
Geht auf jeden Fall besser als WinSCP parallel zum Sync laufen zu lassen.
Würde ich so entwickeln wollen? Nein. Besonders wenn mehr als ein Entwickler an einem Projekt arbeiten, geht nichts über Docker. Für Shopware habe ich gute Images oder man nimmt Dockware, was gerade für Entwickler an sich vollkommen reicht.
Am Freitag hat mir mein Kollege 2 Links zu Blogposts geschickt, die sich mit der Frage beschäftigen ob Git-Flow in der heutigen Zeit überhaupt noch funktioniert oder ob Git-Flow veraltet ist. Der 1. Blogpost zeigt erstmal nur Probleme auf und enthält keine Lösungen. Es passiert zu leicht das Release-Branches zu lange leben und dann darin selbst Entwicklung geschieht. Es dauert relativ lange bis eine Änderung durch die verschiedenen Branches im Master ankommen und am Schlimmsten ist noch, dass bei parallelen Entwicklungen ein nicht releaster Branch einen anderen aktuelleren, der einfach schneller war, blockiert.
Ja. Das ist jetzt nicht neu. Über diese Probleme habe ich 2009 schon im dem damaligen ERP-Team diskutiert (mein Gott waren wir damals schon modern...). Die Lösung hier ist einfach dass man harte Feature- und Code-Freezes braucht. Auch darf die Fachabteilung nicht erst im Release-Branch das erste Mal die neuen Features sehen. Ich habe es so erlebt. Dann kamen die neuen Anforderungen, Änderungen der gerade erst implementierten Features. Das soll aber so sein. Wenn das so ist braucht man aber auch noch das. Das ist falsch und muss so funktionieren... Alles Dinge die schon viel früher hätten klar sein müssen und erst dann hätte es zu einem Release-Branch kommen dürfen. Der Stand eines Feature-Branchs muss genau so auf einem System für Test und Abnahmen deploybar sein wie ein Release-Branch. Anders gesagt jeder Stand muss einfach immer präsentierbar sein!
Der 2. Blogpost brachte jetzt auch nicht wirklich neue Erkenntnisse, was am Ende der Author auch selbst schreibt.
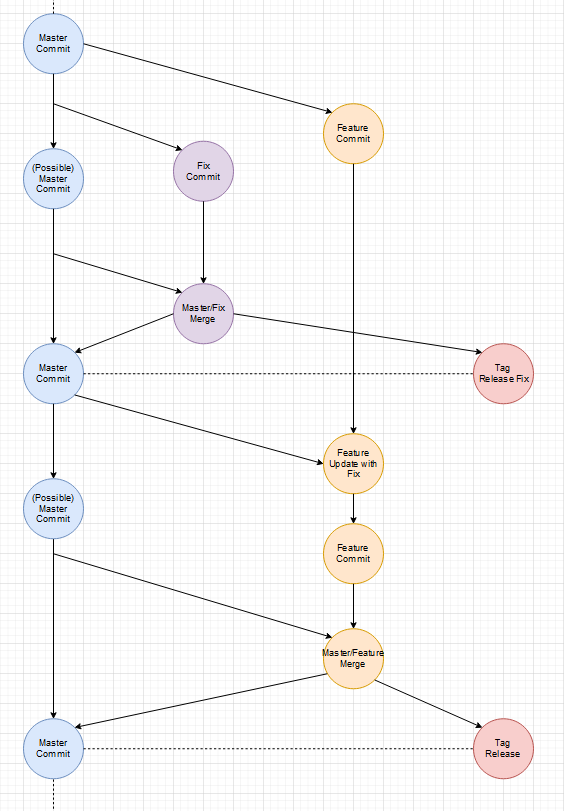
Ich halte die Darstellung von Branches in parallelen Slots oder Lanes, die in dem Sinne ein Rennen um die Aktualität austragen für vollkommen falsch. Es darf auch nicht den develop-Branch oder den einen Release-Branch geben, der auch dann immer deckungsgleich mit dem Stand des Deployments auf einem System ist. In Zeiten von Docker und Reverse-Proxies zusammen mit Wildcard-Subdomains sind feste Systeme sowie so überholt. Jeder Branch kann ein System haben, auf dem Test, Abnahmen und Dokumentation stattfinden kann.
Das gilt auch für Tags. Branches sind variabel und ändern sich immer wieder. Tags sind statisch und damit perfekt für Zwecke, wo man kontrolliert bestimmte Stände deployen möchte. Tags persitieren einen bestimmten State/Zustand des gesamten Git-Repositories. Branches bilden einen State/Zustand aus der Sicht eines bestimmten Entwicklers oder eines bestimmten Features ab.
Deswegen halte ich feste Branches wie mit festen Aufgaben für komplett falsch. Ein Feature = ein Branch und am Ende steht ein Tag, der den gewünschten State/Zustand persitiert.
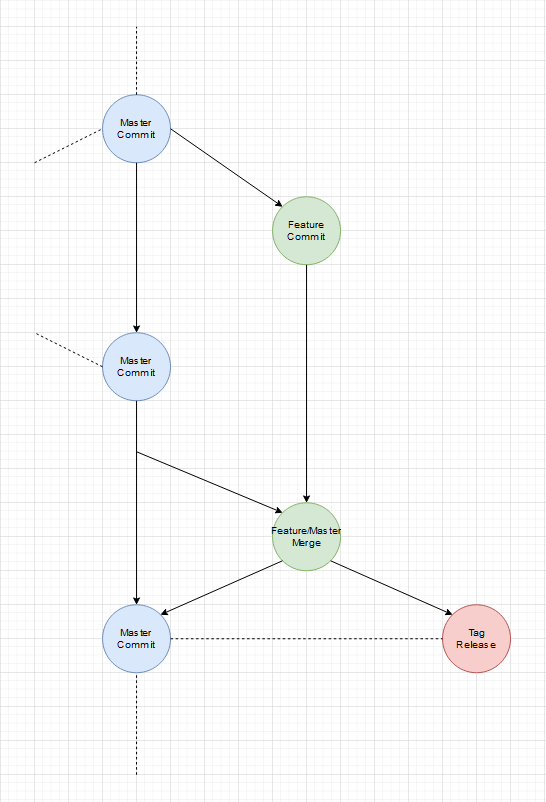
Ein einfacher Feature Branch:
Ja es gibt noch einen Master-Branch, der aber in dem Sinne nur ein 2D Abbild des wilden mehr dimensionallen Feature Raum ist. Wenn wir jeden Feature-Branch als Vektor der auf das einzelne Feature/Tag als Ziel zeigt versteht, ist der Master einfach die Projektion aller Vektoren auf eine Fläche. Diese vereinfachte Projektion hilft Feature-Branches vor dem Release auf den aktuellen Stand (was andere Features und Fixes angeht) zu bringen.
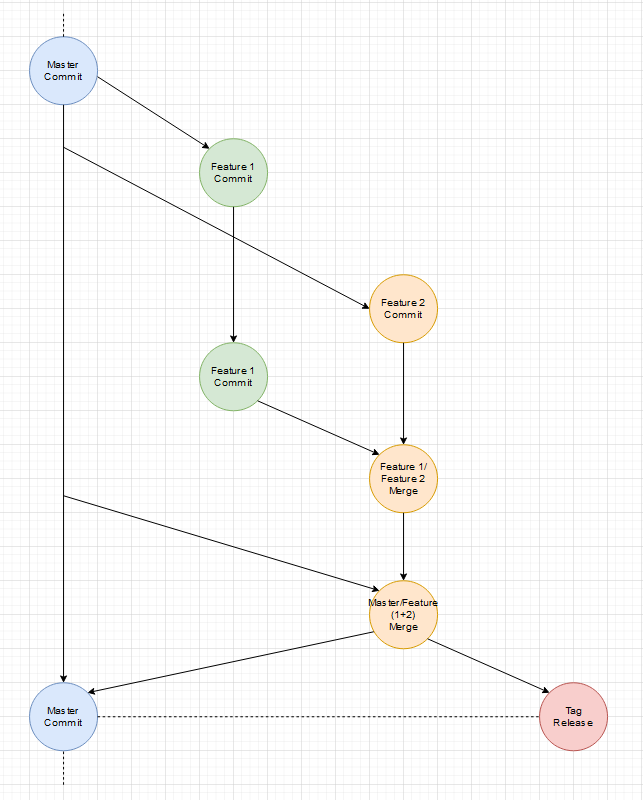
Es gibt auch immer mal Abstimmungsprobleme bei Features, die auf einander aufbauen. Interfaces haben minimale Abweichungen oder ein kleiner Satz in der Dokumentation wurde falsch verstanden. Was also wenn ein Feature doch noch eine kleine Änderung braucht, weil Entwicklungen parallel liefen?
Beides wird gleichzeitig fertig (ein extra Release-Branch wäre möglich):
Das Basis-Feature geht vorher live:
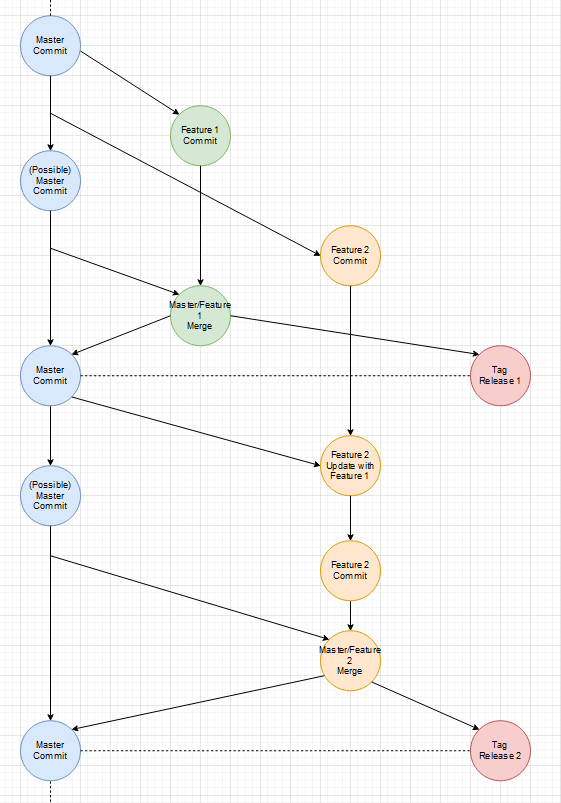
Das bessere und flexiblere Vorgehen
Gibt es einen Unterschied zwischen Fixes und Features? Nein. Beides sind Improvements des aktuellen States/Zustands. Wenn einem in einem Feature-Branch ein allgemeines Problem auffällt, fixt man das Problem und merged den Master mit der neuen Version erneut in den Feature-Branch.
Zwischenzeitlicher Fix:
Es ist an sich kein Unterschied zwischen einem Fix und einen weiteren Feature-Branch, außer dass der Fix-Branch sehr viel kurzlebiger ist und wohl weniger Commits enthält.
Der Master ist immer stable, weil nur Release-Tags darauf abgebildet sind.
Dieses Herangehen macht es sehr einfach jeden State/Zustand auf System abzubilden. Jeder Branch ist unter seinem Namen zu finden und Tags werden nach Typ auf Systeme gemappt.
Tag auf System: - release-XXX auf das produktive System
- staging auf das Staging-System (1:1 Namenabbildung)
- demo1-n auch 1:1 per Namen abbilden
Bei staging muss man den Tag löschen und neu anlegen, so kann jeder Zustand auf dem Staging-System deployt werden oder besser gesagt, wird ein Deployment durchgeführt das dann unter der Staging-Domain erreichbar ist. Hier gibt es eine tolle Anleitung wie man solche Systeme mit Traefik oder Kubernetes ganz einfach bauen kann. Ich werde das aber vielleicht auch noch mal genauer beschreiben, wie ich es für gut halte.
Denn Branches halte ich persönlich es nicht für wert wo anders als lokal in einem Docker-Container zu laufen. Da kann ich um es der Fachabteilung lieber schnell einen Tag erstellen und diesen nach dem Input der Abteilung auch wieder unter selben Namen neu anlegen oder unter einen neuen wenn zwei mögliche Umsetzungen verglichen werden sollen (macht das mal mit Git-Flow!).
Edit: Ich habe die per Hand gezeichneten Diagramme durch vollständigere Diagramme, die per Software erstellt wurden, ausgetauscht.
Um die Traefik Labels einzubauen hat man ja die Wahl diese im Image zu haben oder im Container. Während man die dem Container beim Starten geben kann, muss man die für das Image beim Build-Process schon haben. Ich benutze beides und muss sagen, dass ich an sich dafür bin die dem Container zu geben. Aber falls man sich mal fragt wie man dynamische Labels dem Image geben kann... ARG ist das Geheimnis.
Wenn ich nun eine dynamische Subdomain haben will:
FROM httpd:2.4
ARG subdomain
COPY ./index.html /usr/local/apache2/htdocs/index.html
LABEL traefik.enable=true traefik.frontend.rule=Host:$subdomain.example.com
Hier kann man dann auch auf ENV-Variablen zurück greifen und die weiter durch reichen. Was sehr praktisch ist, wenn man sich in einem Gitlab-CI Job befindet.
Nachdem ich meine wichtigsten Projekte in Docker-Container verfrachtet hatte und diese mit Traefik (1.7) als Reserve-Proxy seit Anfang des Jahres stabil laufen, war die Frage, was ich mit den ganzen anderen Domains mache, die nicht mehr oder noch nicht produktiv benutzt werden.
Ich hatte die Idee einen kleinen Docker-Container laufen zu lassen, auf den alle geparkten Domains zeigen und der nur eine kleine Info-Seite ausliefert. Weil das Projekt so schön übersichtlich ist und ich gerne schnell und einfach neue Domains hinzufügen will, ohne dann immer Container selbst stoppen und starten zu müssen, habe ich mich dazu entschieden hier mit Gitlab-CI ein automatisches Deployment zubauen. Mein Plan war es ein Dockerfile zu haben, das mir das Image baut und bei dem per Label auch die Domains schon angegeben sind, die der Container bedienen soll. Wenn ich einen neuen Tag setze soll dieser das passende Image bauen und auf meinem Server deployen. Ich brauche dann also nur noch eine Datei anpassen und der Rest läuft automatisch.
Dafür habe ich mir dann extra einen Gitlab-Account angelegt. Man hat da alles was man braucht und 2000 Minuten auf Shared-Runnern. Mehr als genug für meine Zwecke.
Ich habe also eine index.html und ein sehr einfaches Dockerfile (docker/Dockerfile):
FROM httpd:2.4
COPY ./index.html /usr/local/apache2/htdocs/index.html
LABEL traefik.enable=true traefik.frontend.rule=Host:darknovels.de,www.darknovels.de
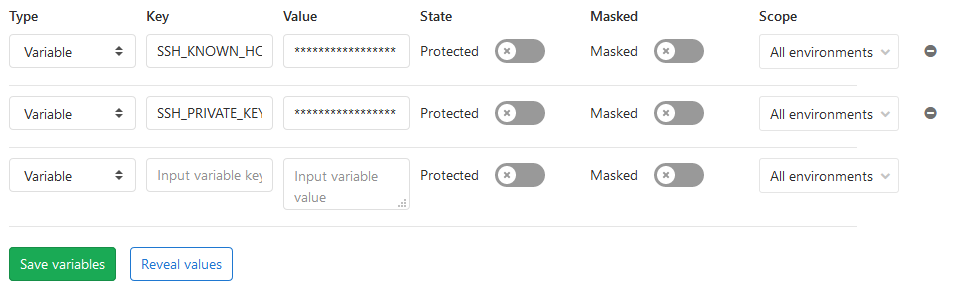
Das wird dann also in einen Job gebaut und in einem nach gelagerten auf dem Server deployed. Dafür braucht man einmal einen User auf dem Server und 2 Variablen in Gitlab für den Runner.
Dann erzeugt man sich für den User einen Key (ohne Passphrase):
su dockerupload
ssh-keygen -t rsa
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
exit
Vielleicht muss man da noch die /etc/ssh/sshd_config editieren, damit die authorized_keys-Datei verwendet wird.
Den Private-Key einmal kopieren und in SSH_PRIVATE_KEY unter Settings - CI /DI - Variables speichern. Damit wir uns sicher vor Angriffen verbinden können müssen wir noch den Server zu den bekannten Hosts hinzufügen. Den Inhalt von known_hosts bekommt man durch:
ssh-keyscan myserver.com
Einfach den gesamten Output kopieren und in den Gitlab Variablen unter SSH_KNOWN_HOSTS speichern. Nun hat man alles was man braucht.
Seit heute laufen die meisten meiner Homepages als Docker-Container mit Traefik als Reserve-Proxy. Es war teilweise ein sehr harter Kampf mit vielen kleinen Fehlern. Wenn man sauber von vorne anfängt sollten weniger Fehler auftreten.
Was man beachten sollte:
- Images müssen Port 80 exposen
- HTTPS-Umleitungen aus htaccess-Dateien entfernen (Traefik kümmert sich darum)
- Datenbanken über Adminer oder PHPMyAdmin initialisieren und nicht über init-Scripte
- Man braucht ein eigenes Netzwerk in Docker wie "web"
- traefik.frontend.rule und traefik.enable reichen als Tags
- man macht vieles ungesichert während des Setups, dass muss man später alles wieder absichern (die Traefik-UI/API!)
- Immer Versionen für die Images angeben und nie LATEST (sonst hat man plötzlich neue Probleme)
Ich habe noch Traefik 1.7 laufen, aber das funktioniert so weit sehr gut und es gibt viele Hilfen. Für 2.0 gibt noch nicht so viele Hilfen und Beispiele. Für jeden Container habe ich auch ein eigenes Dockerfile, damit man da kleine Modifikationen an den Images machen (auch wenn es nur mal zum Testen ist).
Emails laufen nun alle über poste.io der unabhängig von Traefik läuft und einen eigenen Port für die Web-UI nutzt. Das Setup ging schneller und läuft schon seit einigen Wochen extrem stabil und filtert Spam sehr viel besser als meine vorherige selbst gebaute Lösung.
Es wird mal Zeit sich der Zukunft zu zuwenden und nicht mehr in der Vergangenheit zu leben. Deswegen werde ich endlich mal alle meine Seiten und Projekte in Docker-Container verfrachten und mit Traefik meinen Server neu strukturieren. Deswegen kann es im Dezember bei meinem Blog und MP4toGIF.com zu längeren Downzeiten im Dezember kommen. Ich überlege auch einen günstigen zweiten Server nur für Emails zu nehmen.
Das ganze sollte mir dann auch die Möglichkeiten geben spontan mal andere Dienste zu deployen. Im Kopf habe ich da so:
* Passbolt (als Ersatz für KeePasssXC)
* nextCloud um von OneDrive weg zu kommen
* und vielleicht Satis um meine PHP-Libs zu bündeln
Ich hoffe mal, dass alles ganz einfach und super funktioniert :-)
Blog-entries by search-pattern/Tags:
Möchtest Du AdSense-Werbung erlauben und mir damit helfen die laufenden Kosten des Blogs tragen zu können?
 bezahlt von
bezahlt von  Blog: Blog-entries by search-pattern/Tags:
Blog: Blog-entries by search-pattern/Tags: