Ein wirklich gutes Buch. Der Vorteil ist, dass Kapitel so geschrieben sind, dass man auch mal welche überspringen kann. Zum Beispiel das Kaptiel über Sourcecode Management Systeme wie SVN oder CVS werden heute kaum noch jemanden neues zeigen können.
Auf die Zusammenfassungen am Ende der Kaptiel und des gesamten Buches sind toll. Es gibt Listen wie es laufen sollte, wie man es verbessern kann und welche Anzeichen dafür sprechen, dass Verbesserungsbedarf besteht.
Ich fand das Kapitel über Daily-Meetings und "The List", also priorisierte Todo-Listen wirklich gut und sie gaben mir neue Denkanstöße. Ich werde mal versuchen Daily-Meetings in meinen Arbneitstag einzubringen und umzusetzten.. mal sehen was mein Chef dazu sagt :-)
Ich kann jedem Entwickler, Projektleiter und Kontakt-Person, die mit einem der beiden erst genannten für einen Kunden Kontakt halten muss empfehlen.
Denn wenn der Kunde die Probleme der Entwickler versteht und der Entwickler die Probleme der Kunden (etwas technisches zu Formulieren und Zeiten abschätzen zu können), dann kann man viele Missverständnisse schon mal vermeiden. Und dieses Buch ist einfach formuliert mit Reallife-Beispielen und könnte als neutraler Dritter zwischen beiden Seiten einen gemeinsamen Konsens vermitteln.
REST mit dem Zend Framework 2 soll ganz einfach gehen. Geht es auch. Bestimmt gibt es viele verschiedene Möglichkeiten, aber diese scheint erstmal ganz gut zu funktionieren. Den XWJSONConverter hatte ich shcon in einem vorherigen Blog-Post vorgestellt. Man kann natürlich auch JSON:encode aus dem ZF2 verwenden oder json_encode().
class IndexController extends AbstractRestfulController{
private function _getResponseWithHeader(){
$response = $this->getResponse();
$response->getHeaders()
//make can accessed by *
->addHeaderLine('Access-Control-Allow-Origin','*')
//set allow methods
->addHeaderLine('Access-Control-Allow-Methods','POST PUT DELETE GET')
//change content-type
->addHeaderLine('Content-Type', 'application/json; charset=utf-8');
Lange Zeit habe ich auch immer bei Columns von Datenbank-Tabellen immer ein Prefix verwendet. Die Tabelle TESTS hatte dann z.B. die Spalte TEST_ID. Daran ist ja auch erstmal nichts verkehrt. Probleme gab es mit Oracle und der Beschränkung auf 30 Zeichen für den Spaltennamen in einigen Fällen.
$entity->setId($data["TEST_ID"]);
Der Code oben funktioniert auch super, wenn man jedes Value "per Hand" in das Object schreibt.
Wenn wir aber nun ein automatisches Mapping über Annotationen nutzen kann es in einigen Fällen schnell umständlich werden.
Wenn wir keine Ableitung und Vererbung benutzen, ist auch hier kein Problem zu erwarten. Wenn wir aber eine Basic-Klasse verwenden, von der alle anderen Klassen ableiten, haben wir schnell ein Problem, weil wir in der Basic-Klasse in den Annotationen einen Platzhalter für den Prefix verwenden müssten. Ohne Prefix geht es hier sehr viel einfacher.
/**
* @dbcolumn=ID
*/
private $id=0;
/**
* @dbcolumn={prefix}_ID
*/
private $id=0;
Deswegen sollten Prefixe nur bei FKs verwendet werden, um ein automatisches Mapping unkompliziert nutzen zu können. Wenn man es jetzt nicht nutzt, will man es später vielleicht und kann dann jetzt schon alles so bauen, um später keine Probleme zu bekommen. Platzhalter funktionieren natürlich auch.. gehen aber zur Lasten der Performance.
Früher war es nur möglich URL zu finden, die am Anfang einer Zeile standen und die Zeile für sich allein hatten. Das war für einfache Listen vollkommen ausreichend. Nun wurde es so erweitert, dass auch URLs innerhalb eines Textes gefunden werden könnten. Man kann nun also eine *.txt-Datei laden und die Web-App versucht alle enthaltenen Links zu finden und darzustellen.
In der letzten Zeit habe ich mit CSS-Frameworks zu tun gehabt. Bootstrap, Foundation und UIKit. Mit Bootstrap hatte ich ja schon etwas länger Kontakt. Foundation jetzt so 3 Wochen und UIKit 2 Tage. Bootstrap gefällt mir von der standard Optik aber immer noch am Besten. Bei UIKit gefallen mir die mitgelieferten Icons. Foundation macht was es soll, aber sieht mir an einigen Stellen doch zu sehr nach plain-HTML aus und die Dokumentation sagt mir am wenigsten von den Dreien zu.
Aber am Ende machen doch alle drei genau das Selbe und das auch sehr ähnliche Weise. Was ich mit dem einen hinbekomme, kann ich ohne große Probleme auch mit den anderen erledigen. Oft muss man nur die CSS-Class's austauschen.
Ob man nun soviele ähnliche Frameworks braucht lasse ich mal dahin gestellt und versuche erstmal für mich heraus zu finden, welches ich nun als primäres verwenden sollte.
Viele haben ja etwas gegen die Lumias... ich mag aber mein Lumia 640.
Kamera ist gut. Der Akku hält extrem lange und raus nehmbar ist. Oberfläche lässt sich wirklich gut bedienen und ist schnell. Auch alle wichtigen Apps sind vorhanden. Endlose Versorgung mit Updates. Selbst alte Lumia 1020 bekommen immer noch alle Windows Updates.
Und im Gegensatz zu meinen alten Smartphones mit Bada 2.0 oder Firefox OS kann ich jetzt meinen Eltern auch von Unterwegs aus helfen dank des Teamviewer-Clients.
Also ich kann die Lumias nur empfehlen! (Das Lumia 1020 hat eine wirklich geniale Kamera)
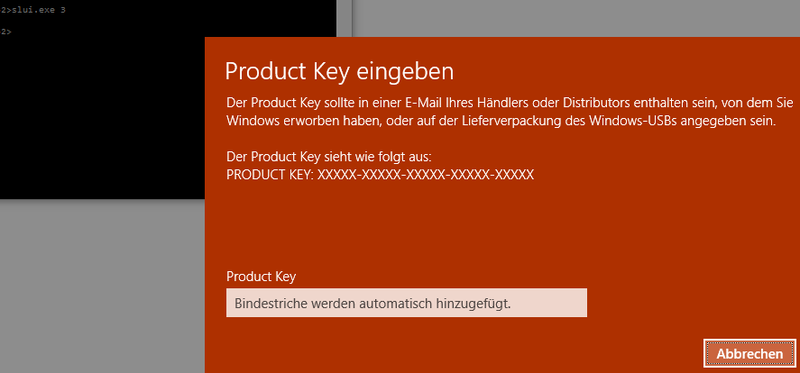
Wer erstmal eine Windows 10 Version installiert hat und erst später den Key eingeben möchte, könnte das Problem haben, dass der Button im "System"-Fenster nicht reagiert.
Dann kann das hier helfen:
slui.exe 3
Damit wird ein Fenster geöffnet in das man den Key direkt eingeben kann.
Es muss nicht immer AngularJS sein, um ein einiger Massen automatisches Databinding zu haben. Auch mit jQuery kann sich schnell kleine Lösungen basteln. Hier wir eine Liste von Items aus gegeben (<ul><li>...), die <li>'s sind per Drag and Drop sortiertbar und werden später wieder eingelesen und die Items der Reihenfolge der <li>'s entsprechend sortiert. Das wird schon ganz klassisch über die DOM-Elemente gemacht. Aber ich hatte keine Lust darauf auch die Checkboxen dannausdem <li> über das DOM zusuchen und auszulesen.
Hier zeigen sich die Vorteile von Closures mal wieder. Wenn man eine CheckBox ändert wird sofort über das onChange-Event getriggert auch das Feld des Objekts im Array angepasst. Ohne das Array oder DOM-Elemente durchlaufen zu müssen. Alles ganz automatisch.
//bind checkbox to item.visible of the current item
var func=function(item){
return function(){
item.visible=!item.visible;
}
};
check.change(func(items[j]));
Ich kann immer noch nicht verstehen, wie manche JavaScript-Entwickler ohne Closures auskommen und einige.. wenige.. ok.. einer.. sogar mal meinte Closures bräuchte man überhaupt und man komme immer gut ohne aus.
Was haben PHP und Java gemeinsam? Deren unterste Schicht der VM/Engine ist in C geschrieben. Aber was interessiert die VM oder Engine? Irgendwann kommt man an den Punkt wo man Performance-Probleme hat und dann muss man verstehen warum etwas Langsam ist. Die Frage dann sollte auch nicht lauten: "Wie bekomme ich die Anwendung schnell?" Sondern eher: "Wie habe ich sie langsam bekommen?" Denn erstmal muss man die Gründe kennen, um dann Lösungen zu finden. Lösungen sind nicht immer so einfach zu finden, weil manche Dinge sind einfach langsam und manchmal muss man sein ganzes Vorgehen ändern. Assoc-Arrays sind toll, aber es sind eigentlich keine Array sondern Hash-Maps und die sind nun mal nicht ganz so performant.
Aber warum das so ist und warum die in PHP7 viel besser implementiert sind, erschließt sich aber nicht einfach so, wenn man nicht weiß, wie die Engine arbeitet. Auch einen Garbage-Collector gibt es in PHP, der genau wie in Java zu 98% super läuft. Aber wenn er Probleme macht, muss man wissen wie er arbeitet um ansatzweise überhaupt das Problem zu verstehen. Zirkel bei Referenzen sind ein großes Problem, wenn er die Objekte zum freigeben markieren will. Reference-Count gibt es auch dort.
Jedem der sich auch für die Interna der Zend Engine 5.x und 7 interessiert und sich etwas über Performance informieren möchte kann ich diese Artikel empfehlen:
Heute bin ich über diesen Artikel bei jaxenter.de gestolpert. Da ich ja auch vor paar Monaten auf Jobsuche war, habe ich einige der im Artikel beschriebenen Dinge auch gesehen und erlebt. Da kann ich dem Autor des Artikel auch sehr Recht geben mit seinen Kritik-Punkten.
Besonders ist mir bei einigen Stellenangeboten die extreme Anzahl an sehr konkreten Technologien und Frameworks, die man alle beherrschen soll. Wenn man im Java EE gearbeitet hat, weil man dass es viele redundante Technologien gibt. So wäre heute eine konkrete Anforderung Hibernate zu beherrschen meiner Meinung nach gar nicht nötig, da sowie so am Ende JPA verwendet wird. Oder auch 5 verschieden PHP-Frameworks. Am Ende wird man nie mit all diesen Dingen auf einmal konfrontiert werden. Wenn es auch ein eine relativ kleine Firma ist, kann man fast davon ausgehen, dass auch allgemein nur Grundwissen von Nöten ist, weil man einfach nicht alle paar Tage mit einem anderen Framework arbeitet.
Bei solchen Fällen habe ich dann auch erlebt, dass einige Firmen einen Profi in allen Bereichen wollen und andere auch ganz klar erkannt haben, dass man kein Profi sein muss und auch sagen, dass vieles in alten Projekten verwendet wurde und man nur für Content-Änderungen und kleine Bugfixes ran muss. Für so etwas reichen aber bessere Erfahrungen in der Programmiersprache und ein Grundverständnis des Frameworks.
Auch die Angabe von Jahren ist immer sehr schlecht. Ich habe sehr konkrete Erfahrungen mit einem Projekt das Jahre JBoss und Hibernate als JPA-Implementierung einsetzte, aber man am Ende mit einigen Schulungen und viel Eigeninitiative in wenigen Monaten mehr richtig machte und erkannte dass man die Jahre davor mehr falsch als richtig gemacht hatte. Ich kann auch Jahre mit einem Framework arbeiten und nur die grundlegenden Dinge davon verwenden und nie auf eine moderne Version updaten. Das sind dann Fähigkeiten wo jeder nach einem Monat ist, die man eben aber über Jahre konstant gehalten hat und nie vertieft hat. 2 Monate intensiver Beschäftigung kann also mehr Wert sein, als Jahr der oberflächlichen Nutzung. Und Nutzung und richtige korrekte Nutzung einer Technologie sind auch Unterschiede.
Als jemand der einen Mitarbeiter sucht würde ich, vielleicht kommt es ja mal soweit, eher mir Dinge angucken, die der Bewerber schon mal gemacht und welche Grundlegenden Erfahrungen und Wissen er mitbringt. Ob es die eine konkrete Technologie ist, ist oft sehr egal. Ich durfte mal mit die Bewerber begutachten, die ein Projekt weiter führen sollten, an dem ich längere Zeit in der Planung und Realisierung involviert war.. aka.. ich hate das Grundsystem entwickelt.
Antworten Bewerber #1:
* "Damit konnte ich schon mal Erfahrungen sammeln" * "Das ist mir ein Begriff" * "Damit hatte ich mich schon mal beschäftigt" * "Ist mir bekannt"
Antworten Bewerber #2:
* "Wir haben mit XXX gearbeitet" * "Die Probleme hatten wir auch" * "Was tut die Lib genau? ... aha.. nein dafür hatten wir XXX" * "Da müsste ich mich noch dann einarbeiten"
Wir Entwickler waren am Ende sehr für Bewerber #2. Die Grundlagen waren da und da war es egal ob die eine konkrete Technologie schon mal benutzt worden ist. Bewerber #1 schien von allem schon mal was gehört zu haben, und hatte Erfahrungen gesammelt.. aber er hatte wie sich dann heraus stellte nie ein komplettes größeres Projekt realisieren müssen und in der Uni mal ein Cluster aus 2 App-Servern mit einem primitiven Service aufzubauen, bringt oft weniger als jemand der noch nie ein Cluster gebaut hat, aber dafür schon etwas mehr mit einem App-Server gearbeitet hat.
Das ist auch ein Tipp an Berufseinsteiger aus Uni oder so. Einfach zu geben, dass man kaum reale Erfahrung hat und dafür mehr auf die Grundkonzepte setzen, die man beherrscht. Nicht so tun als könnte man sofort alles und extrem produktiv damit umgehen, sondern einfach, zeigen was man schon kann und dann etwas darauf setzen, dass man sich schnell weiterbilden kann.
Ende der Geschichte war natürlich, dass Bewerber #1 eingestellt wurde und er lernen musste, was jeder von uns gelernt hat: In Java programmieren zu können und mit J2EE-Umgebungen zu arbeiten ist noch mal eine ganz andere Stufe, die man nicht einfach durch das betrachten kurzer Beispiele lernt.
Und auch wenn wir Entwickler für Bewerber #2 waren, das was an Bewerber #1 uns am meisten störte war, dass er versuchte so zu tun, als würde alle dieser kleinen konkreten Technologien zu beherrschen. Das war unrealistisch und man wir haben es ihm auch schnell nicht mehr geglaubt, wenn er meinte dass er auch damit mal "Kontakt hatte".
Am Ende habe ich bei meinen Bewerbungen nicht mehr darauf geachtet, möglichst viele der Punkte zu erfüllen. Ich wollte PHP oder Java, am besten im Webbereich. Ich kenne Oracle und MySQL.. also reicht es wohl für jede SQL-fähige Datenbank. Wenn mehr als ein Framework aufgezählt wurde und ich eines davon besser kannte, reichte mir es auch. Am Ende stellte sich eben heraus, dass auch der Großteil an sich irrelevant war und bei der Pflege der Altsystem es wichtiger ist eine Exception lesen zu können als das gesamte Framework zu kennen. Es gibt am Ende ja immer noch Google!
Der erste Release Candidate von PHP 7 ist verfügbar und der auch von HHVM gibt es eine neue Version. Ich würde mir beides gerne mal ansehen. Aber ich habe nicht die Zeit mir alles komplet einzurichten und mir noch extra ein Linux zu installieren. Ich benutze Windows und werde auch erstmal dabei bleiben. Also fällt leider HHVM schon mal für einen kurzen Test raus. Aber PHP7 ist für Windows verfügbar und auch Bitnami bietet schon ein WAMP-Paket mit PHP7 an. Also werde ich mir das in den nächsten Tagen mal ansehen. Einmal kurz gucken, ob aoop darauf funktioniert oder nicht. Ich bin mal gespannt.
Meine erste Reallife-Erfahrung mit dem ZF2 und Models war eine eher weniger positive. Das TableGateway braucht unbedingt den Service-Manager bzw den DB-Adapter daraus. Meine Vorgängerin hat sich dazu entschlossen eine Basis-Entität zu bauen, die wiederum von TableGateway ableitet und man so relativ einfach save() und
load()-Methoden in die Model-Klasse einbauen konnte. Der Service-Manager wurde dann durch den Constructor der Model-Klasse durch gereicht bis man den Constructor des TableGateways mit dem DB-Adapter aufrufen konnte. Auch zwischen durch wurde der Service-Manager immer mal benötigt. Weil.. man ohne ihn keine Instanz einer Model-Klasse bekommen konnte.
Um so eine Instanz zu bekommen wurde eine Factory verwendet:
/**
* By default, the ServiceManager assumes all services are shared (= single instantiation),
* but you may specify a boolean false value here to indicate a new instance should be returned.
*/
'shared' => array(
'sModel' => false
)
)
Jedes mal aber die Factory zu bemühen eine neue Instanz zu erzeugen ist nicht gerade performant und mit den ganzen Ableitungen ist es auch sehr unübersichtlich. Ich wollte einfach schnell eine Instanz einer Model-Klasse haben und nicht ein riesiges Object bekommen. Also sowas wie in POPO .. eine POJO in PHP eben.
Ein Cosntructor ohne Argumente und eine Klasse nur mit Attributen ohne Logik. Also find ich an mir zu überlegen, ob diese ganzen Ableitungen überhaupt nötig sind oder man mit der Dependency-Injection nicht was viel besseres bauen könnte.
Ich bin dann schnell zu DAOs gwechselt. Die Factory injeziert einmal den Service-Manager und kann immer die selbe Instanz des DAOs liefern. Die DTO/Model-Klasse ist schön klein und beim Befüllen in Schleifen viel schneller als eine Intanz über die Factory anfordern zu müssen.
So.. nach ich gelesen habe, dass Facebook GIFs zulassen will und man für MP4 bald zahlen muss und WebM damit vielleicht interessanter wird, habe ich MP4 to Gif mal geupdatet. Das Ergebnis wird jetzt nicht mehr in einem neuen Fenster geöffnet (was man ja immer extra bestätigen mußte, damit das Fenster geöffnet werden durfte) sondern in einem eigenen Dialog.
Vor dem Upload ist es oft wünschenwerts ein Bild drehen/rotieren zu können.
Ich hatte mich damals doch sehr damit rumgeärgert, um den richtigen Mittelpunkt bei Rotationen heraus zu bekommen.
Hier ist meine Lösung für Rotationen um 90,180,270 Grad (select oder durch Auf- und Abrunden kann man das sicher stellen,
dass keine anderen Werte eingegeben werden).
 bezahlt von
bezahlt von