Ich habe letzte Woche mein erstes Wordpress-Theme fertig gestellt. Mit integration der großen Social-Networks und allem.. ging sehr viel einfacher als gedacht. Wer also eine CMS- oder Blog-Lösung auf Wordpress-Basis braucht.. ich nehme jetzt auch Aufträge in die Richtung gerne entgegen.
Der dritte Teil und schon bei den Animes angekommen... aber in dem Bereich findet man viele sehr gute Filme mit guter Story und interessanten Charakteren. Außerdem scheinen Japaner eine Vorliebe für Soziale-Netzwerke und VR zu haben, die so riesig sind, dass sie das gesamte Leben der Menschen beeinflussen. Also das gesamte Internet in einem sozialen Netzwerk.
Summer Games
Das Interessanteste an Summer Wars ist nicht wirklich die VR-Welt oder die böse KI, die sowohl das Internet als auch die reale Welt beherrschen möchte, sondern das Spiel zwischen Tradition und Moderne.
Auf der einen Seite eine alte Samurai-Familie mit einem Oberhaupt (die Großmutter) in der Familienwerte über alles stehen und Probleme gemeinsam angegangen werden und auf der anderen Seite die VR-Welt die rein technisch bedingt ist und jeder sich hinter einem Avatar versteckt und am Ende vollkommen anonym ist.
Im Laufe der Handlung zeigt sich aber immer mehr, dass die zwei Welten nicht so unterschiedlich sind, wie man dachte und die Familienmitglieder, die einem zuerst traditionell bis auch leicht die Moderne ablehnend vorkommen, genau so in der modernen Welt und die alten Werte zur Hilfe nehmen, um gegen moderne Bedrohungen anzukommen. Oder auch mal einen kurz einen Super-Computer liefern können, wenn er benötigt wird.
Gerade die Großmutter und ihr Netzwerk aus Kontakten zeigt, dass persönliche Kontakte sehr viel effektiver ist und schneller reagiert als eine die anonyme Masse des Internets, die sich erst finden und strukturieren müssen.
Zwar endet der Kampf gegen die KI in einem klassischen "Hack the Planet" Finale, aber deren Sieg basiert nicht auf Hightech sondern auf einem alten japanischen Kartenspiel... und einem Mathe-Genie.
Ich habe gestern Abend mal eine Animation so wohl als animiertes GIF als auch WebM ausgegeben.
Der Unterschied in der Dateigröße ist schon enorm.
Wenn man also überlegt, ob man auf der eigenen Seite Animationen als GIF oder WebM (selbst der neue Edge wird es unterstützen) nimmt, ist WebM wohl die beste Wahl. Damit es sich wie ein GIF verhält muss man es so einbinden:
In den letzten Wochen und Monaten hat Microsoft viele Menschen verwundert. Der SQL-Server soll für Linux heraus kommen. Die Azure-Services sollen besser in Java-Umgebungen integriert werden und dafür wird Microsoft Mitglied der Eclipse-Foundation.
Microsoft veröffentlicht ein System für Switches auf Basis von Linux.
Das alles klingt nicht nach dem Microsoft wie man es noch vor ein paar Jahren kannte, das Opensource als Krebsgeschwür betitelte und als Reaktion auf Standards immer eine eigene Idee heraus brachte und sich beim IE nie um Standards groß kümmerte.
Dieses Microsoft existiert nicht mehr und kann auch nicht mehr existieren, denn die Zeiten haben sich geändert. Früher war Microsoft gleich bedeutent mit Windows und Windows war der PC. Heute sieht alles ganz anders aus. Apple kam zurück. Smartphones und Tablet verdrängten in vielen Bereichen den PC. Gerade ältere Menschen greifen lieber zum Tablet als ein Notebook zu holen oder sich vor den PC zu setzen. Vieles was man früher als Programm auf dem Dektop hatte ist heute ins Internet und in die Cloud gewandert. Opensource ist nicht nur bei Idealisten angekommen auch Regierungen und Firmen setzen auf Opensource und fördern dort ganz gezielt Projekte.
Anders gesagt dreht sich alles nur noch um Services und Anwendungen/Apps. Wo diese laufen ist nicht mehr wichtig oder anders gesagt, wenn sie nicht überall laufen sind sie keine Alternative für die man sich entscheiden kann. Eine Webapp die nur auf dem IE schließt sofort fast alle Tablets und Smartphones aus und damit die meisten Nutzer. Auch wollen sich Entwickler nicht mehr von einer Firma abhängig machen. Wenn meine Anwendung in einer Cloud-Umgebung nicht richtig skaliert oder zu teuer wird, wechsel ich. Denau so legt man sich nicht auf ein Betriebssystem fest. Mit Java, PHP oder anderen Sprachen muss ich mir keine Gedanken machen, auf welchen OS ich mich gerade befinde. Egal ob auf meiner lokalen Windows-Maschine, die ich zum Entwickeln habe, meinem Linux Testsystem, dass irgendwie in einer VM läuft oder am Ende per Docker in einer Cloud-Umgebung. Und wenn der Webdesigner auf seinem Mac die Oberfläche für mich optimiert, soll er sich nur den Branch aus checken und es soll bei ihm genau so funktionieren, wie bei mir.
Es gibt bestimmte Punkte nach dem sich entscheidet welches OS ich benutze:
* die Firma oder das Team gibt es vor
* Es ist die technisch beste Lösung
* ich kenne mich einfach damit besser aus
* ich mag es am liebsten
Am Ende ist es aber egal, weil ein Betriebssystem allein nichts aussagt. Es geht immer um die Programme und Anwendungen, die darauf laufen.
Momentan gibt es nur ein Programm wegen dem ich momentan erst einmal Windows vorziehen würde: SourceTree. Sollte es mal für Linux herauskommen oder die .Net Unterstützung unter Linux es zum Laufen bekommen ist das OS wirklich vollkommen egal. Für alte Anwendungen die ein bestimmtes OS voraus setzen gibt es ja VMs und die VM Umgebungen gibt es auch für alle Betriebssysteme.
Ich verwendete Ubuntu auf der Arbeit, Windows auf meinem Desktop und Mint auf meinen Notebook. Da ich aber überall Eclipse, Apache, MySQL, Notepad++, WinSCP und Firefox benutze, ist der Wechsel fließend und es ist mir am Ende egal, mit was ich gerade arbeite, weil ich den Unterschied kaum bemerke (außer von der Optik der Fenster).
Ich behaupte auch, dass man den meisten normalen Benutzern ohne Probleme ein Linux installieren könnte und es würde keinen Unterschied machen. Denn die Konfiguration eines Windows-Systems überfordert die genauso wie, wie die eines Linux-Systems. Die Fenster sehen etwas anders aus, aber.. Firefox und Chrome laufen dort genauso und OpenOffice oder LibreOffice sehen dort nicht anders aus, als auf Windows. MS Word und Excel haben viel Boden verloren, viele arbeiten privat nicht mehr damit und ich ich wundere mich doch immer wieder, wenn mir ein "Voll-Noob" was PCs betrifft einen Text schickt und es kommt eine odt-Datei
an.
Email ist sowie so komplett ins Web abgewandert und privat hat kaum noch jemand Outlook installiert.. wenn überhaupt noch mal Thunderbird. Aber an sich spielt sich Email nur noch übers Web und in Smartphone Apps ab.
Windows ist auch einfach nicht mehr der Markt wie früher. Windows 10 hat kaum jemand gekauft. Windows bringt nur noch im Enterprise-Bereich Geld. Nach XP (und dem kompletten Wechsel auf den NT-Kernel) kann es alles was der normale Benutzer braucht und es gibt keinen Grund eine neue Version zu holen. Neue Programm-Versionen werden natürlich immer verwendet, aber neue Windows-Versionen spielen für die meisten
keine Rolle.
Also ist Microsofts Schritt sehr gut zu verstehen. Windows ist nicht mehr die Welt und man will weiterhin seine Programme und Services verkaufen. Wo Opensource einen helfen kann, nutzt man dies und damit man überall vertreten ist, muss man sich an Standards halten. Wenn das nicht allein schafft, muss man eben auch mal Mozilla um Rat fragen.
Windows NT war schon immer ein tolles Betriebssystem, aber nicht so toll, das sich jemand darauf fest legen würde und damit Windows Server nicht wie Netware endet, muss sich Windows Seite an Seite mit den anderen Betriebssystemen einfinden. Denn Integration kann mehr Pluspunkte bringen, als ein oder zwei Feature mehr im Vergleich.
"Ich habe mit Oracle-DB gearbeitet und musste dort Konstrukte drin bauen, die einen 2 Tage Arbeitszeit und tausende Nerven gekostet haben und man 4 mal pro Stunde an sich selbst gezweifelt hat. Manchmal war einem am Ende nicht mal ganz klar, warum es nun wirklich doch funktionierte.
Jetzt arbeite ich mit MySQL/MariaDB... und wünsche mir oft die Oracle-DB zurück, weil ich damit diese Konstrukte überhaupt bauen konnte!"
Mein Kommentar dazu, wenn mal wieder über Oracle und deren doofe DB geweint wird.
Nach Hackers jetzt ein Film den man wirklich ernster nehmen kann und der auch von der Story und den schauspielerischen Leistungen wirklich mehr zu bieten hat. Der Soundtrack ist auch super. Wer mal das Buch Ready Player One wird den Film schon halb kennen ohne ihn gesehen zu haben und auch Family Guy und American Dad haben den Film schon gewürdigt. Es geht natürlich um..
WarGames
Der Film spielt Anfang der 80er Jahre im Kaltenkrieg und die ersten Intel 8080 Rechner waren zu kaufen. Hier besonders der IMSAI 8080 mit Disketten (teuer zu der Zeit),
Akkustikkoppler und Sprachsynthesizer. Vergleichbar mit einem Altair 8800, aber im Film richtig mit Monitor und Tastatur, weil mit den Schaltern den Computer zu programmieren wohl nicht cool genug gewesen wäre.. keine Ahnung wie ein Schüler sich das alles hätte leisten können.
Der Film bedingt mit dem Problem, dass Menschen Skrupel haben den Feind mit Atombomben anzugreifen, auch wenn es nur eine Reaktion auf einen Angriff seiner Seits ist. Also die Menschen lieber selbst sterben würden als zum Mörder zu werden. Das gefällt dem Militär natürlich nicht und man will die menschliche Komponente des Atomkriegs entfernen und alles rein Computer gesteuert kontrollieren, damit im Ernstfall auch wirklich der Angriff ausgeführt wird.
Hier merkt man schon, dass da etwas mehr Tiefe drin ist als bei Hackers.
Aber eines ist gleich. Der junge Hacker der seine Hackerfähigkeiten auch in der Schule einsetzt. Wobei WarGames hier immer realistischer und zurück haltender bleibt. Die erste Szene mit Matthew Broderick beleibt einem im Gedächtnis. Man sieht ihn wie er Galaga spielt und zusammen mit der Musik wirkt die Szene einfach sehr gut.
Die ganze wirkliche Story entspannt sich darum, dass David gerne ein neues Computerspiel spielen würde, das noch nicht veröffentlicht wurde und sich denkt, es müsse ja irgendwo schon auf einem Server liegen und seinem Versuch diesen Server zu finden und ihn zu hacken. Leider löst er dabei eine Simulation für einen russischen Atomangriff aus. Er erkennt dass die Simulation in Hintergrund weiter läuft und die KI, die das System steuert, nicht zwischen Simulation/Spiel und Realität unterscheiden kann. Keiner will ihn glauben und bei dem Versuch den Programmierer des System zu finden, um seine These zu untermauern, läuft ihnen die Zeit davon. Der Film ist wirklich spannend und bis zum Ende sehr fesselnd, weil der Zeitdruck und die ablaufende Zeit extrem gut drüber gebracht wird.
In dem Film lernt man auch die DEFCON-Stufen zu lesen und weiß das DEFCON 5 die harmlose Stufe ist und nicht DEFCON 0.
Und die Moral von der Geschicht: The only winning move is not to play... jeden falls, wenn man in einem Atomkrieg pokert. Denn da kann gewinnt am Ende niemand.
Am Anfang sieht man einen jungen Michael Madsen als den Soldaten der die Atomraketen nicht starten will.
Die kleine Liebesgeschichte hält sich zum Glück etwas mehr im Hintergrund und ist weniger plump als in Hackers. Wirkt dadurch auf echter und benötigt auch keine Nacktszenen oder ähnliches.
Jeder der vorhat "Ready Player One" zu lesen, sollte sich den Film vorher mindestens einmal ansehen!
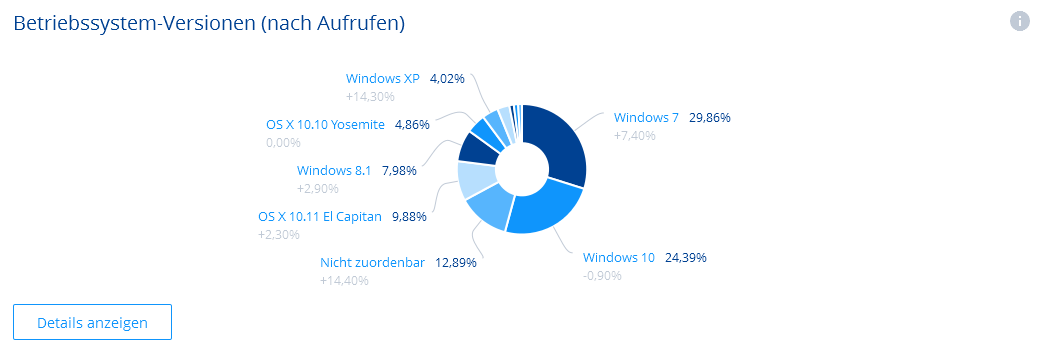
Als kleiner Zwischenstand mit meinem Experiment mit den Watermarks bei MP4toGIF.com ist momentan zu sagen, dass die Zahlen einiger Massen gleich geblieben sind. Ich merke zwar, dass bei den AdSense Einnahmen immer mal wieder MP4toGIF.com mehr auftaucht, aber den großen Sprung gab es auch nicht. Die Besucherzahlen sind auch konstant. Also geschadet hat es bis jetzt nicht. Also werde ich mal überlegen, wie ich die Seite nochmal verbessern könnte, mit mehr Filtern oder noch anderen Zusatzfunktionen. Wer Ideen hat, kann sie mir gerne in den Kommentaren oder per Email mitteilen.
Aber ich finde schön, dass meine Benutzer relativ modern sind und der Windows 10 Anteil schon so hoch ist, denn das bedeutet, dass die auch mit den Bordmitteln.. also Edge.. meine Seite verwenden könnten. Wobei von der Performance Vivaldi und Chrome noch immer sehr weit vorne liegen, weil die beiden einen nativen Webp-Support mitbringen.
Das man in einer PHP-Seite mal in eine Exception läuft ist ja nicht schlimm, nervig ist nur, wenn man merkt, dass diese Exception wiederum aus einen catch-Block stammt und man erst einmal Debuggen muss, um an die original Exception zukommen und den wirklichen Fehler zu sehen.
try{
$a = 1* array(2,3);
}
catch(Exception $e){
throw new Exception("something went wrong");
}
Man sollte immer, wenn es mögich ist, die original Exception mit an die eigene Exception ran hängen.
try{
$a = 1* array(2,3);
}
catch(Exception $e){
throw new Exception("something went wrong", 0, $e);
}
Bevor es dann wirklich mal um die Installation von PDT in Eclipse geht, wollen wir uns erst einmal eine MySQL Datenbank einrichten, damit wir auch richtige kleine Anwendungen schreiben können und nur ganz selten kommt man da ohne Datenbank aus. Auch wenn NoSQL Datenbanken wie Neo4J wirklich toll und momentan sehr in sind, bleiben wir bei einem klassischen RDBMS. Weil MySQL gerade im Web sehr verbreitet ist und sich einfach lokal einrichten lässt, bleiben wir auch bei MySQL.
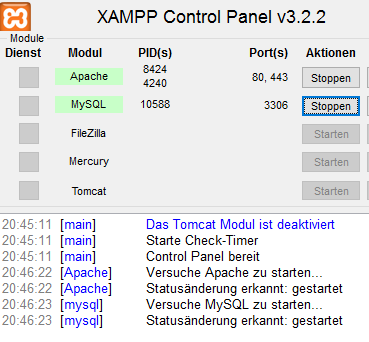
Wer ein Linux benutzt, kann MySQL immer ganz einfach über den Paket-Mananger installieren. Für Windows kann man schnell zu XAMPP greifen. XAMPP enthält alles vom Apache, PHP7 und MySQL bzw MariaDB.
XAMPP funktioniert am Besten wenn man es direkt unter C:\ installiert.
Zum Verwalten der Server-Anwendungen von XAMPP gibt es das XAMPP Control Panel. Hier müssen nur der Apache und der MySQL Server gestartet
werden.
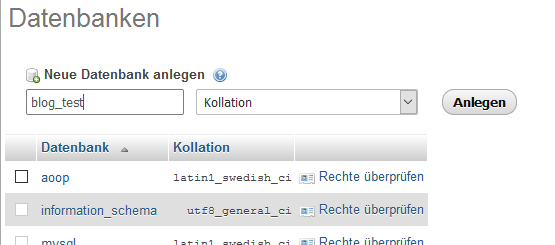
Damit auf die Datenbank zugegriffen werden kann bringt XAMPP phpMyAdmin mit. phpMyAdmin ist eine Datenbankverwaltung die in PHP geschrieben ist und auch von den meisten Hostern angeboten wird.. wenn nicht sogar von allen. Man kann direkt über die URL http://localhost/phpmyadmin darauf zugreifen.
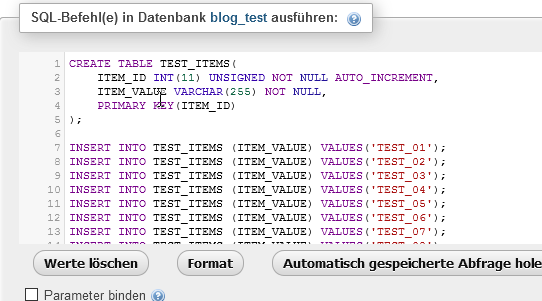
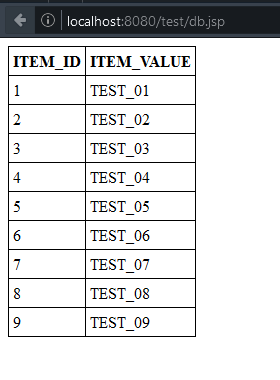
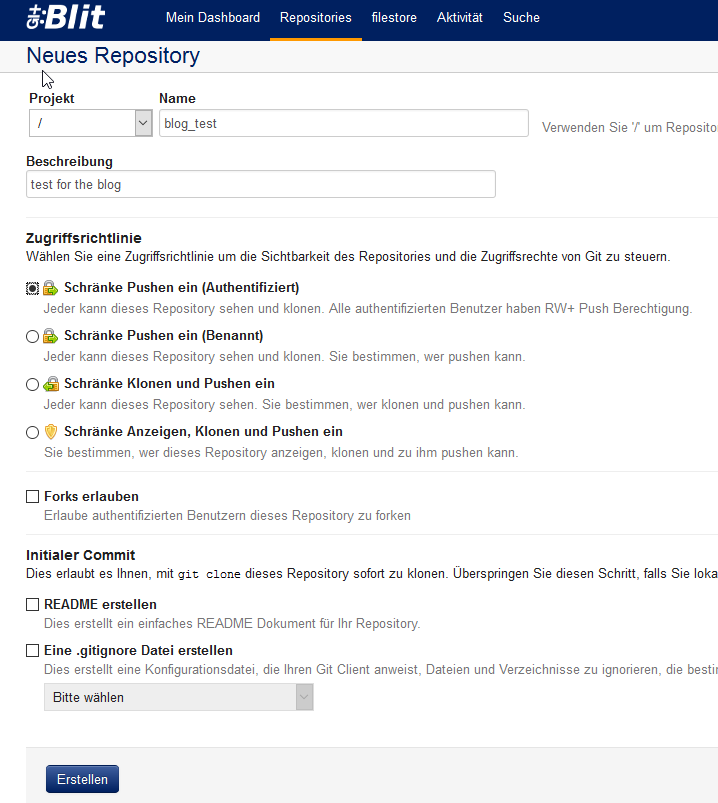
Zuerst erstellen wir eine Datenbank mit dem Namen blog_test.
Damit wir ein paar Daten haben, legen wir uns eine Tabelle mit ein paar wenigen Daten an. Hier ist das SQL-Script dafür:
CREATE TABLE TEST_ITEMS(
ITEM_ID INT(11) UNSIGNED NOT NULL AUTO_INCREMENT,
ITEM_VALUE VARCHAR(255) NOT NULL,
PRIMARY KEY(ITEM_ID)
);
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_01');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_02');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_03');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_04');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_05');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_06');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_07');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_08');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_09');
Die IDs werden automatisch hochgezählt und müssen deswegen nicht extra angegeben werden.
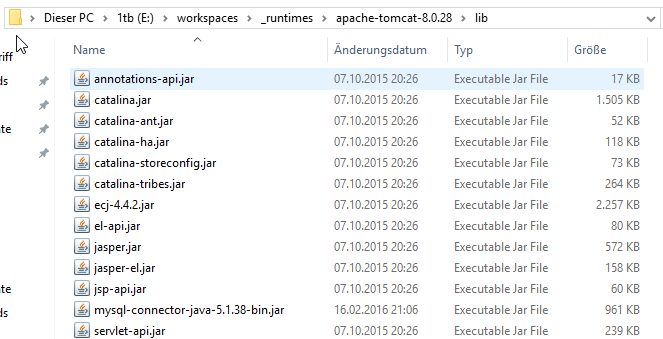
Nun gehen wir wieder in Eclipse zurück und erstellen uns eine kleine JSP mit einer Datenbankabfrage. Und hier wird es etwas komplizierter mit den verschiedenen ClassLoader des Tomcats und den verschiedenen Config-Dateien. Ich hab die einfachste aber nicht beste Variante gewählt. Die JAR-Datei mit dem JDBC-Treiber kommt direkt in das lib-Verzeichnis des Tomcat und wir passen die zentrale context.xml Datei, die uns von Eclipse zur Verfügung gestellt wird.
Die aktuelle JAR mit dem MySQL-Treiber findet man auf dev.mysql.com.
In die Context-Datei definierten wir die DataSource als Resource.
Nun können wir über JNDI uns diese DataSource in eine JSP holen. Wir erstellen eine ganz einfach Abfrage. Das Ergebnis liefert uns ein Statement in Form eines ResultSets. Ich benutzt hier die Methode über den Index die Ergebnisse zu bekommen, z.B. getString(1) wobei aber auch getString("ITEM_ID") funktioniert und für den zielgerichteten Einsatz sehr viel besser ist, weil man so das SQL-Statement ändern kann und auch die Reihenfolge der Columns ändern, ohne dabei auf den Java-Code achten zu müssen. Hier wird aber nicht zielgerichtet ein Wert ausgelesen und z.B. in ein anderes Object geschrieben sondern einfach alles ausgegeben. Deswegen auch nur getString() und keine anderen Methoden, die einen passenden Datentyp zurück liefern und ein eigenes Casten der Werte unnötig machen.
Der Vorteil die Connection über eine DataSource zu bekommen und nicht jedes mal selbst zu initiieren ist, dass die DataSource ein Pooling der Connections vornimmt und Datenbankverbindungen zur Wiederverwendung offen hält, um den Overhead für Verbindungsaufbauten zu verringern.
SQL-Abfragen direkt in einer JSP-Seite zu ist aber eine schlechte und man sollte so etwas in DAO-Klassen auslagern und in der JSP nur die Ansicht mit schon fertigen Objekten erstellen, die dann vom DAO geliefert werden.
Außerdem werden immer mehr JPA verwendet, wo die SQL-Statements automatisch erzeugt werden. Handgeschriebenes SQL ist in komplexen Fällen meistens schneller und besser, aber ORM-Frameworks erleichtern einen die Arbeit schon sehr und man sollte sich JPA auf jeden Fall einmal
ansehen, bevor man noch direkt mit JDBC und SQL arbeitet.
Im nächsten Teil geht es dann wirklich mit PHP weiter.
Heute wurde endlich nach langer Zeit das Nexus 7 reaktiviert. Die Geschichte wie wir zu diesem Tablet kamen, ist interessant und was ich dabei über Benutzer Mittleren Alters gelernt habe ist beunruhigend. Es ist auch eine Geschichte über Rohstoffverschwendung und eine absolute Wegwerfgesellschaft, in der Wegwerfen und Neukaufen schon ein Reflex sind und erst einmal Gucken und Nachdenken sehr selten geworden sind.
Vor fast einem Jahr war ich in einem Elektronikmarkt, um dem Amiibo-Sammeln nach zu gehen. Wir holten gerade eine Vorbestellung ab, als ein sehr aufgebrachter Herr im Mittleren Alter den Laden betrat und mit einem Tablet in der Luft herum fuchtelte. Er meinte etwas davon, dass das Tablet nicht mehr angehen würde und ob die das reparieren würden. Das Tablet war aber schon über ein Jahr alt und die hätten es natürlich nicht mehr kostenlos repariert. So wie er aufgebracht und laut herein kam, war im das wohl klar und er wollte wohl Eindruck machen auf die Angestellten, dass die sich eingeschüchtert dazu bereit erklären würden es doch zu reparieren. Freundlich sein hilft bei so etwas immer mehr, als "den Dicken zu markieren".
Er stürzte raus und warf demonstrativ das Tablet in einen Mülleimer.
Ich versteh Leute nicht, die einfach etwas wegwerfen ohne vorher jemanden zu fragen der sich damit auskennt. Mit "auskennen" meine ich nicht gewisse große Elektronik-Märkte, die jeden aus der Werbung bekannt sind. Durch so einen Markt haben wir aber einen 42 Zoll TV bekommen, der ein Totalschaden sein sollte, laut diesem Markt und man mindestens die Platine austauschen müsse damit er wieder angehen würde. Ein Firmware-Download und 10 Minuten später lief er wieder und leistet seit über 2 Jahren gute Dienste.
Also ein Griff in den Mülleimer und Tablet mit genommen. Ich dachte damals noch an einen defekten Akku. Aber da das Tablett gar nicht mehr laden wollte und auch mit Netzteil nicht mehr an ging machte ich mich auf die Suche nach Ersatzteilen. Eine neue USB-Buchse die laut Forenbeiträgen wohl oft das Problem sei kostete 4 Euro. Kam aus China, aber ich hatte ja Zeit.
Ich baute die Buchse ein und nichts änderte sich. So landete das Tablet erst einmal in der Schublade. Heute versuchte ich es nochmal und es tat sich nicht. Ich wollte gerade wieder die Rückseite drauf machen und es wieder weglegen als der Bildschirm kurz flackerte. Da war mein Ehrgeiz wieder geweckt. Mit etwas Feingefühl und einem USB-Ladegerät war 5 Minuten später der Lade-Symbol zu sehen und 2 Stunden später wagte ich es das Tablet dann richtig einzuschalten.
PIN? Nein..einfach entsperren. Das Tablet war in dem Zustand, wie als es sich ausgeschaltet hatte. Apps liefen, Email-Konten und alles war eingeloggt. Ich hatte keine WLAN-Verbindung sonst hätte das Tablet sich gleich die neusten Emails geladen. Wie man schnell sah waren fast alles geschäftliche Emails. Also erst einmal den Akku weiter geladen, damit man das Tablet zurück setzen kann.
Der Zustand war jetzt schon sehr bedenklich. Email-Konten und Facebook und ähnliches wäre sicher auch noch eingeloggt gewesen. Für ein Tablet, dass man nur zu hause verwendet, ist ein PIN nicht so wichtig, aber wenn man es in der Öffentlichkeit weg wirft, sollte man vorher daran gedacht haben.
Nur weil man als normaler Benutzer ein Gerät nicht mehr starten kann, bedeutet es nicht, dass jemand der sich damit auskennt, das Gerät nicht reparieren kann!
Ein durchgeschnittenes Stromkabel erkennen die meisten heute schon als nur kleines Problem, was jemand für sie reparieren kann. Eine verbogene USB-Buchse kann komplexer sein.. muss es aber nicht.
Dann würde es noch schlimmer, als ich das Tablet an den PC anschloss und in einem Order, ganz oben, mich eine Datei mit dem Namen "001_Passwörter.html". Kurz: Es stand alles drin.. Email-Konten, soziale Netzwerke und Online-Banking.
Es gibt tolle Programme wie KeePass mit denen man Passwörter sicher speichern kann. Aber man speichert niemals alle Passwörter zentral und unverschlüsselt in einer Datei.
Wer das macht handelt einfach nur fahrlässig und dem fehlt jedes Gefühl für Sicherheit und Verantwortung.
Ich hab schon Nacktfotos auf Notebook gesehen, wo ich nur ein Programm einrichten sollte und welche wo das Benutzer-Passwort unbekannt was und schon halb als Totalschaden abgestempelt waren und die Daten als verloren galten. Eine Schraube lösen, Festplatte raus ziehen und an den USB-SATA Adapter hängen. Schon waren die Daten wieder da.
Einmal war es wie es sein sollte. Ein Lehrer hatte einen neuen PC gekauft und kam zu mir damit die Festplatte seines alten PCs so formiert wird, dass er den alten PC abgeben könne und niemand die Daten wieder herstellen kann. Es gibt viele Programme, die eine Festplatte mehrmals überschreiben können. Mit so einem Programm war das in zwei Stunden erledigt.
Aber die meisten Benutzer haben nicht so ein Gefühl dafür oder denken einfach nicht daran, dass man Daten sicher löschen sollte.
Wichtig ist sich immer vor Augen zu führen und es auch seinen Eltern und anderen Leuten, sollten sie in so eine Gelegenheit kommen, klar zu machen, dass man fast alles reparieren kann und wenn man doch etwas weg wirft (es jemanden zum reparieren zu geben spart Geld und schon die Umwelt), die Daten sicher löschen zu lassen. Wenn man niemanden findet, hilft auch ein guter Hammer!
Jeder der eine für Benutzer kostenlose Website oder Webapp betreibt ist natürlich immer bestrebt, wenigstens die Betriebskosten irgendwie wieder rein zu bekommen. Dann würde man zwar nichts verdienen, aber auch keinen Verlust machen.
Der beste Weg etwas Geld einzunehmen ist es Werbung zu schalten. Payed Erweiterungen und Angebote sind in der Integration wieder sehr viel Aufwendiger und dann sind meistens auch nicht nur paar Euro pro Monat wieder einzunehmen.
Adblocker sind auch einigen Seiten echt angenehm und bieten auch Sicherheit, aber leider ist die Grundeinstellung, dass erst einmal immer überall geblockt wird. Auch auf Seiten, die sehr zurückhaltend mit Werbung sind und nicht die ganze Seite mit Werbung vollspamen oder aufploppende Banner, die erst einmal den Bildschirm blockieren.
Erst einmal muss man den Benutzer klar machen, dass gerade Werbung blockiert wird und man als Betreiber auf diese Einnahmen doch auch angewiesen ist. Helfen wird es wohl kaum.
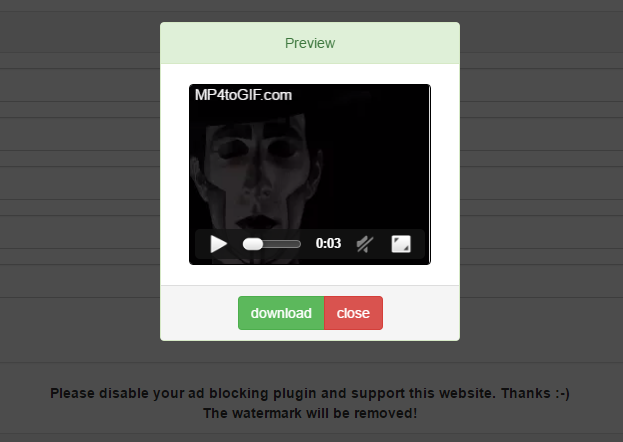
Bei MP4toGIF.com teste ich jetzt etwas neues. Ich kann natürlich für meine Seite auch gut Werbung gebrauchen. Wasserzeichen mag ich an sich gar nicht, aber sie sind doch am Ende gute Werbung. Ich würde aber nie etwas mit Wasserzeichen erzeugen und dann teilen. Weil sicher viele so denken würde keiner mehr die Webapp nutzen. Also wieder ein Verlust für mich. Nun habe ich es so angepasst, dass doch ein Wasserzeichen in das Video oder die GIF gerendert wird, ABER NUR wenn ein Adblocker aktiv ist. Um das Wasserzeichen los zu werden muss der Benutzer nur den Addblocker auf der Seite deaktivieren und die Seite einmal neuladen.
Wenn also jemand absolut keine Werbung zulassen möchte, hat er ein Wasserzeichen im Bild und macht Werbung für mich. Wenn nicht steigt meine Chance auf Einnahmen durch die Werbung. Ich finde den Ansatz an sich relativ Fair.
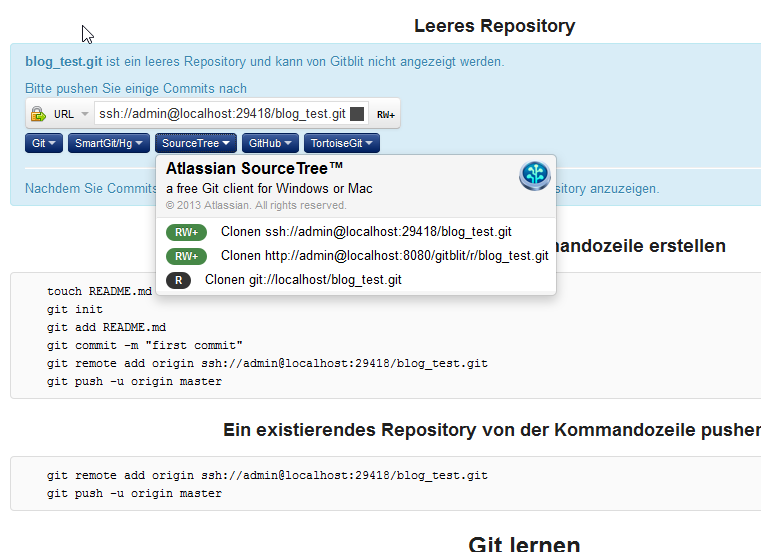
Nachdem ich feststellen musste, dass man Stash/BitBucket zwar für $10 für ein kleines Team kaufen kann, aber man dafür eine Kreditkarte benötigt, habe ich mit auf die Suche nach einer kostenlosen Alternative.
Das Problem der meisten Alternativen wie Gerrit oder Apache Allura ist doch die immer sehr aufwendige und auch umständliche Installation. Auch gerade wenn man Windows benutzt und nicht Linux. Auch hat nicht jeder Windows-Benutzer der Zuhause etwas entwickeln möchte eine Windows 2008 Server-Version. Ich hatte mir etwas vorgestellt, was ich einfach im Tomcat deployen kann als WAR und dann ist es da (vielleicht noch Einstellungen wie Speicherort und Datenbank.. aber nicht viel mehr). Die beiden genannten Systeme können
zwar sehr viel und gerade Gerrit ist wohl noch mal einen zweiten Blick wert, aber ich wollte erst einmal schnell was kleines und einfaches.
Ich habe länger gesucht und habe am Ende Gitblit gefunden. Die WAR downloaden, ins webapp Verzeichnis kopieren und den Tomcat starten... und es war da. Eingeloggt mit dem default-User und alles erschloss sich gleich.
Und mit das Beste ist die vorhandene Integration von SourceTree, die bei mir langsam war aber an sich sauber und gut funktionierte. So kann man sich auf jeden Fall für Testzwecke in wenigen Minuten einen GIT-Server einrichten.
Die Ganze IT-Nerd und auch Hacker-Kultur ist extrem durch Filme geprägt. Diese Tatsache sieht man nicht nur an der Guy Fawkes Maske von Anonymous die dem Film "V for Vendetta" entliehen wurde. Gerade die wenigen Filme, die sich mit Computern und dem Thema Hacken beschäftigt haben wurden von der Kultur regelrecht aufgesogen und wurden zu einen Teil davon. Teilweise lag es nicht an der Qualität oder dem Realismus sondern auch einfach an den Vorlieben von Trash und einer gehörigen Portion Selbstironie. Da durften Filme gerne auch mal schlecht und voller Fehler sein.. aber so lange sie ein gewisses Gefühl transportieren konnten wurden, waren es einfach "richtige" Hacker-Filme.
Und genau so einen Film will ich heute hier vorstellen bzw wieder ins Gedächtnis rufen. Dieser Film bringt schon mit seinem Titel genau darüber worum es geht.
Hackers
Hackers stammt aus dem Jahr 1995 und fällt damit in einer Zeit wo das Internet anfing die privaten Haushalte zu erobern. Man speicherte auf Disketten, die ersten Hacker wie Kevin Mitnick wurden berühmt und das Pfeifen der Modems gehörte noch zum altäglichen Leben. Der Film hat viele berühmte und gute Schauspieler wie Angelina Jolie + Nacktszene (viele viele Filme...), Jonny Lee Miller (Elementary), Matthew Lillard (Scooby Doo, Wing Commander) und als Antagonisten Fisher Stevens (Nummer 5 lebt) als The Plague, der eigentlich den ganzen Film irgendwie cool macht.
Am Anfang ist der Film ansatzweise so ewtas wie eine Teeny Highschool Komödie mit Hacker-Einschlag. Der als 11 jähriger verurteilter Hacker Dade "Zero Cool" darf mit 18 wieder Computer verwenden und zieht mit seiner Mutter nach New York. New York ist jetzt eigentlich weniger für seine Hacker Kultur bekannt... aber egal.. New York und Inliner sind einfach cool und irgendwie ist es auch egal wo der Film spielt.
Gleich in seiner ersten Hacker-Aktion seit Jahren trifft er auf den Hacker/die Hackerin "Acid Burn". Da Dade aber ja ein total 1337-Hacker ist, sucht er sich einen anderen Nickname um sich nicht zu verraten "Crash Override".. genau so cool wie die Namen ist dann die Szene wo beide in einem TV-Studio System mit Roboterarmen um eine Video-Kassette von "The Outer Limits" kämpfen. Er verliert.
Wie keiner erwarten würde .. nein natürlich nicht.. trifft er genau in seiner neuen Highscholl auf "Acid Burn". Nach dem er beim Wipeout Spielen ihren Highscore schlägt mag sie in natürlich noch weniger als vorher, obwohl niemand weiß, wer der andere ist. Er lernt "Cereal Killer" und noch paar andere Hacker kennen und da alle sagen "Der Gibson".. so etwas wie ein Cray.. wäre nicht zu Hacken, lässt sich der junge kleine unerfahrene aus der Gruppe dazu verleiten es doch zu tun. Damit beginnen deren Probleme. Ein Admin der nicht so gut ist, wie er tut.. FBI und am Ende die Vereinigung aller Hacker der Welt "Hack the Planet" sind keine neuen oder wirklich kreativen Ideen aber der Film hat etwas. Er geht einfach sehr unbekümmert mit dem Thema um und zeigt deutlich wie Spiel und Wettbewerb die eigentliche treibende Kraft der Hacker sind.
Eine Philosophie und der Wunsch die Welt zu verbessern, darf natürlich nicht fehlen.. aber hält sich doch dezent im Hintergrund.
Realistisch ist der Film nicht und will es auch nicht sein. Mac OS 8 auf einen P6 Prozessor der SOGAR einen PCI-Bus hat... ja..
Ein anderer Teil ist der Soundtrack des Films der die Zeit Mitte der 90er perfekt einfängt.
Man sollte sich den Film ansehen.. aber auf jeden Fall den nötigen Humor gleich mitbringen und nicht zu ernst an den Film heran gehen.
Die Abfragesprache für die Neo4J Graphendatenbank ist Cypher, die sich irgendwie eine Mischung aus SQL und JSON darstellt. Das Schöne an der Sprache ist, wie einfach sie zu lernen ist, weil die Struktur sehr klar ist und einfach alles so funktioniert wie man es sich denkt. Komplexe Konstrukte wie GROUP BY aus SQL gibt es nicht und die Aggregatsfunktionen fügen sich sehr viel angenehmer in alles
ein als bei SQL.
Die Grundlegende Struktur einer Abfrage ist auch sehr logisch:
* MATCH * WHERE * RETURN * ORDER BY * LIMIT
Also ich sage welches Graphen-Gebilde ich such. Dann wird festgelegt welche Eigenschaften es erfüllen soll. Das geschieht anhand der Relations und Attribute der Komponenten, die man vorher fest gelegt hat (einfache statische vorgaben wie Ids kann man sogar schon vorher fest legen wie
z.B. " (e:example{id:1})").
Nun definiert man wie das ResultSet aussehen soll. Nodes, Relations, Attribute, Ergebnisse von Aggregatsfunktionen.. kann man beliebig mischen und auch eine CASE-Anweisung ist vorhanden. Dann Legt noch die Sortierung fest und möglicher Weise eine Limitierung des Resulsets.
Besonders schön sind Funktionen wie collect(), die einem Möglichkeiten bieten, die SQL einen einfach nicht nicht bieten kann.
Gehen wir mal von einer Datenbank mit Benutzern und Gruppen aus.
SQL:
SELECT g.id group_id,
u.id user_id,
u.name user_name
FROM groups g,
users u,
users_groups ug
WHERE ug.group_id = g.id
AND u.id = ug.user_id
ORDER BY g.id
Danach müssen wir durch eine Schleife laufen und immer wenn die Group-Id
sich ändert eine neue Liste für die User aufmachen und die solange füllen
bis die nächste Liste erzeugt wird. Die listen kommen dann in eine Map
wo die Group der Key für ihre Liste ist.
Jeder hat so etwas bestimmt schon mal gemacht, um keine einzelnen Queries für jede Group absetzen zu müssen. Ein großes Query ist schneller als viele kleine, weil weniger Overhead für die Connection-Verwaltung gebraucht wird und auch weniger Objekte erzeugt werden, was immer gut für die Performance
ist.
mit Neo4j geht es sehr viel einfacher.
Cypher:
MATCH (g.group)<-[m:member]-(u:user)
RETURN
g.id as group_id,
collect(u)
ORDER BY g.id
Hiermit erhält man eine Liste aller Groups mit 2 Werten. Der erste Wert ist die Id und der zweite ist die Liste der zur Group gehörigen User. Damit ist keine zusätzliche Iteration über die Ergebnismenge mehr nötig, um solch ein Konstrukt zu erzeugen.
Wenn man nun noch die Anzahl der User pro Group direkt haben möchte
muss man das Query nur minimal anpassen. Kein GROUP BY oder ähnliches.
Cypher:
MATCH (g.group)<-[m:member]-(u:user)
RETURN
g.id as group_id,
count(u) as cnt,
collect(u)
ORDER BY g.id
Komplizierter wird es mit Befehlen wie UNWIND oder FOREACH, aber im Vergleich zu entsprechenden SQL Lösungen sind diese auch noch sehr einfach und unkompliziert.
Ein Blick über den SQL-Tellerrand lohnt auf jeden Fall, wenn man Aufwand und Zeit sparen möchte bei Abfragen, die oft geschachtelte Listen nutzen und man es Leid ist, diese aus den Resultsets wieder zu rekonstruieren.
Older posts:
Möchtest Du AdSense-Werbung erlauben und mir damit helfen die laufenden Kosten des Blogs tragen zu können?
 bezahlt von
bezahlt von