Jeder der schon mal irgend etwas wie eine Teamleitung hat oder mit einer größeren Gruppe einen Konsens finden musste, weiß, dass jede Person gerade in Diskussionen besondere Eigenarten hat. Das kann sein, das jemand sich komplett aus der Diskussion verabschiedet, wenn er nicht Recht bekommt. Oder jemand sofort sagt er habe wohl sich geirrt und seine Argumente zurückzieht, wenn ein oder mehrere Gegenargumente auf den Tisch kommen. Aber auch Leute die lauter werden, um ihren Standpunkt Gewicht zu verleihen.
Alles davon kann nervig sein, aber so sind diese Personen nun mal.. es ist ihre Art. Wenn man das weiß, kann man gut damit umgehen, weil ja auch niemand dadurch angegriffen wird oder so.
Das jeder seine persönliche Art hat, ist ja auch schön. Weil auch erst so sieht man Argumente auf von verschiedenen Seiten und wenn jemand ein Argument falsch versteht, ist es auch gut zu wissen, dass man das Argument falsch verstehen kann.
Aber es gibt auch diese andere Art von Menschen und ihre Art. Die verstehen "Das ist nun mal meine Art" als eine Ausrede, warum ihr schlechtes Verhalten hinzunehmen ist. Denn sie stimmen eben dem voll und ganz zu, dass jeder nun mal seine Art habe und man das ja so hin nehmen muss. Die Person könne ja nun mal nichts für ihre Art.
Mit so einem Mensch zu diskutieren ist echt "lustig". Einige hören einen nicht zu und sobald sie ihre Position durch Argumente gefährdet sehen, kommen nur noch persönliche Angriffe. Oder Leute die einen doof anmachen, weil die es gerade nicht mochten wie man sie Angesprochen hat. Oder auch andere Leute mit vielen Schimpfworten belegen, weil die nur eben mal was anderes mögen und man dann selbst noch was abbekommt, weil man anmerkt, dass es doch gar nicht schlimm ist, eine andere Ansicht zu haben.
Wenn man dann diese Leute darauf anspricht (oder auch jemand vertrautes dieser Person) kommt oft: "Das ist nun mal meine/seine/ihre Art". Wenn man es dann eskalieren lassen will, muss man nur sagen: "Dann ändere deine Art"... ohhhh.. dann geht es los.. wie kann es wagen jemanden seine Art abzusprechen und jeder hätte en Recht so zu sein wie er ist .. bla ..bla.. bla.
Wenn mich jemand beleidigt oder scheiße behandelt und ich dann zu hören bekomme "Das ist..." .. ja.. wieder der alte Satz, dann muss man sich nicht wundern, wenn diese Person für mich gestorben und nicht mehr haltbar ist.
Ich als Teamleiter würde diese Person direkt aus dem Team entfernen. Niemand hat das Recht so mit jemanden umzugehen. Die Person darf natürlich gerne wieder kommen, wenn sie gelernt hat sich zu benehmen. Aber nicht so.
Die Art eines Menschen ordnet sich folgenden Dingen (und bestimmt noch vielen anderen Dingen mehr) unter:
- Respekt
- Benehmen
- Anstand
- Gesellschaftlichen Konventionen
- den elementaren Regeln des Zusammenlebens
Wenn ich nun keinen Respekt vor jemanden habe und meinen Anstand in einer Situation gerne mal vergessen möchte.. gerne.. aber dann muss man mit den Konsequenzen leben und nicht angekommen mit ... "Das ist nun mal meine Art".
PS: Das musste ich einfach mal aus aktuellen und privaten Anlass mir mal von der Seele schreiben :-)
Wie füllt man Kategorien in Shopware mit möglichst wenig Aufwand und weitestgehend automatisch?
Man kann könnte das im Import erledigen oder jemanden davor setzen, der alle Artikel in die entsprechenden Kategorien einsortiert. Wenn man aber nun eine neue Kategorie anlegt, müsste man durch alle Artikel gehen und gucken, ob man diese dort einsortieren muss.
Aber Product-Streams bieten hier eine tolle und einfache Lösung an. Weil hier kann man aus der Menge aller Produkte filtern. Einer Kategorie kann dann der Stream zugeordnet werden.
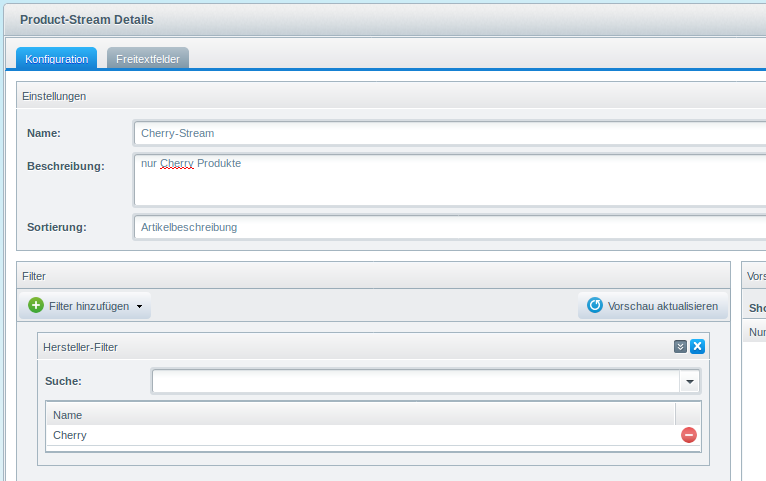
Als Beispiel nehmen wir Hersteller-Kategorien. Man will ja nicht jedes Produkt bei der Neuanlage der Kategorie zu ordnen müssen, die für den Hersteller existiert.
Wir erstellen uns einen Stream der nach unseren Hersteller filtert.
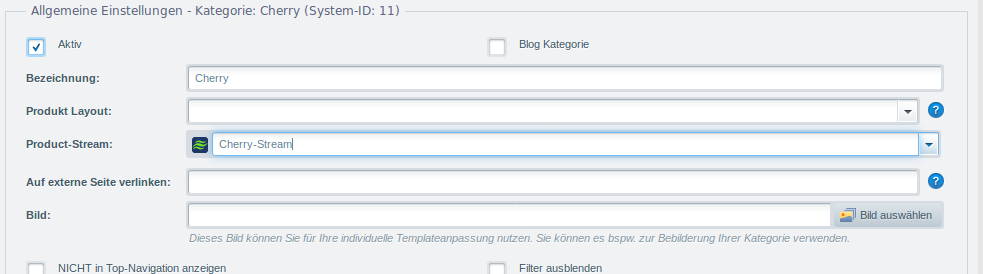
Nun erstellen wir uns eine Kategorie für den Hersteller und wählen den Stream aus.
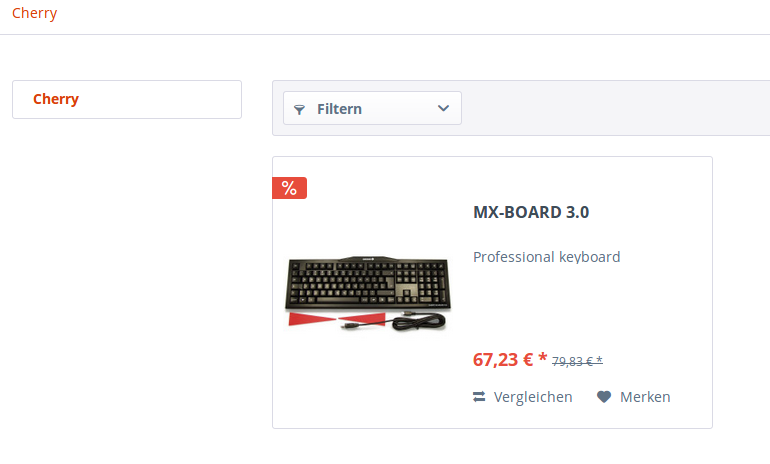
Im Frontend sind in der Kategorie nun alle Produkte des Herstellers zu finden, ohne dass wir nur einen Artikel per Hand einsortieren mussten.
Product-Streams sind sehr praktisch und nehmen einen viel Arbeit ab.
Ich hab mich die letzten Jahre doch etwas schwer getan mit JavaScript-Frameworks, die sich stärker von AngularJS unterscheiden. Knockout gefiel mir sonst auch ganz gut, auch wenn ich es ansich nie produktiv genutzt habe. Es war eben MVVC mit Templating direkt im HTML. Mein eigenes kleines Framework war auch genau so konzipiert und funktioniert bis heute gut in MP4toGIF.com.
Angular 2 sah immer interessant aus, aber irgendwie habe ich es dann doch nicht geschafft mir es mir als anzusehen. Dabei schreckte mich eher Typescript ab, was aber auch ja optional ist. Andere Sprachen und dann alles zu kompilieren mag ich bei JavaScript nicht so sehr.. da waren meine Erfahrungen mit Coffee-Script zu.. ja.. ernüchternd. Die Umgebung zum Entwickeln auf zu setzen ist vergleichbar mit dem Aufwand bei Java oder PHP. Das Debugging ist mit nativen JavaScript sehr viel einfacher gewesen.
Mit Shopware kam dann Ext JS in mein Leben. Seit Groupware und Tine 2.0 habe ich alles versucht diesem Framework aus dem Weg zu gehen. Man kommt damit zu recht, aber es ist echt nicht einfach sich dort einzuarbeiten und mal schnell eine kleine UI zu basteln, ohne sich wirklich einmal mit dem Framework auseinander zu setzen. Angular JS ist da sehr viel einfacher, aber dafür hat man eben auch nicht diese komplexe UI.
Um ehrlich zu sein, würde ich dann aber bei solchen UIs das Ext JS-Framework anderen Frameworks aus dem Desktop-Bereich wie SWT, Swing oder JavaFX vorziehen.
Heute habe ich mich mal durch die Dokumentation und die Beispiele von SAP OpenUI 5 geklickt. Es sieht etwas nach Ext JS aus, aber irgendwie spricht es mich spontan eher an. Nicht wie das erste mal mit AngularJS.. gesehen.. verstanden .. und gleich erfolgreich eingesetzt.Aber mein Gefühl war besser als bei Ext JS .. so ungefähr auf Angular 2 Niveau.
Vielleicht habe ich ja mal die Gelegenheit was damit zu machen. Momentan habe ich weder Projekt noch Zeit dafür. Aber es sieht so interessant aus, dass ich gerne was dafür hätte... gerade der Planning Calendar sieht echt gut aus.
Es begab sich gestern Abend, dass meine Frau gerne einen neuen PC haben wollte und diesmal auch gerne etwas modernes. Ich persönlich neige ja oft dazu die schon getragenen Sachen der letzten 4-5 Jahre noch mal neu aufzutragen, weil die eben günstig sind und meistens noch genug leisten, um alle Aufgaben gut bis sehr gut zu erledigen.
Mit dem Ryzen und dem Threadripper sind jetzt aber doch wieder CPUs am Markt, die wirklich gut und auch dabei durch aus bezahlbar sind.
Ein Threadripper ist trotzdem noch sehr teuer und oft braucht man diese Leistung und Anzahl an Kernen auch gar nicht. Aber es er stand zur Diskussion.
Und wie es nun mal ist, wenn man ein PC zusammenstellt, wurde die Zusammenstellung mit anderen Personen diskutiert. Als Alternative zum Threadripper nannte ich dann einen Xeon Silver mit 12 Kernen für einen leicht höheren Preis wie der Threadripper. Als Antwort kam:
Das ist eine Server-CPU, sie ist ......
Das habe ich schon so oft gehört. Aber am Ende wird es nicht wahrer, nur weil viele Leute es immer wieder herunter beten. Das kommt aber auch hauptsächlich von Leuten, die ihrer PCs noch selbst zusammen bauen und damit Komplett-Systemen so wie so so entgegen treten, dass der Hersteller da Unsinn zusammen gebaut hat. Mit dieser Aussage hebt man sich also auch über Hersteller wie HP, Lenovo, Dell, etc (wie Apple) die noch echte Workstations bauen und eben auch für entsprechende Preise an bieten (wie gerade die HP Z8).
So ein System kostet in einem besseren Ausbau gerne mal schnell 6.000-8.000 Euro und es kann noch weiter hoch gehen.
Aber wer glaubt nur Idioten, die sich ja nicht mit PCs auskennen, würden solche Systeme kaufen, liegt wohl komplet daneben. Es geht um zertifizierte Treiber und Systeme, für die Software Hersteller eine Funktionsfähigkeit ihrer Produkte Garantieren.
Solche Systeme mit Medion oder MediaMarkt Systemen zu vergleichen ist einfach realitätsfremd. Niemand der meint im Internet surfen und Emails schreiben zu wollen, würde sich eine HP Z8 kaufen. Deswegen ist auch die Annahme vieler, die Leute bei z.B. HP hätten keine Ahnung und hätten deswegen falsche CPUs verbaut, mehr als überheblich und seltsam, denn wer ein Mainboard konstruieren kann (es sind keine Komponenten von der Stange dort verbaut), wird wohl genug Fachwissen haben auch die passende CPU zu wählen.
Xeon wurden seit ihrer ersten Version (noch im Module für den Slot 2) in Workstations verwendet. Damals gab es sogar noch 4x CPU Workstation wie z.B. SGI VW 540. Die Nutzung in Workstations ist seit dem auch nicht abgebrochen, auch wenn gerne mal i7 in den kleineren Workstation Versionen verbaut werden. Aber es war nie so, dass Xeon ausschließlich für Server gebaut oder vermarktet wurden. Auch deren Feature-Set zeigt, dass zwar Server ein primäres Einsatzgebiet für Xeons sind, aber auch Workstations genau so wichtig sind. Außerdem unterscheiden sich die Anforderungen heut zu tage kaum noch zwischen Server und Desktop. Früher waren Server Multithreaded und Desktop-Anwendungen weniger.. heute ist alles so weit wie es geht Multithreaded.
Eine Ausnahme ist wohl die E7 Serie für Quad und Octa Systeme. So ein System ist aber auch nicht praktikabel als Desktop zu realisieren. Aber auch hier skaliert man heute lieber horizontal als vertikal und kauft dann lieber ein weiteres E5-System und lässt beide im Cluster laufen. Da sowie so meistens mehrere VMs darauf laufen, ist es auch egal ob diese auf dem selben Server laufen oder auf zwei Maschinen, was sogar die Ausfallgefahr reduziert.
Aber wäre weiterhin glauben will, man könne Xeons nur in Servern verbauen, beraubt sich selbst einer oft guten und manchmal auch kostengünstigen Alternative zu den Highend-Desktop CPUs wie ddem i7 oder i9. Besonders wenn man wirklich viele Dinge gleichzeitig macht, sind 2 CPUs oft besser und einfacher zu kühlen als eine einzige extrem hoch gezüchtete CPU.
Wer wirklich fast rein auf Serverbetrieb ausgelegt CPUs sehen möchte muss sich Sparc ansehen. Selbst für die Power-CPU von IBM gibt es Workstations.
Oft will man irgendwelche Aufgaben erledigen, nach dem ein Artikel gespeichert wurde. Z.B. kann es sein, dass man diesen Artikel prüfen und zu irgendwas hinzufügen möchte oder auch einfach mit dem Artikel verknüpfte andere Artikel mit updaten muss.
Es gibt ein entsprechendes Event, um auf das Speichern eines Artikel im Backend zu reagieren. Dabei wird ein allgemeines Controller-Event verwendet, wie es für jeden Controller erzeugt wird und gegen die dort aufgerufene Action geprüft.
public static function getSubscribedEvents(){
return [
'Enlight_Controller_Action_PostDispatch_Backend_Article' => 'articleRefresh',
];
}
public function articleRefresh(\Enlight_Event_EventArgs $args){
/** @var $subject \Enlight_Controller_Action */
$subject = $args->getSubject();
$request = $subject->Request();
if ($request->getActionName() === 'save') {
$params = $request->getParams();
//TODO do something
}
}
Nun fehlt noch, dass wir auch Änderungen mit bekommen, wenn ein Artikel über die REST-API geändert wird.
Der Controller ist "Articles" und das Module ist "Api". Also ist unser Event "Enlight_Controller_Action_PostDispatch_Api_Articles". Die Action ändern sich natürlich auch, weil wir bei der REST-API Actions wie PUT und POST haben.
public static function getSubscribedEvents(){
return [
'Enlight_Controller_Action_PostDispatch_Backend_Article' => 'articleRefresh',
'Enlight_Controller_Action_PostDispatch_Api_Articles' => 'articleRefresh',
];
}
public function articleRefresh(\Enlight_Event_EventArgs $args){
/** @var $subject \Enlight_Controller_Action */
$subject = $args->getSubject();
$request = $subject->Request();
if (in_array($request->getActionName(), ['save', 'put', 'post'])) {
$params = $request->getParams();
//TODO do something
}
}
Damit sollte man jede Änderung an einem Artikel mitbekommen.
Das gleiche Prinzip sollte entsprechend auch für alle anderen Controller funktionieren.
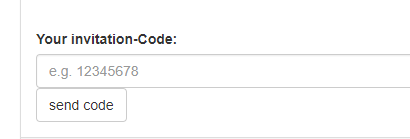
Manchmal kann es sein, dass man die Email-Adressen von allen die man einer Gruppe hinzu fügen will nicht kennt. Gerade wenn sich diese mit privaten Email-Adressen anmelden.
Nun hat man für jede Gruppe in https://www.mobile-time-tracking.com einen Einladungs-Code den man verschicken oder in Chat-Gruppen teilen kann. Wenn ein Benutzer diesen Code eingibt, wird er automatisch zur Gruppe hinzugefügt.
Nach langer Zeit.. also einigen Monaten gibt es mal wieder einen neuen Bild-Filter für MP4toGIF. Er spiegelt die linke Seite des Bildes an der Mittellinie und ersetzt damit die Rechte Seite des Bildes.
Ist an sich ein sehr alter und schon oft verwendeter Effekt des etwas von 80er Jahre Musikvideos hat. Aber er ist eben auch schön trashig und retro und machte Spaß ihn zu bauen.
Video-Material von Under Siege aka Alarmstufe Rot.. der beste Steven Seagal Film !!!!
Wenn man in Shopware den Cache geleert hat und beim Anlegen der Keywords im Frontend danach eine Exception auftritt, die in etwas so "General error: 1436 Thread stack overrun" lautet, muss man die MySQL-DB anpassen.
Dafür muss man in der my.conf den Wert für den thread_stack erhöhen.
Manchmal möchte man einfach einen kleinen Thread laufen lassen, der eine kleine Aufgabe erledigt wie z.B. ein Verzeichnis überwachen oder auf SMS-Eingänge horcht. Normal würde man so einen einfach über die CLI starten und laufen lassen. Im WildFly ist es kaum anders nur dass man die CLI-Argumente aus einer Config-Datei lesen muss.
Falls man mal das Problem hat, dass jemand zu viele fehlgeschlagene Login-Versuche beim Shopware-Backend hatte und nun gesperrt ist, muss man in die Datenbank gehen und kann dort in der Tabelle s_core_auth das Feld lockeduntil auf einen vergangenden Zeitpunkt zurück setzen.
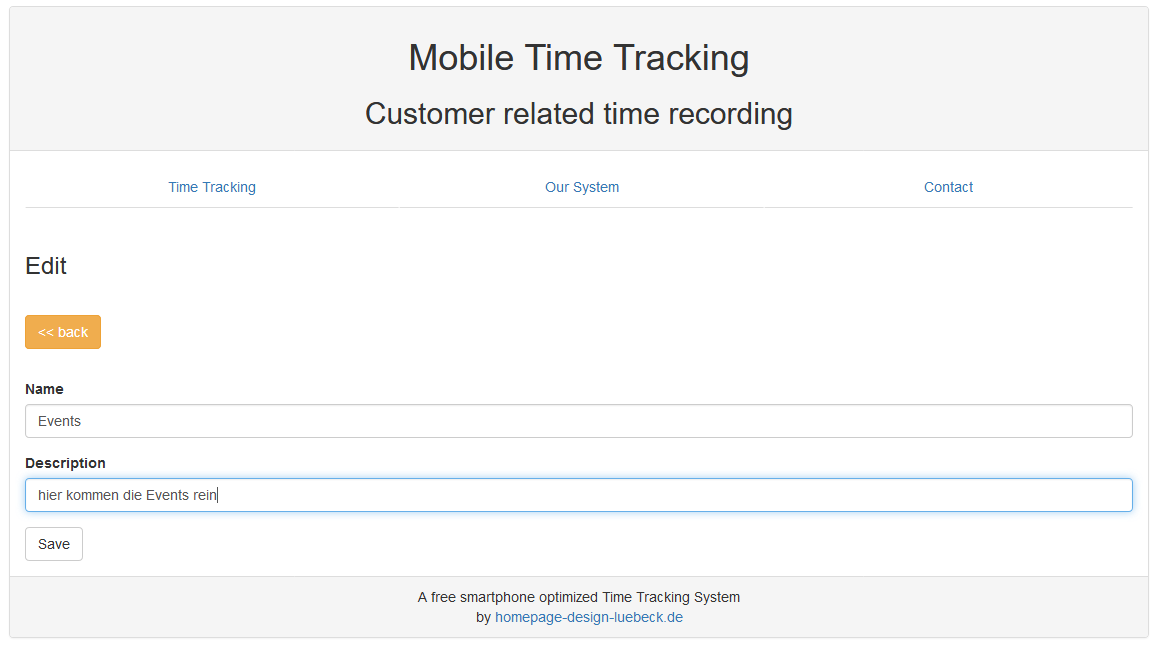
Events behandeln wir hier bei wie einen normalen Kunden. Ich werde die Übersetzung noch mal neu machen und dann wird es alles auch auf Deutsch geben und dann werde ich Events direkt mit einbringen.
Zuerst legen wir uns eine Gruppe für unsere Events an. Gruppen haben die Aufgabe ähnliche Kunden und Events zusammen und auch die Zuordnung zu den Benutzern abzubilden. Gruppen sind dafür da wenn man für verschiedene Firmen Kunden als Freelancer bedient oder für Teams und Abteilungen in einer Firma, die alle einzeln ihre Kunden und Zeiten abrechnen.
Wir legen also hier eine Gruppe „Events“ an, damit wir unseren Mitarbeitern und Aushilfen bei den Events die Möglichkeit geben Zeiten auf die Events buchen zu können.
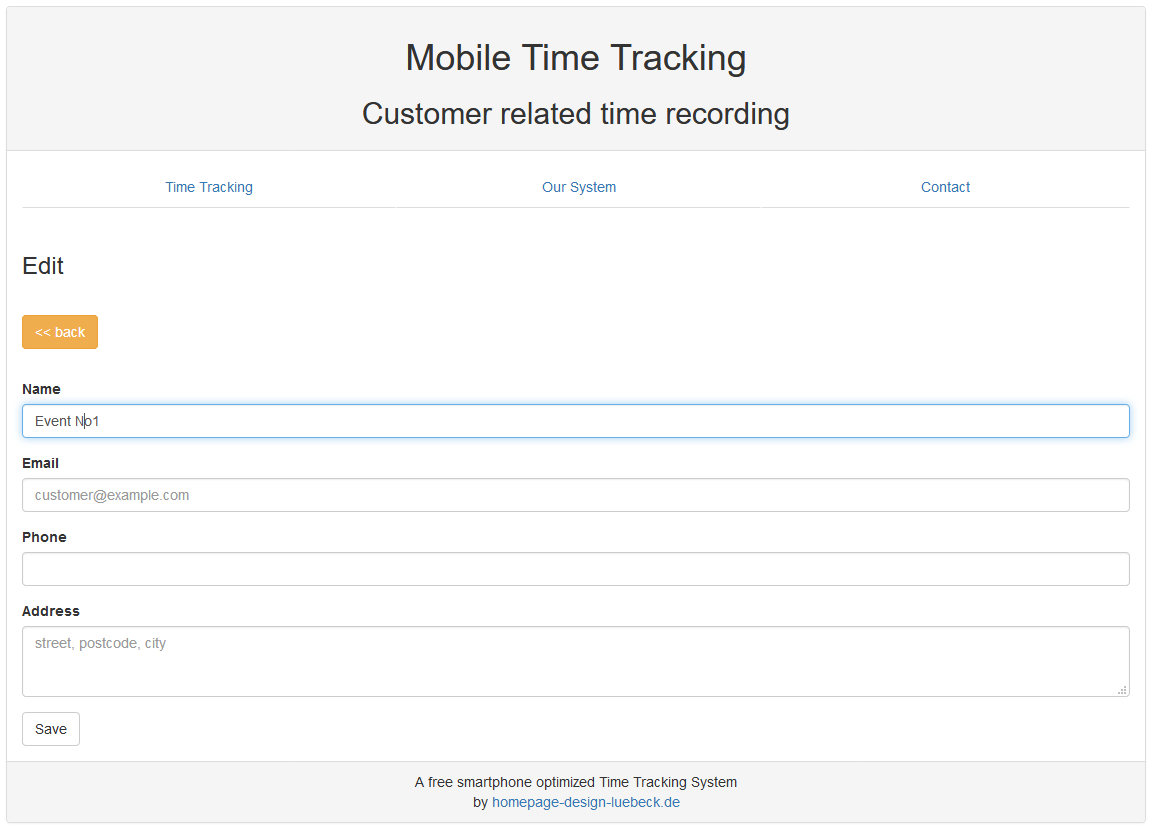
Danach kommt jetzt unser Event No1. Das legen wir direkt an. Wir brauchen dafür nur einen Namen. Kontaktinformationen werden nicht benötigt, helfen aber den Mitarbeiten um zum Kunden oder zur Event-Location zu finden oder sich dort zu melden, falls etwas etwas zu klären ist. Die OpenStreetMap-Integration ist jetzt nicht wirklich toll, aber doch eine Hilfe, um den Weg zu finden, falls man sich dort nicht auskennen sollte. Aber es ersetzt keine "echte" Navi-App.
Ich überlege gerade ob Appointments praktisch wären.. also man Termine für einen Mitarbeiter eintragen kann, so damit der Mitarbeiter weiß, wann er wo sein soll. Also etwas wie „Event No1, Appointment 17:00“. Dann weiß der Mitarbeiter, dass er um 17:00 an der Event-Location von Event No 1 sein soll.
Falls jemand das System benutzt und so etwas gerne hätte.. einfach bei mir melden und ich bauen es ein :-)
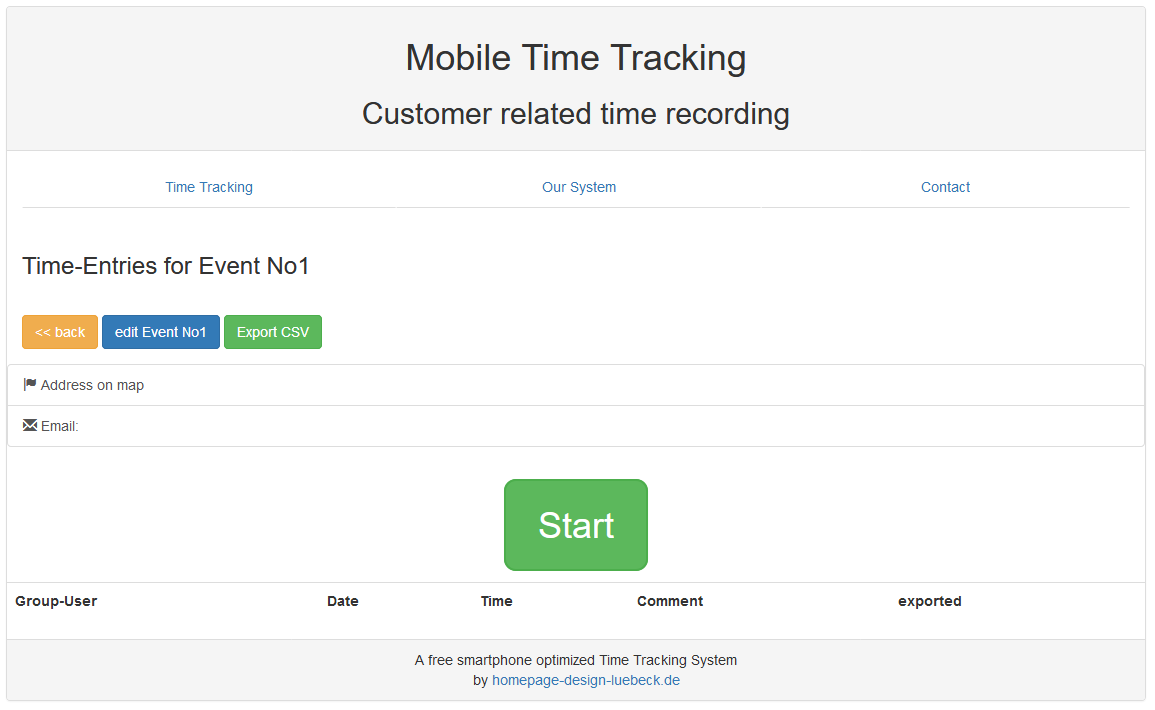
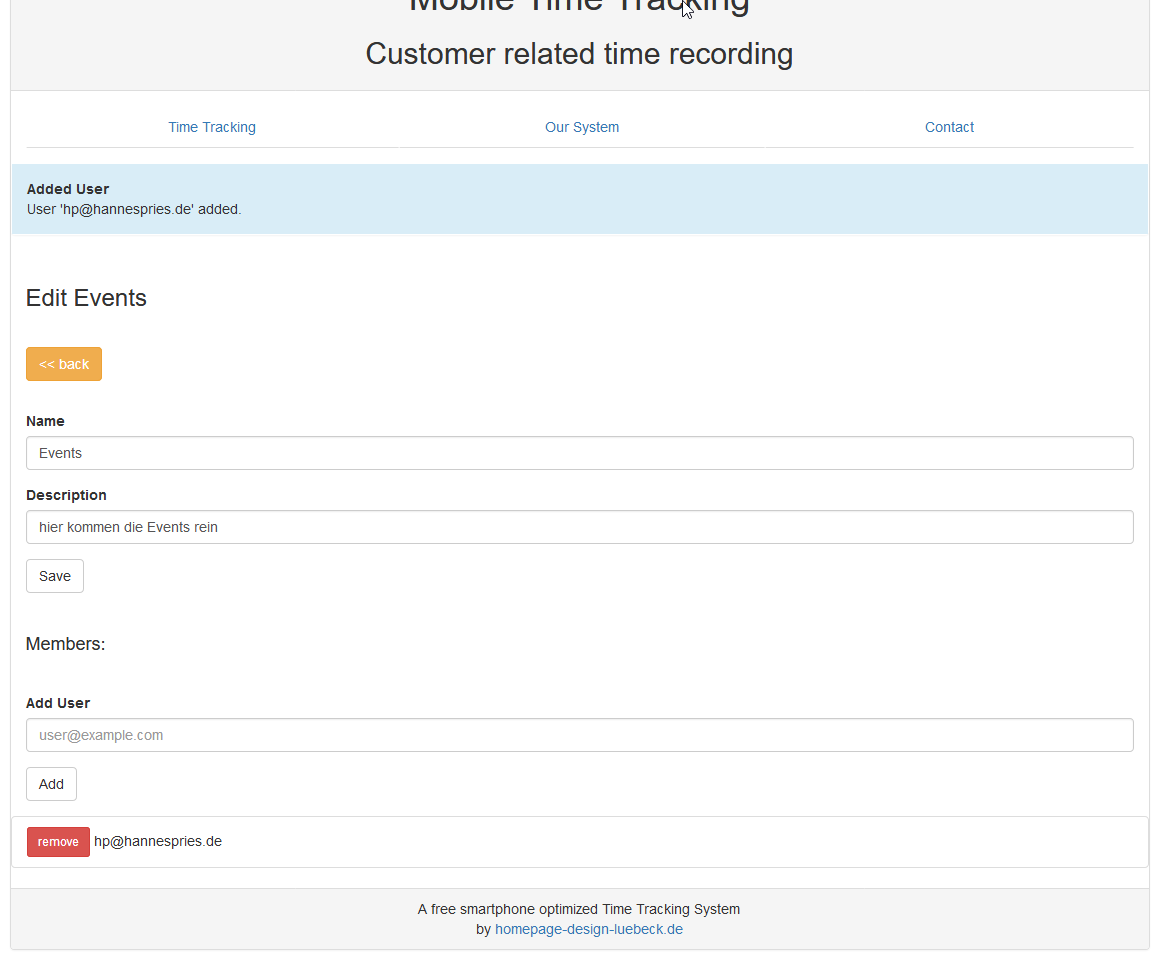
Nachdem wir unser Event No1 anlegt haben, können wir Zeiten darauf buchen. Aber wir wollen ja, dass unsere Mitarbeiter ihre Zeiten darauf buchen.
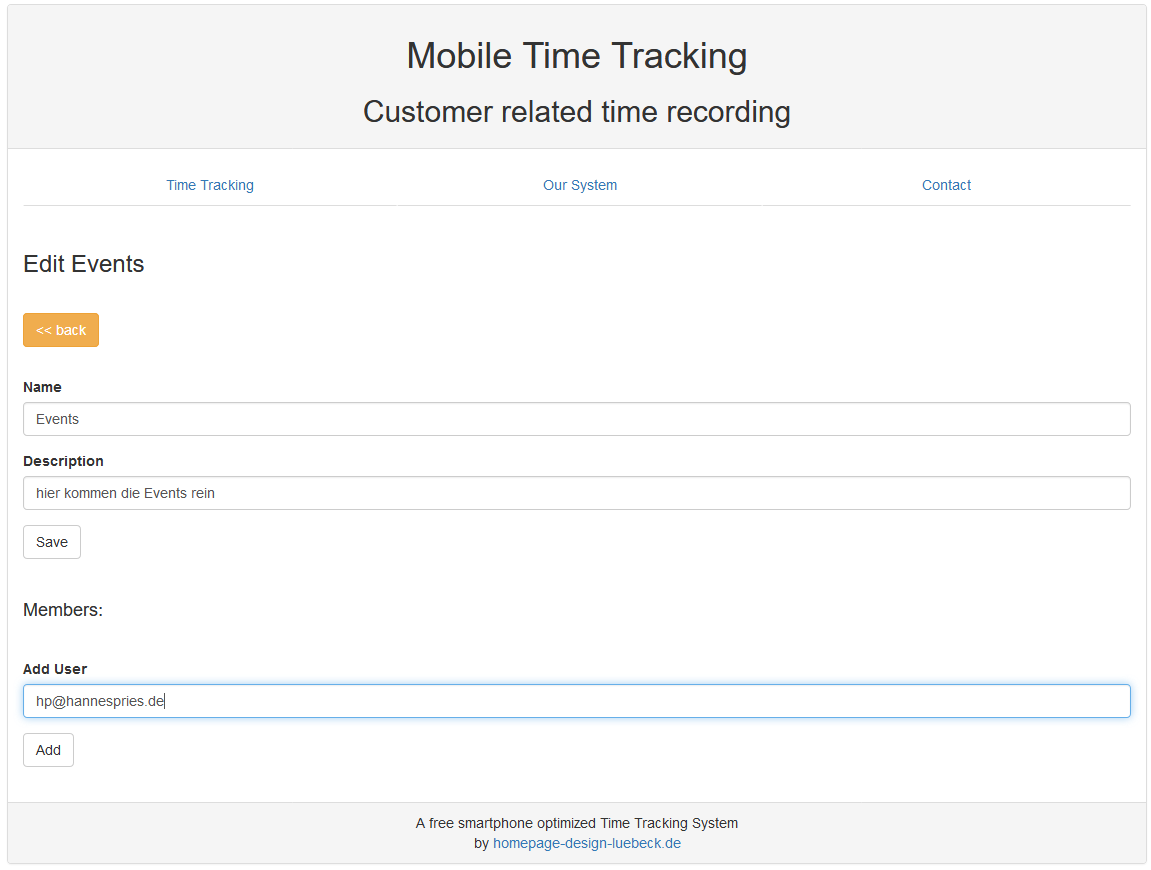
Also gehen wir "edit“ bei der Gruppe und tragen weiter unten den Benutzernamen/ die Emailadresse unseres Mitarbeiter ein. Er muss dafür bei mobile-time-tracking.com registriert sein.
Danach sieht er die Gruppe auch auf seiner Startseite und kann seine Zeiten auf die Events in der Gruppe buchen.
Wenn er also bei der Event-Location ankommt, wählt er das Event aus und drückt auf "Start“. Nachdem er dort fertig ist drückt er auf "Stop“ und geht glücklich und erschöpft nach Hause.
Der Besitzer der Gruppe darf alle Zeiten sehen. Normale Mitarbeiter (also !Besitzer) sehen nur ihre eigenen Buchungen.
Stellt euch mal ihr kauft ein Haus und alles sieht gut aus. Gute Wände, viele Steckdosen, alles sieht ganz modern aus. Aber dann nehmt ihr die Verkleidung von der Wand und ihr merkt, dass der Vorbesitzer einfach nur schöne neue Sachen ran-/vorgebaut hat und die Grundstruktur alt und schlecht ist. Anstatt beim letzten Umbau neue Kabel zu ziehen und Steckdosen zu setzen, würde einfach eine Verkleidung vor den alten Kram gesetzt und darauf dann die neuen Steckdosen verbaut.
Dass kennt man vom Entwickeln sehr gut. Wenn man einen Service in PHP 7.1 schreibt mit nullable Arguments und void return-Type und dann das Laden der Daten über mysqli geschieht und die DB-Logik nicht mal gekapselt wurde.
Also wenn man was neues baut, immer auch an den alten Code denken, der damit zusammen hängt und gerne diesen auch dann modernisieren/renovieren.
Sonst ärgert man sich später um so mehr, wenn man alles zeitlich falsch einschätzt, weil alles zu erst nachdem schönen modernen Code aussah.
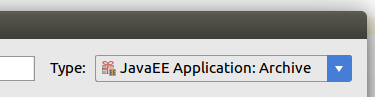
Falls es beim ersten Deployment zu einer Fehlermeldung vom JBoss/WildFly kommt, das eine Resource nicht gefunden werden könnte. Sollte man "STRG" + "SHIFT" + "ALT" + "S" drücken und dort unter Artifacts das vorhandene Artifact auf einen "Archive"-Typ ändern.
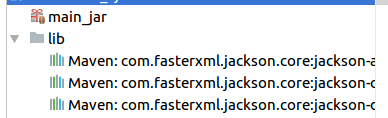
Diese Artifacts sind ganz praktisch, da man sie gut in einander verschachteln kann. Man nutzt ein Artifakt zum Bauen der Haupt-JAR und nutzt dieses Artifakt dann wieder im dem Artifakt, das man zum Bauen
der EAR nutzt.
Maven Elemente kann man einfach mit rein packen in die EAR und die entsprechenden JARs werden in der fertigen EAR abgelegt. Teilweise sehr viel einfacher als eine Standalone Anwendung über Maven zu bauen, wo auch alle Libs als JAR in eine große JAR zusammen kompiliert werden.
Ich mag EAR-Files....
und ich hatte auch etwas den Kampf mit dem JBoss/WildFly vermisst.. so etwas hat man mit PHP einfach nicht.
Ich hatte einfach keine Lust eine neue Modul-Version in meinen lokalen 10er zu basteln. Also auch wenn man seit JBoss 7 an sich Pause hatte und erst jetzt wieder mit WildFly 10 angefangen hat... es sind immer noch genau die selbe Art von Problemen die einen Ärgern.
Ich mag WildFly trotzdem :-)
Older posts:
Möchtest Du AdSense-Werbung erlauben und mir damit helfen die laufenden Kosten des Blogs tragen zu können?
 bezahlt von
bezahlt von