Viele erinnern sich noch an Zeiten, wo man direkt auf einem Webserver seinen HTML-Seiten und Scripts geschrieben und getestet hat. HTML ging meistens schon lokal, aber wenn es um PHP oder anderes ging brauchte man einen Server. Dann schwenkte man auf XAMPP um, wo man einen lokalen Apache nutze. Linux brachte den Apache und PHP direkt mit. Aber man hatte oft kein Linux und half sich mit VirtualPC oder VirtualBox, so man entweder eine shared Speicher hatte oder ganz klassisch per FTP oder später SCP/SSH seine Dateien aus der IDE ins Zielsystem bekam. Dann kam Docker und die Welt wurde gut.. über all gut? Nein, dann erstaunlich viele gerade im Agentur-Bereich arbeiten immer noch mit einem Server und einem FTP-Sync. Gut heute oft mit SFTP oder SCP, aber ohne Docker oder lokalen Webserver.
Während ich klassische vServer mit Apache und ohne Reverse-Proxy und Docker für veraltet halte, sind sie noch öfter Realität als Docker-/K8n-Umgebungen. Selbst shared-Hosting für produktive Umgebungen sind noch öfters anzutreffen.
Nach einem Gespräch, wo noch direkt auf dem Server gearbeitet wurde und nicht mal eine lokale IDE einen Sync in Richtung Server vornahm sondern direkt die Datei vom Server aus geöffnet wurde (da kann man fast direkt mit vi auf dem Server arbeiten...), hier eine einfache kostenlose Lösung, wo man wenigstens die Dateien lokal hat und so auch ohne Probleme mit Git arbeiten kann.
Genutzt wird VisualStudio Code (die Intellij-IDEs bringen so einen Sync direkt von Haus aus mit, kosten aber in den meisten Varianten Geld).
Ein Plugin installieren:
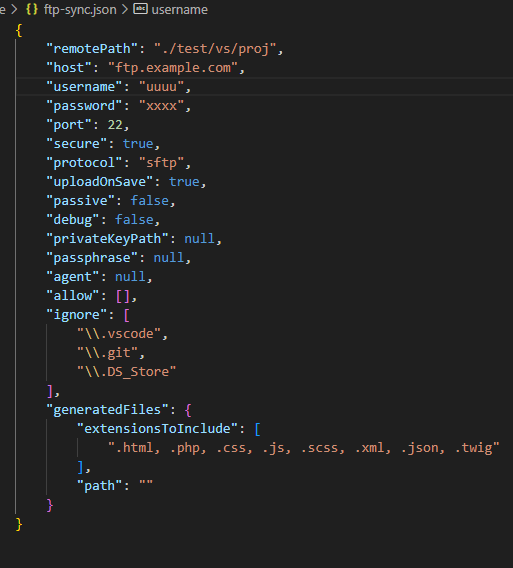
FTP-Config anlegen (wird geöffnet nach dem ersten Sync-Versuch):
Wenn uploadOnSave aktiviert ist am Besten die IDE noch mal neustarten.
Geht auf jeden Fall besser als WinSCP parallel zum Sync laufen zu lassen.
Würde ich so entwickeln wollen? Nein. Besonders wenn mehr als ein Entwickler an einem Projekt arbeiten, geht nichts über Docker. Für Shopware habe ich gute Images oder man nimmt Dockware, was gerade für Entwickler an sich vollkommen reicht.
Ich wollte nur mal kurz Magento 2 installieren (XAMPP und Windows 10 Pro). Aber das Adminpanel wollte nicht funktionieren und auch viele CSS und JS Dateien wurden nicht gefunden.
Ich habe eine Lösung aus zwei Lösungen im Internet gefunden, mit denen es am Ende dann doch alles lief.
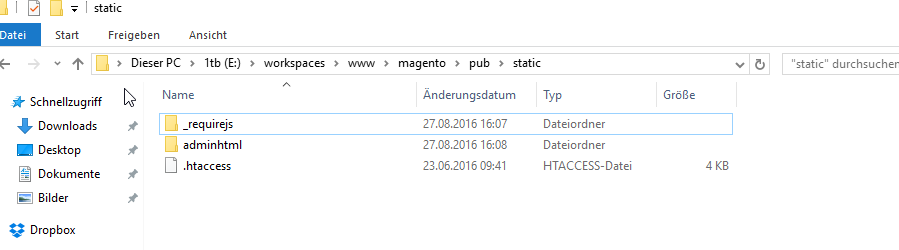
Zuerst habe ich alles bis auf die htaccess aus pub\static gelöscht.
Dann die app\etc\di.xml editiert. Die Strategie von Symbolic-Link auf Copy geändert.
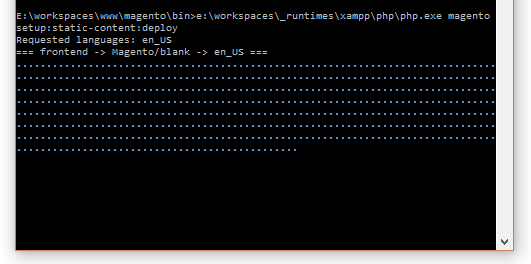
Und dann ein PHP Script ausgeführt, dass alles noch mal neu anlegt. bin\magento.
Bevor es dann wirklich mal um die Installation von PDT in Eclipse geht, wollen wir uns erst einmal eine MySQL Datenbank einrichten, damit wir auch richtige kleine Anwendungen schreiben können und nur ganz selten kommt man da ohne Datenbank aus. Auch wenn NoSQL Datenbanken wie Neo4J wirklich toll und momentan sehr in sind, bleiben wir bei einem klassischen RDBMS. Weil MySQL gerade im Web sehr verbreitet ist und sich einfach lokal einrichten lässt, bleiben wir auch bei MySQL.
Wer ein Linux benutzt, kann MySQL immer ganz einfach über den Paket-Mananger installieren. Für Windows kann man schnell zu XAMPP greifen. XAMPP enthält alles vom Apache, PHP7 und MySQL bzw MariaDB.
XAMPP funktioniert am Besten wenn man es direkt unter C:\ installiert.
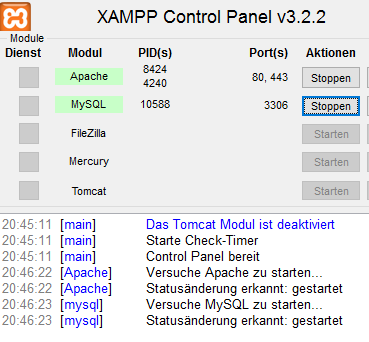
Zum Verwalten der Server-Anwendungen von XAMPP gibt es das XAMPP Control Panel. Hier müssen nur der Apache und der MySQL Server gestartet
werden.
Damit auf die Datenbank zugegriffen werden kann bringt XAMPP phpMyAdmin mit. phpMyAdmin ist eine Datenbankverwaltung die in PHP geschrieben ist und auch von den meisten Hostern angeboten wird.. wenn nicht sogar von allen. Man kann direkt über die URL http://localhost/phpmyadmin darauf zugreifen.
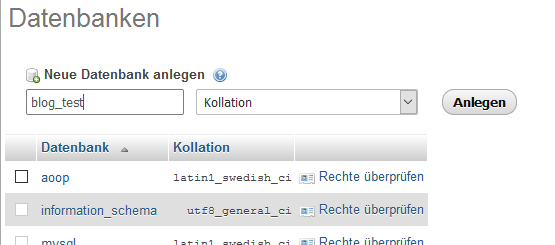
Zuerst erstellen wir eine Datenbank mit dem Namen blog_test.
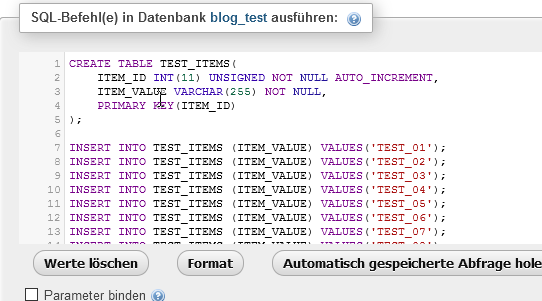
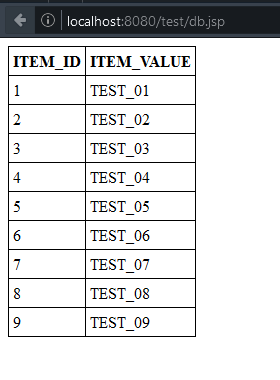
Damit wir ein paar Daten haben, legen wir uns eine Tabelle mit ein paar wenigen Daten an. Hier ist das SQL-Script dafür:
CREATE TABLE TEST_ITEMS(
ITEM_ID INT(11) UNSIGNED NOT NULL AUTO_INCREMENT,
ITEM_VALUE VARCHAR(255) NOT NULL,
PRIMARY KEY(ITEM_ID)
);
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_01');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_02');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_03');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_04');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_05');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_06');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_07');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_08');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_09');
Die IDs werden automatisch hochgezählt und müssen deswegen nicht extra angegeben werden.
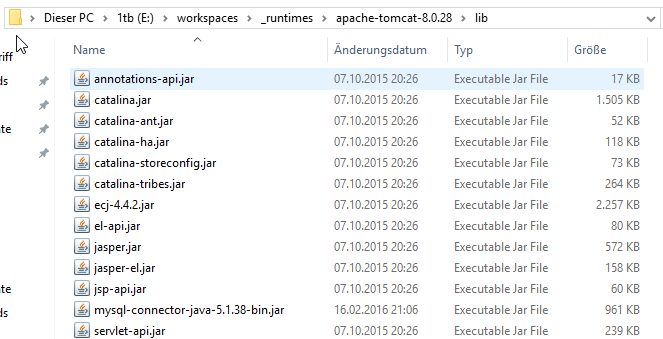
Nun gehen wir wieder in Eclipse zurück und erstellen uns eine kleine JSP mit einer Datenbankabfrage. Und hier wird es etwas komplizierter mit den verschiedenen ClassLoader des Tomcats und den verschiedenen Config-Dateien. Ich hab die einfachste aber nicht beste Variante gewählt. Die JAR-Datei mit dem JDBC-Treiber kommt direkt in das lib-Verzeichnis des Tomcat und wir passen die zentrale context.xml Datei, die uns von Eclipse zur Verfügung gestellt wird.
Die aktuelle JAR mit dem MySQL-Treiber findet man auf dev.mysql.com.
In die Context-Datei definierten wir die DataSource als Resource.
Nun können wir über JNDI uns diese DataSource in eine JSP holen. Wir erstellen eine ganz einfach Abfrage. Das Ergebnis liefert uns ein Statement in Form eines ResultSets. Ich benutzt hier die Methode über den Index die Ergebnisse zu bekommen, z.B. getString(1) wobei aber auch getString("ITEM_ID") funktioniert und für den zielgerichteten Einsatz sehr viel besser ist, weil man so das SQL-Statement ändern kann und auch die Reihenfolge der Columns ändern, ohne dabei auf den Java-Code achten zu müssen. Hier wird aber nicht zielgerichtet ein Wert ausgelesen und z.B. in ein anderes Object geschrieben sondern einfach alles ausgegeben. Deswegen auch nur getString() und keine anderen Methoden, die einen passenden Datentyp zurück liefern und ein eigenes Casten der Werte unnötig machen.
Der Vorteil die Connection über eine DataSource zu bekommen und nicht jedes mal selbst zu initiieren ist, dass die DataSource ein Pooling der Connections vornimmt und Datenbankverbindungen zur Wiederverwendung offen hält, um den Overhead für Verbindungsaufbauten zu verringern.
SQL-Abfragen direkt in einer JSP-Seite zu ist aber eine schlechte und man sollte so etwas in DAO-Klassen auslagern und in der JSP nur die Ansicht mit schon fertigen Objekten erstellen, die dann vom DAO geliefert werden.
Außerdem werden immer mehr JPA verwendet, wo die SQL-Statements automatisch erzeugt werden. Handgeschriebenes SQL ist in komplexen Fällen meistens schneller und besser, aber ORM-Frameworks erleichtern einen die Arbeit schon sehr und man sollte sich JPA auf jeden Fall einmal
ansehen, bevor man noch direkt mit JDBC und SQL arbeitet.
Im nächsten Teil geht es dann wirklich mit PHP weiter.
Möchtest Du AdSense-Werbung erlauben und mir damit helfen die laufenden Kosten des Blogs tragen zu können?
 bezahlt von
bezahlt von  Blog: Blog-entries by search-pattern/Tags:
Blog: Blog-entries by search-pattern/Tags: